Úvod
ClickHouse je open source systém pro správu databází orientovaný na sloupce. Jedná se o rychlý, škálovatelný a efektivní software, který lze použít pro analýzu dat aktualizovanou v reálném čase.
Využívá méně paměti a CPU než řádkově orientované databáze, protože nemusí zpracovávat zbytečná data. Má tedy rychlou dobu odezvy na dotaz a v konečném důsledku poskytuje optimální výkon. Navíc rozumí SQL, takže je uživatelsky přívětivější.
ClickHouse je vysoce flexibilní. Tento systém správy můžete provozovat na čemkoli, od holých serverů po cloudové servery, stejně jako na jakémkoli operačním systému Linux, MacOS nebo FreeBSD.
Tato příručka vám ukáže, jak nainstalovat a začít s ClickHouse na vašem serveru CentOS 7.

Předpoklady
- Přístup k oknu terminálu/příkazovému řádku
- Server se systémem CentOS 7 s právy sudo
- Textový editor (např. Nano)
- Služba SSH pro připojení ke vzdálenému serveru
Připojte se přes SSH a aktualizujte
1. Než budete moci nainstalovat ClickHouse, musíte se přihlásit ke vzdálenému serveru CentOS.
Spusťte následující příkaz a nahraďte your_username a host_ip_address s vašimi příslušnými specifikacemi:
ssh [email protected]_ip_address2. Jakmile se připojíte k serveru, nezapomeňte aktualizovat systém spuštěním příkazu:
sudo yum updateNainstalujte ClickHouse na CentOS
1. Nejprve nainstalujte softwarové závislosti, které zahrnují pygpgme package (pro přidávání a ověřování podpisů GPG) a yum-utils (pro správu RPM zdroje):
sudo yum install -y pygpgme yum-utilshere2. Chcete-li nainstalovat nejnovější verzi ClickHouse, musíte mít přístup k úložišti YUM spravovaném poradenskou firmou ClickHouse, Altinity . Chcete však také zajistit, aby instalační balíček nepoškodil váš server.
Začněte vytvořením souboru úložiště pomocí textového editoru dle vašeho výběru (v tomto příkladu jsme použili Nano):
sudo nano /etc/yum.repos.d/altinity_clickhouse.repo3. Poté do nově vytvořeného souboru přidejte následující obsah:
[altinity_clickhouse]
name=altinity_clickhouse
baseurl=https://packagecloud.io/altinity/clickhouse/el/7/$basearch
repo_gpgcheck=1
gpgcheck=0
enabled=1
gpgkey=https://packagecloud.io/altinity/clickhouse/gpgkey
sslverify=1
sslcacert=/etc/pki/tls/certs/ca-bundle.crt
metadata_expire=300
[altinity_clickhouse-source]
name=altinity_clickhouse-source
baseurl=https://packagecloud.io/altinity/clickhouse/el/7/SRPMS
repo_gpgcheck=1
gpgcheck=0
enabled=1
gpgkey=https://packagecloud.io/altinity/clickhouse/gpgkey
sslverify=1
sslcacert=/etc/pki/tls/certs/ca-bundle.crt
metadata_expire=300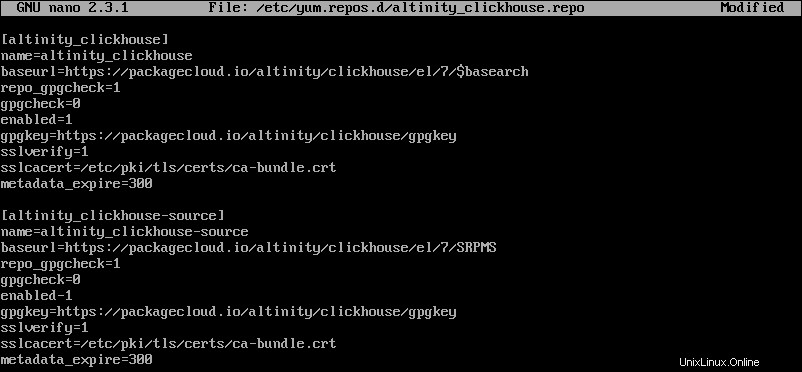
4. Uložte a zavřete soubor úložiště.
5. Dále povolte úložiště příkazem:
sudo yum -q makecache -y --disablerepo'*' --enablerepo='altinity_clickhouse'6. Jakmile výstup potvrdí, že jste přidali klíč GPG, můžete přejít k instalaci ClickHouse. Stáhněte si balíčky clickhouse-server a clickhouse-client pomocí následujícího příkazu:
sudo yum install -y clickhouse-server clickhouse-client7. Tímto jste nainstalovali ClickHouse na váš server CentOS 7.
Jak spustit službu ClickHouse
systemd service vytvořené clickhouse-server balíček je zodpovědný za spouštění, restartování a zastavování databáze.
Chcete-li začít server ClickHouse použijte příkaz:
sudo service clickhouse-server start hereTerminál by měl zobrazit následující výstup:

Zda služba běží správně, můžete také zkontrolovat pomocí:
sudo service clickhouse-server statusZpráva, kterou obdržíte, by měla být jako na obrázku níže:

Jak vytvářet databáze a tabulky
Chcete-li vytvořit databáze a tabulky, musíte nejprve spustit relaci klienta. Jakmile se výzva otevře, můžete ji použít ke spuštění příkazů SQL.
clickhouse-client --multiline
Zatímco clickhouse-client příkaz otevře novou relaci, --multiline flag umožňuje spouštět dotazy, které zabírají více řádků.
Vytvořit databázi
Databáze je v podstatě adresář pro tabulky. Syntaxe pro vytvoření databáze je:
CREATE DATABASE db_nameVýstup potvrdí vytvoření databáze zobrazením zprávy „OK. “, spolu s počtem řádků v sadě a čas vytvoření trvalo.
Chcete-li vytvořit databázi na všech serverech z clusteru , přidejte klauzuli [ON CLUSTER cluster_id] do základního syntaktu:
CREATE DATABASE db_name [ON CLUSTER cluster_id]
Chcete-li načíst data ze vzdáleného MySQL serveru do nově vytvořené databáze přidejte [ENGINE = engine(…)] klauzule, jako v následujícím příkazu:
CREATE DATABASE db_name [ENGINE = engine(…)]Vytvořte tabulku
Syntaxe pro vytvoření tabulky je:
CREATE TABLE table_name
(
column_name1 column_type [options],
column_name2 column_type [options],
) ENGINE = engine
Typ ENGINE si vyberete závisí na aplikaci. ClickHouse má svůj nativní databázový stroj, který podporuje konfigurovatelné tabulkové stroje a dialekt SQL.
Obecně jsou nejpoužívanější motory rodiny MergeTree. ClickHouse však také podporuje MySQL.
Při vytváření tabulky musíte nejprve otevřít databázi, kterou chcete upravit. Použijte následující příkaz:
ch:) USE db_nameVýstup potvrdí, že jste v zadané databázi.
Dále můžete vytvořit tabulku se všemi požadovanými sloupci (a typy sloupců). V tomto příkladu vytvoříme klienta tabulka sestávající z šesti (6) sloupců pomocí příkazu:
ch:) CREATE TABLE Client (
ch:) ClientID UInt64,
ch:) FirstName String,
ch:) LastName String,
ch:) Address String,
ch:) City String,
ch:) BirthDate DateTime
ch:) ) ENGINE = MergeTree()
ch:) PRIMARY KEY ClientID
ch:) ORDER BY ClientID;jméno a sloupec typ definovat každý sloupec. Typy sloupců v příkladu zahrnují:
- UInt64:pro ukládání celých čísel v rozsahu od 0 do 18446744073709551615
- Řetězec:pro uložení textu, který může obsahovat znaky, čísla a mezery
- Datum a čas:pro ukládání dat a času ve formátu RRRR-MM-DD HH:MM:SS
V tomto případě akumulační MOTOR je nejrobustnější tabulkový engine ClickHouse – MergeTree .
Dále PRIMERY KEY definuje, který sloupec se má použít k identifikaci všech záznamů v tabulce.
Nakonec ORDER BY klauzule umožňuje seřadit výsledky na základě definovaného sloupce.
Po vytvoření by měl výstup vypadat následovně:
CREATE TABLE Client
(
ClientID UInt64,
FirstName String,
LastName String,
Address String,
City String,
BirthDate DateTime
)
ENGINE = MergeTree()
PRIMARY KEY ClientID
ORDER BY ClientID
Ok.
0 rows in set. Elapsed: 0.010 sec.Vkládání, aktualizace a mazání dat a sloupců
Chcete-li vložit řádky v tabulce použijte následující syntaxi dotazu:
INSERT INTO table_name VALUES (column_1_value, column_2_value, ....);Pokud bychom například chtěli vložit řádky do dříve vytvořené tabulky Klient, spustili bychom následující příkaz:
TO BE ADDEDPři přidávání nových sloupců do tabulky, použijte syntaxi:
ALTER TABLE table_name ADD COLUMN column_name column_type;Pokud například chcete přidat sloupec Profese do tabulky Klient, příkaz by byl:
ALTER TABLE Client ADD COLUMN Profession String;Přidání více sloupců pomocí syntaxe:
ALTER TABLE table_name ADD COLUMN column_1 column_type, column_2 column_type, column_3 column_type;Databáze ClickHouse používají k aktualizaci a mazání nestandardní SQL dotazy, které zahrnují asynchronní dávkové operace. Následující příkazy jsou dostupné pro verze 18.12.14 nebo novější.
Syntaxe pro aktualizaci je:
ALTER TABLE table_name UPDATE column_1 = value_1, column_2 = value_2 ... WHERE filter_conditions;Syntaxe pro mazání řádků je:
ALTER TABLE table_name DELETE WHERE filter_conditions;Syntaxe pro mazání sloupců je:
ALTER TABLE table_name DROP COLUMN column_name;Odstranění tabulek a databází
Chcete-li odstranit nebo zrušit tabulku, použijte následující syntaxi:
DROP TABLE table_namePokud bychom chtěli Clintovu tabulku smazat, použijte příkaz:
DROP TABLE ClientSyntaxe pro úplné smazání databáze je:
DROP database db_nameDotaz nebo načtení dat
K načtení dat z řádků a sloupců použijte klauzuli SELECT. Základní syntaxe je:
SELECT func_1(column_1), func_2(column_2) FROM table_name WHERE filter_conditions row_options;Pokud chcete načíst jednotlivé výstupní hodnoty, které shrnují hodnoty více řádků a sloupců, můžete použít agregační funkce.
Některé příklady běžných agregačních funkcí podporovaných ClickHouse jsou:
• průměr (průměr):vypočítá průměrný objem vybraného sloupce; používá se pouze pro čísla
• počet :vypočítá počet řádků, které odpovídají zadaným kritériím
• součet (součet):vypočítá součet číselného sloupce; používá se pouze pro čísla
• jedinečné :vypočítá přibližný počet řádků odpovídajících kritériím; používá se pro čísla, řetězec a data