Úvod
MapReduce je modul zpracování v projektu Apache Hadoop. Hadoop je platforma vytvořená pro řešení velkých objemů dat pomocí sítě počítačů k ukládání a zpracování dat.
Na Hadoopu je tak atraktivní, že pro provoz clusteru stačí cenově dostupné dedikované servery. Ke zpracování vašich dat můžete použít levný spotřební hardware.
Hadoop je vysoce škálovatelný. Můžete začít s jedním počítačem a poté rozšířit svůj cluster na nekonečný počet serverů. Dvě hlavní výchozí součásti této softwarové knihovny jsou:
- MapReduce
- HDFS – Distribuovaný souborový systém Hadoop
V tomto článku budeme hovořit o prvním ze dvou modulů. Budete se naučit Co je MapReduce, jak funguje a základní terminologie Hadoop MapReduce .

Co je Hadoop MapReduce?
Programovací model Hadoop MapReduce usnadňuje zpracování velkých dat uložených na HDFS.
Díky využití zdrojů více propojených počítačů MapReduce efektivně zpracovává velké množství strukturovaných i nestrukturovaných dat .
Před Sparkem a dalšími moderními frameworky byla tato platforma jediným hráčem na poli distribuovaného zpracování velkých dat.
MapReduce přiřazuje fragmenty dat mezi uzly v clusteru Hadoop. Cílem je rozdělit datovou sadu na části a použít algoritmus ke zpracování těchto částí současně. Paralelní zpracování na více strojích výrazně zvyšuje rychlost zpracování dokonce petabajtů dat.
Distribuované aplikace pro zpracování dat
Tento framework umožňuje psaní aplikací pro distribuované zpracování dat. Většina programátorů obvykle používá Java, protože Hadoop je založen na Javě .
Aplikace MapReduce však můžete psát v jiných jazycích, jako je Ruby nebo Python. Bez ohledu na to, jaký jazyk může vývojář používat, není třeba se starat o hardware, na kterém cluster Hadoop běží.
Škálovatelnost
Infrastruktura Hadoop může využívat podnikové servery i komoditní hardware. Tvůrci MapReduce mysleli na škálovatelnost. Pokud přidáte více strojů, není třeba přepisovat aplikaci. Jednoduše změňte nastavení clusteru a MapReduce bude pokračovat v práci bez přerušení.
MapReduce je tak efektivní, že běží na stejných uzlech jako HDFS. Plánovač přiděluje úkoly uzlům, kde již data jsou. Provoz tímto způsobem zvyšuje dostupnou propustnost v clusteru.
Jak MapReduce funguje
Na vysoké úrovni MapReduce rozděluje vstupní data na fragmenty a distribuuje je mezi různé počítače.
Vstupní fragmenty se skládají z párů klíč–hodnota. Paralelní mapové úlohy zpracovávají bloková data na počítačích v clusteru. Výstup mapování pak slouží jako vstup pro redukční stupeň. Úloha redukce zkombinuje výsledek do konkrétního výstupu páru klíč–hodnota a zapíše data do HDFS.
Distribuovaný souborový systém Hadoop obvykle běží na stejné sadě počítačů jako software MapReduce. Když framework provede úlohu na uzlech, které také ukládají data, čas na dokončení úkolů se výrazně zkrátí.
Základní terminologie Hadoop MapReduce
Jak jsme zmínili výše, MapReduce je vrstva zpracování v prostředí Hadoop. MapReduce pracuje na úkolech souvisejících s prací. Cílem je vyřešit jeden velký požadavek jeho rozdělením na menší jednotky.
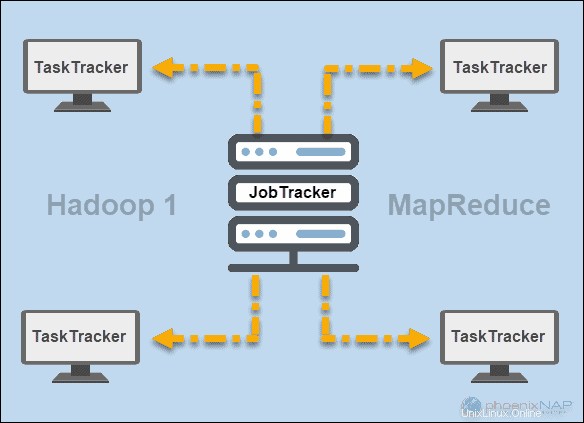
JobTracker a TaskTracker
V počátcích Hadoopu (verze 1), JobTracker a TaskTracker démoni spouštěli operace v MapReduce. V té době mohl cluster Hadoop podporovat pouze aplikace MapReduce.
JobTracker řídil distribuci požadavků aplikací na výpočetní prostředky v clusteru. Protože monitoroval provádění a stav MapReduce, byl umístěn na hlavním uzlu.
TaskTracker zpracoval požadavky, které přišly z JobTrackeru. Všechny sledovače úloh byly distribuovány napříč podřízenými uzly v clusteru Hadoop.
PŘÍZE
Později ve verzi Hadoop 2 a vyšší se YARN stal hlavním správcem zdrojů a plánování. Odtud název Ještě další správce zdrojů . Yarn také spolupracoval s dalšími frameworky pro distribuované zpracování v clusteru Hadoop.
Úloha MapReduce
Úloha MapReduce je nejvyšší jednotka práce v procesu MapReduce. Je to úkol, který musí procesy Map and Reduce dokončit. Úloha je rozdělena na menší úlohy na shluku počítačů pro rychlejší provádění.
Úkoly by měly být dostatečně velké, aby odůvodnily dobu zpracování úkolu. Pokud rozdělíte úlohu na neobvykle malé segmenty, může celkový čas na přípravu částí a vytvoření úkolů převážit čas potřebný k vytvoření skutečného výstupu úlohy.
Úloha MapReduce
Úlohy MapReduce mají dva typy úloh
Úkol na mapě je jedinou instancí aplikace MapReduce. Tyto úlohy určují, které záznamy z datového bloku se mají zpracovat. Vstupní data jsou rozdělena a analyzována paralelně na přiřazených výpočetních zdrojích v clusteru Hadoop. Tento krok úlohy MapReduce připraví výstup páru
A Snížit úkol zpracovává výstup mapové úlohy. Podobně jako ve fázi mapy se všechny úkoly snížení vyskytují současně a fungují nezávisle. Data jsou agregována a kombinována tak, aby poskytovala požadovaný výstup. Konečným výsledkem je zmenšená sada párů
Fáze Map a Reduce mají každá dvě části.
Mapa část se nejprve zabývá rozdělením vstupních dat, která jsou přiřazena k jednotlivým mapovým úkolům. Poté mapování funkce vytvoří výstup ve formě mezilehlých párů klíč-hodnota.
Možnost Snížit fáze má zamíchání a zmenšení kroku. Náhodné přehrávání vezme výstup mapy a vytvoří seznam souvisejících párů klíč-hodnota-seznam. Poté snížení agreguje výsledky míchání, aby vytvořil konečný výstup, který aplikace MapReduce požadovala.
Jak Hadoop Map and Reduce spolupracují
Jak název napovídá, MapReduce funguje tak, že vstupní data zpracovává ve dvou fázích – Map a Snížit . Abychom to demonstrovali, použijeme jednoduchý příklad s počítáním počtu výskytů slov v každém dokumentu.
Konečný výstup, který hledáme, je:Kolikrát se slova Apache, Hadoop, Class a Track objeví celkem ve všech dokumentech .
Pro ilustraci se příkladové prostředí skládá ze tří uzlů. Vstup obsahuje šest dokumentů distribuovaných napříč clusterem. Zde to bude jednoduché, ale ve skutečných podmínkách neexistuje žádné omezení. Můžete mít tisíce serverů a miliardy dokumentů.
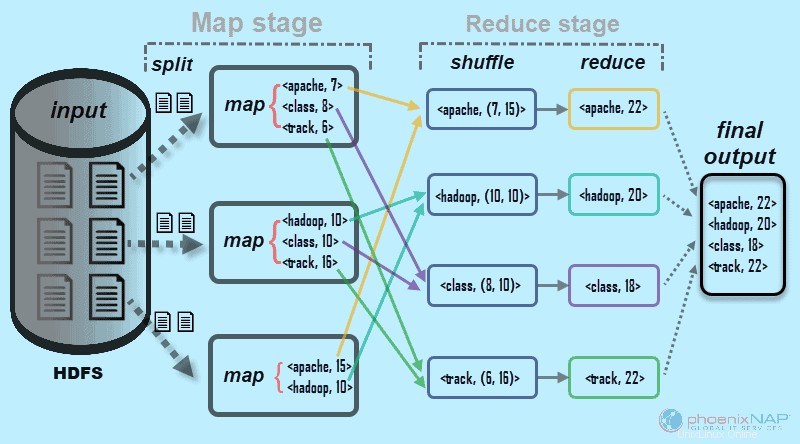
1. Nejprve ve fázi mapy , jsou vstupní data (těch šest dokumentů) rozdělena a distribuovány napříč clusterem (tři servery). V tomto případě každá mapová úloha pracuje na rozdělení obsahujícím dva dokumenty. Během mapování nedochází k žádné komunikaci mezi uzly. Vystupují nezávisle.
2. Úkoly mapy pak vytvoří
Tento proces se provádí paralelně na všech uzlech pro všechny dokumenty a poskytuje jedinečný výstup.
3. Po dokončení rozdělení vstupu a mapování se výstupy každé mapové úlohy zamíchají . Toto je první krok fáze snížení . Protože hledáme četnost výskytu pro čtyři slova, existují čtyři paralelní úlohy Reduce. Úlohy redukce mohou běžet na stejných uzlech jako úlohy mapy nebo mohou běžet na jakémkoli jiném uzlu.
Krok náhodného přehrávání zajišťuje klíče Apache, Hadoop, Class, a Sledovat jsou seřazeny pro krok snížení. Tento proces seskupuje hodnoty podle klíčů ve tvaru
4. V kroku snížení ve fázi Reduce zpracuje každá ze čtyř úloh
V našem příkladu z diagramu mají úlohy snížení následující jednotlivé výsledky:
5. Nakonec data ve fáze snížení je seskupena do jednoho výstupu. MapReduce nám nyní ukazuje, kolikrát jsou slova Apache, Hadoop, Class, asledovat se objevil ve všech dokumentech. Souhrnná data jsou ve výchozím nastavení uložena v HDFS.
Příklad, který jsme zde použili, je základní. MapReduce provádí mnohem složitější úkoly.
Některé z případů použití zahrnují:
- Přeměna protokolů Apache na hodnoty oddělené tabulátory (TSV).
- Určení počtu jedinečných IP adres v datech webového protokolu.
- Provádění komplexního statistického modelování a analýzy.
- Spouštění algoritmů strojového učení pomocí různých rámců, jako je Mahout.
Jak Hadoop oddíly mapují vstupní data
Dělič oddílů je zodpovědný za zpracování výstupu mapy. Jakmile MapReduce rozdělí data na části a přiřadí je k mapovacím úlohám, framework rozdělí data klíč-hodnota. Tento proces probíhá před vytvořením konečného výstupu úlohy mapovače.
MapReduce rozděluje a třídí výstup na základě klíče. Zde jsou všechny hodnoty pro jednotlivé klíče seskupeny a dělič vytvoří seznam obsahující hodnoty spojené s každým klíčem. Odesláním všech hodnot jednoho klíče do stejného reduktoru zajišťuje rozdělovač rovnoměrné rozdělení výstupu mapy do reduktoru.
Výchozí oddíl je dobře nakonfigurovaný pro mnoho případů použití, ale můžete překonfigurovat způsob, jakým MapReduce rozděluje data.
Pokud náhodou používáte vlastní oddíl, ujistěte se, že velikost dat připravených pro každý reduktor je zhruba stejná. Při nerovnoměrném rozdělení dat může dokončení jedné úlohy snížení trvat mnohem déle. To by zpomalilo celou úlohu MapReduce.