Úvod
Pandas je open-source Python knihovna primárně používaná pro analýzu dat. Kolekce nástrojů v balíčku Pandas je základním zdrojem pro přípravu, transformaci a agregaci dat v Pythonu.
Knihovna Pandas je založena na balíčku NumPy a je kompatibilní s širokou řadou existujících modulů. Přidání dvou nových tabulkových datových struktur, Série aDatové rámce , umožňuje uživatelům využívat funkce podobné těm v relačních databázích nebo tabulkových procesorech.
Tento článek ukazuje, jak nainstalovat Python Pandas a představuje základní příkazy Pandas.

Jak nainstalovat Python Pandas
Popularita Pythonu vyústila ve vytvoření mnoha distribucí a balíčků. Správci balíčků jsou účinné nástroje používané k automatizaci procesu instalace, správě upgradů, konfiguraci a odstraňování balíčků a závislostí Pythonu.
Poznámka: Verze Pythonu 3.6.1 nebo novější je předpokladem pro instalaci Pandas. Pomocí našeho podrobného průvodce zkontrolujte svou aktuální verzi Pythonu. Pokud nemáte požadovanou verzi Pythonu, můžete použít jeden z těchto podrobných průvodců:
- Jak nainstalovat Python 3.8 na Ubuntu 18.04 nebo Ubuntu 20.04.
- Jak nainstalovat Python 3 na Windows 10
- Jak nainstalovat nejnovější verzi Pythonu 3 na Centos 7
Nainstalujte Pandy s Anaconda
Balíček Anaconda již obsahuje knihovnu Pandas. Zkontrolujte aktuální verzi Pandy zadáním následujícího příkazu do terminálu:
conda list pandasVýstup potvrzuje verzi a sestavení Pandy.

Pokud ve vašem systému pandy nejsou, můžete také použít conda nástroj pro instalaci Pandas:
conda install pandasAnaconda spravuje celou transakci instalací kolekce modulů a závislostí.
Nainstalujte Pandy s pip
Úložiště softwaru PyPI je pravidelně spravováno a udržuje nejnovější verze softwaru založeného na Pythonu. Nainstalujte pip, správce balíčků PyPI, a použijte jej k nasazení Python pandas:
pip3 install pandasProces stahování a instalace trvá několik okamžiků.
Nainstalujte Pandas na Linux
Instalace předbaleného řešení nemusí být vždy preferovanou možností. Pandy můžete nainstalovat na jakoukoli distribuci Linuxu stejným způsobem jako u jiných modulů. Například k instalaci základního modulu Pandas na Ubuntu 20.04 použijte následující příkaz:
sudo apt install python3-pandas -y Mějte na paměti, že balíčky v linuxových repozitářích často neobsahují nejnovější dostupnou verzi.
Používání Python Pandas
Flexibilita Pythonu vám umožňuje používat Pandy v široké škále rámců. To zahrnuje základní editory kódu Python, příkazy vydávané z Python shellu vašeho terminálu, interaktivní prostředí jako Spyder, PyCharm, Atom a mnoho dalších. Praktické příklady a příkazy v tomto tutoriálu jsou prezentovány pomocí Jupyter Notebooku.
Import knihovny Python Pandas
Chcete-li analyzovat data a pracovat s nimi, musíte do prostředí Pythonu importovat knihovnu Pandas. Spusťte relaci Pythonu a importujte Pandy pomocí následujících příkazů:
import pandas as pdimport numpy as np
Import pand se považuje za osvědčený postup jako pd a numpy vědecká knihovna jako np . Tato akce vám umožňuje používat pd nebo np při psaní příkazů. Jinak by bylo nutné pokaždé zadávat celý název modulu.

Je důležité importovat knihovnu Pandas pokaždé, když spustíte nové prostředí Pythonu.
Série a datové rámce
Python Pandas používá Series a DataFrames ke strukturování dat a jejich přípravě na různé analytické akce. Tyto dvě datové struktury jsou páteří všestrannosti Pandas. Uživatelé, kteří jsou již obeznámeni s relačními databázemi, přirozeně rozumí základním konceptům a příkazům Pandas.
Série Pandy
Série představují objekt v knihovně Pandas. Dávají strukturu jednoduchým, jednorozměrným datovým sadám spárováním každého datového prvku s jedinečným štítkem. Řada se skládá ze dvou polí – hlavního pole, které obsahuje data a index pole, které obsahuje spárované štítky.
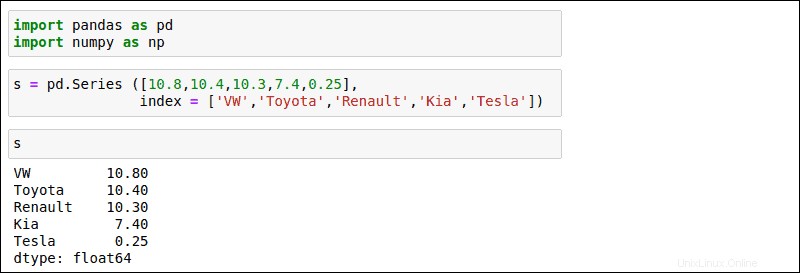
K vytvoření základní řady použijte následující příklad. V tomto příkladu Series strukturuje čísla prodejů aut indexovaná podle výrobce:
s = pd.Series([10.8,10.7,10.3,7.4,0.25],
index = ['VW','Toyota','Renault','KIA','Tesla')
Po spuštění příkazu zadejte s pro zobrazení série, kterou jste právě vytvořili. Ve výsledku jsou uvedeni výrobci podle pořadí, v jakém byli zadáni.
Na řadách můžete provádět sadu složitých a různorodých funkcí, včetně matematických funkcí, manipulace s daty a aritmetických operací mezi řadami. Úplný seznam parametrů, atributů a metod Pandas je k dispozici na oficiální stránce Pandas.
Datové rámce Pandas
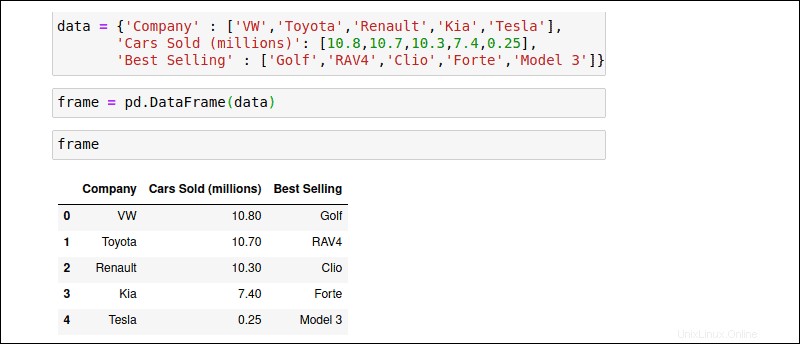
DataFrame zavádí nový rozměr do datové struktury Series. Kromě indexového pole poskytuje DataFrames strukturu podobnou tabulce přísně uspořádaná sada sloupců. Každý sloupec může ukládat jiný datový typ. Zkuste ručně vytvořit diktát objekt s názvem ‚data‘ se stejnými údaji o prodeji aut:
data = { 'Company' : ['VW','Toyota','Renault','KIA','Tesla'],
'Cars Sold (millions)' : [10.8,10.7,10.3,7.4,0.25],
'Best Selling Model' : ['Golf','RAV4','Clio','Forte','Model 3']}
Předejte objekt ‚data‘ do pd.DataFrame() konstruktor:
frame = pd.DataFrame(data)
Použijte název DataFrame, frame , pro spuštění objektu:
frameVýsledný DataFrame formátuje hodnoty do řádků a sloupců.
Struktura DataFrame vám umožňuje vybírat a filtrovat hodnoty na základě sloupců a řádků, přiřazovat nové hodnoty a transponovat data. Stejně jako u Series poskytuje oficiální stránka Pandas úplný seznam parametrů, atributů a metod DataFrame.
Čtení a psaní s pandami
Prostřednictvím Series a DataFrames zavádějí Pandas sadu funkcí, které uživatelům umožňují importovat textové soubory, složité binární formáty a informace uložené v databázích. Syntaxe pro čtení a zápis dat v Pandas je přímočará:
pd.read_filetype = (filename or path)– importovat data z jiných formátů do Pandas.df.to_filetype = (filename or path)– exportovat data z Pandas do jiných formátů.
Mezi nejběžnější formáty patří CSV , XLXS , JSON , HTML, a SQL .
| Přečíst | Napište |
|---|---|
| pd.read_csv (‚název souboru.csv‘) | df.to_csv (‚název souboru nebo cesta‘) |
| pd.read_excel (‚název souboru.xlsx‘) | df.to_excel („název souboru nebo cesta“) |
| pd.read_json (‚název souboru.json‘) | df.to_json („název souboru nebo cesta“) |
| pd.read_html (‚název souboru.htm‘) | df.to_html („název souboru nebo cesta“) |
| pd.read_sql (‚název tabulky‘) | df.to_sql („název DB“) |
V tomto příkladu nz_population Soubor CSV obsahuje údaje o populaci Nového Zélandu za posledních 10 let. Importujte soubor CSV pomocí do knihovny Pandas pomocí následujícího příkazu:
pop_df = pd.read_csv('nz_population.csv')Uživatelé mohou volně definovat název pro DataFrame (pop_df ). Zadejte název nově vytvořeného DataFrame pro zobrazení datového pole:
pop_df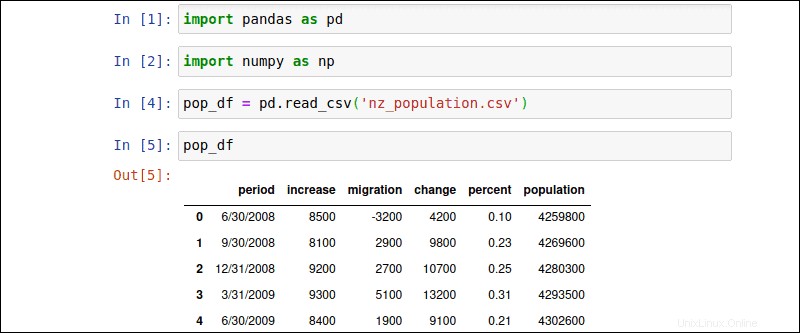
Běžné příkazy Pandas
Jakmile importujete soubor do knihovny Pandas, můžete použít sadu jednoduchých příkazů k prozkoumání a manipulaci s datovými sadami.
Základní příkazy DataFrame
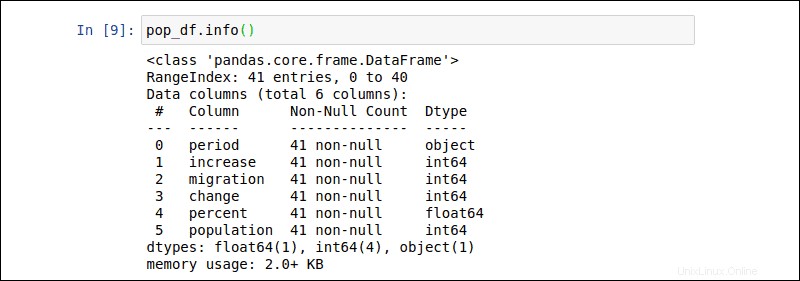
Chcete-li získat přehled pop_df, zadejte následující příkaz DataFrame z předchozího příkladu:
pop_df.info()Výstup poskytuje počet položek, název každého sloupce, datové typy a velikost souboru.
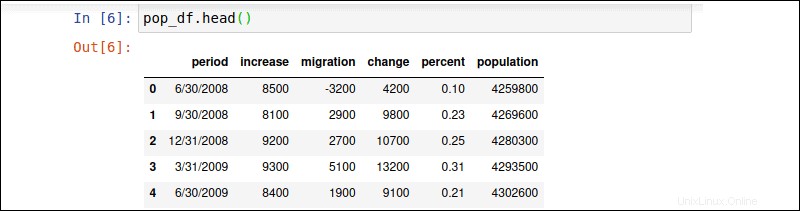
Použijte pop_df.head() k zobrazení prvních 5 řádků DataFrame.
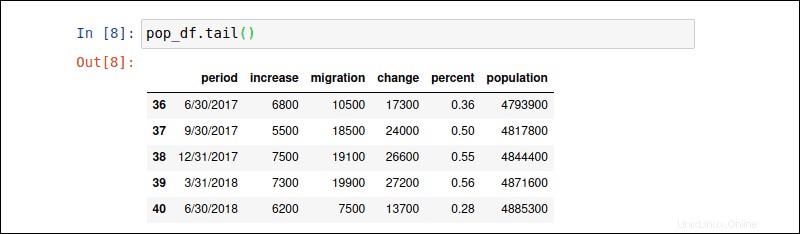
Zadejte pop_df.tail() příkaz k zobrazení posledních 5 řádků pop_df DataFrame.
Vyberte konkrétní řádky a sloupce pomocí jejich názvů a iloc atribut. Vyberte jeden sloupec pomocí jeho názvu v hranatých závorkách:
pop_df['population']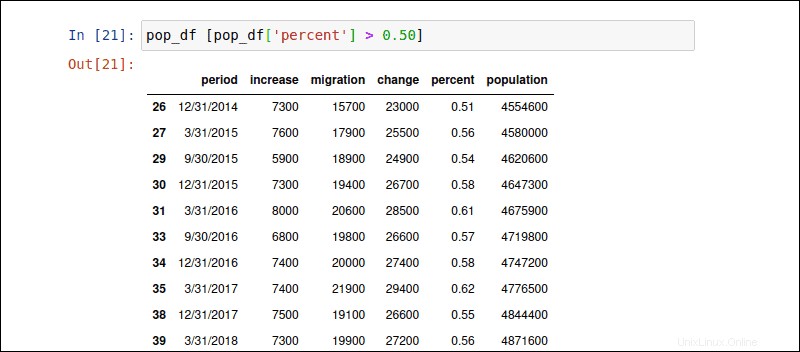
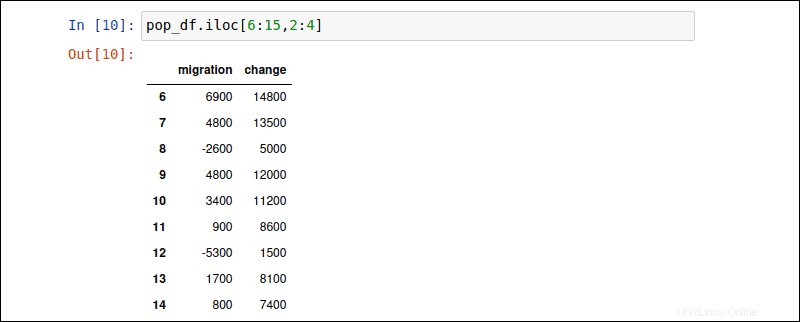
iloc atribut umožňuje načíst podmnožinu řádků a sloupců. Řádky jsou uvedeny před čárkou a sloupce za čárkou. Následující příkaz načte data z řádků 6 až 16 a sloupců 2 až 4:
pop_df.iloc [6:15,2:4]
Dvojtečka : nařídí Pandám, aby zobrazily celou zadanou podmnožinu.
Podmíněné výrazy
Řádky můžete vybrat na základě podmíněného výrazu. Podmínka je definována v hranatých závorkách [] . Následující příkaz filtruje řádky, kde je hodnota sloupce „procent“ větší než 0,50 procenta.
pop_df [pop_df['percent'] > 0.50]Agregace dat
Pomocí funkcí vypočítat hodnoty z celého pole a vytvořit jediný výsledek. Hranaté závorky [] také umožňují uživatelům vybrat jeden sloupec a přeměnit jej na DataFrame. Následující příkaz vytvoří nový total_migration DataFrame z migrace sloupec v pop_df :
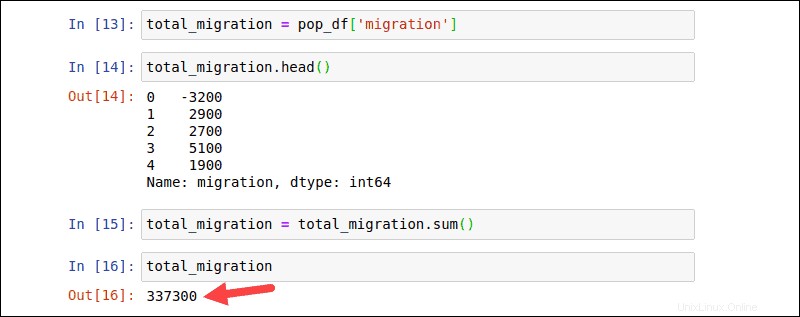
total_migration = pop_df['migration']Ověřte data kontrolou prvních 5 řádků:
total_migration.head()
Vypočítejte čistou migraci na Nový Zéland pomocí df.sum() funkce:
total_migration = total_migration.sum()total_migrationVýstup vytvoří jediný výsledek, který představuje celkový součet hodnot v total_migration DataFrame.
Některé z běžnějších agregačních funkcí zahrnují:
df.mean()– Vypočítejte průměr hodnot.df.median()– Vypočítejte medián hodnot.df.describe()– Poskytuje statistické shrnutí.df.min()/df.max()– Minimální a maximální hodnoty v datové sadě.df.idxmin()/df.idxmax()– Minimální a maximální hodnoty indexu.
Tyto základní funkce představují pouze malý zlomek dostupných akcí a operací, které Pandas nabízí.