Úvod
Spark Streaming je doplněk k Spark API pro živé vysílání a zpracování rozsáhlých dat. Místo toho, aby se Spark Streaming zabýval velkým množstvím nestrukturovaných nezpracovaných dat a uklízel po nich, provádí zpracování a sběr dat téměř v reálném čase.
Tento článek vysvětluje, co je Spark Streaming, jak funguje, a poskytuje příklad použití streamování dat.

Předpoklady
- Apache Spark nainstalovaný a nakonfigurovaný (postupujte podle našich průvodců:Jak nainstalovat Spark na Ubuntu, Jak nainstalovat Spark na Windows 10)
- Prostředí nastavené pro Spark (použijeme Pyspark v noteboocích Jupyter).
- Datový stream (budeme používat Twitter API).
- Knihovny Pythonu tweepy , json a zásuvka pro streamování dat z Twitteru (k jejich instalaci použijte pip).
Co je to Spark Streaming?
Spark Streaming je knihovna Spark pro zpracování téměř souvislých toků dat. Jádrem abstrakce je Diskretizovaný stream vytvořené rozhraním Spark DStream API k rozdělení dat do dávek. DStream API je poháněno Spark RDD (odolné distribuované datové sady), což umožňuje bezproblémovou integraci s dalšími moduly Apache Spark, jako jsou Spark SQL a MLlib.
Firmy využívají sílu Spark Streaming v mnoha různých případech použití:
- Živý přenos ETL – Čištění a kombinování dat před uložením.
- Neustálé učení – Neustálá aktualizace modelů strojového učení o nové informace.
- Spouštění při událostech – Detekce anomálií v reálném čase.
- Obohacení dat – Přidání statistických informací k datům před uložením.
- Složité relace v přímém přenosu – Seskupování aktivity uživatele pro analýzu.
Přístup streamování umožňuje rychlejší analýzu chování zákazníků, rychlejší systémy doporučení a detekci podvodů v reálném čase. Pro inženýry je jakýkoli druh senzorové anomálie ze zařízení IoT viditelný při shromažďování dat.
Aspekty Spark Streaming
Spark Streaming nativně podporuje jak dávkové, tak streamovací pracovní zátěže, což poskytuje vzrušující vylepšení datových zdrojů. Tento jedinečný aspekt splňuje následující požadavky moderních systémů pro streamování dat:
- Dynamické vyvážení zátěže. Vzhledem k tomu, že se data rozdělují do mikrodávek, již není problém s úzkým hrdlem. Tradiční architektura zpracovává jeden záznam po druhém, a jakmile přijde výpočetně náročný oddíl, zablokuje všechna ostatní data na tomto uzlu. S Spark Streaming se úkoly rozdělují mezi pracovníky, někteří zpracovávají déle a někteří zpracovávají kratší úkoly v závislosti na dostupných zdrojích.
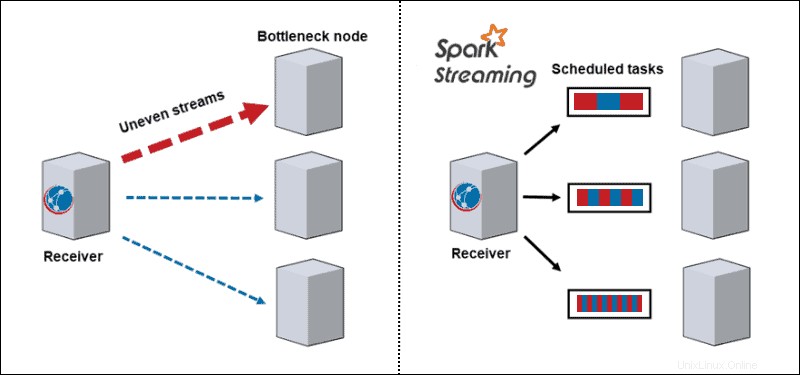
- Obnovení po selhání. Neúspěšné úkoly na jednom uzlu diskretizují a rozdělují mezi ostatní pracovníky. Zatímco pracovní uzly provádějí výpočty, opozdilec má čas se zotavit.
- Interaktivní analytika. DStreams je řada RDD. Dávky streamovaných dat uložených v pracovní paměti interaktivně dotazují.
- Pokročilé analýzy. RDD generované DStreams se převádějí na DataFrames, které se dotazují pomocí SQL a rozšiřují se do knihoven, jako je MLlib, aby vytvořily modely strojového učení a aplikovaly je na streamovaná data.
- Vylepšený výkon streamu. Streamování v dávkách zvyšuje propustnost a využívá latence pouhých několika set milisekund.
Výhody a nevýhody Spark Streaming
Každá technologie, včetně Spark Streaming, má výhody a nevýhody:
| Výhody | Nevýhody |
| Vynikající rychlostní výkon pro složité úkoly | Velká spotřeba paměti |
| Tolerance chyb | Obtížné na používání, ladění a učení |
| Snadná implementace v cloudových clusterech | Není dobře zdokumentováno a výukové zdroje jsou vzácné |
| Podpora více jazyků | Špatná vizualizace dat |
| Integrace pro rámce velkých dat, jako je Cassandra a MongoDB | Pomalé s malým množstvím dat |
| Možnost připojit se k více typům databází | Málo algoritmů strojového učení |
Jak Spark Streaming funguje?
Spark Streaming se zabývá rozsáhlou a komplexní analýzou téměř v reálném čase. Zpracování distribuovaného toku prochází třemi kroky:
1. Přijmout streamování dat ze zdrojů živého vysílání.
2. Zpracovat data na clusteru paralelně.
3. Výstup zpracovávaná data do systémů.
Architektura Spark Streaming
Základní architektura Spark Streaming je v diskretizovaném streamování dávek. Namísto procházení procesu zpracování toku po jednom záznamu jsou mikrodávky dynamicky přiřazovány a zpracovávány. Proto se data předávají pracovníkům na základě dostupných zdrojů a lokality.
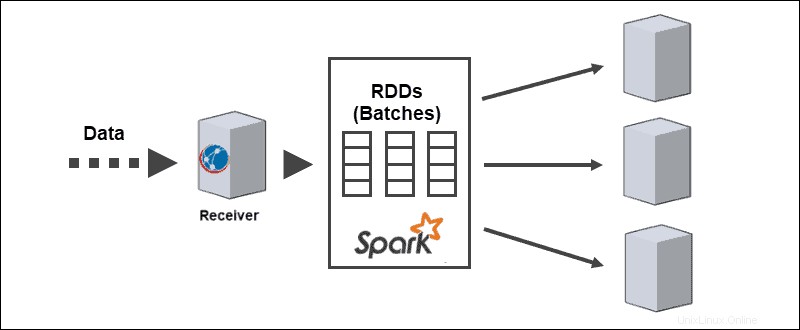
Když data dorazí, přijímač je rozdělí na oddíly RDD. Konverze na RDD umožňuje zpracování dávek pomocí kódů a knihoven Spark, protože RDD jsou základní abstrakcí datových sad Spark.
Zdroje streamování Spark
Datové toky vyžadují data přijatá ze zdrojů. Spark streaming rozděluje tyto zdroje do dvou kategorií:
- Základní zdroje. Zdroje přímo dostupné v rozhraní Streaming Core API, jako jsou připojení soketů a systémy souborů kompatibilní s HDFS
- Pokročilé zdroje. Zdroje vyžadují propojovací závislosti a nejsou dostupné v rozhraní Streaming Core API, jako je Kafka nebo Kinesis.
Každý vstup DStream se připojuje k přijímači. Pro paralelní toky dat vytváří vícenásobné Dstreamy také více přijímačů.
Operace Spark Streaming
Spark Streaming zahrnuje provádění různých druhů operací:
1. Transformační operace upravit přijímaná data ze vstupních Dstreams, podobně jako u RDD. Transformační operace se líně vyhodnocují a neprovádějí se, dokud data nedosáhnou výstupu.
2. Výstupní operace přesuňte DSstreams do externích systémů, jako jsou databáze nebo systémy souborů. Přechod na externí systémy spouští transformační operace.
3. Operace DataFrame a SQL dochází při převodu RDD na DataFrames a jejich registraci jako dočasných tabulek pro provádění dotazů.
4. Operace MLlib se používají k provádění algoritmů strojového učení, včetně:
- Algoritmy streamování platí pro živá data, jako je streaming lineární regrese nebo streaming k-means.
- Algoritmy offline pro naučení modelu offline s historickými daty a použití algoritmu na streamování dat online.
Příklad Spark Streaming
Příklad streamování má následující strukturu:
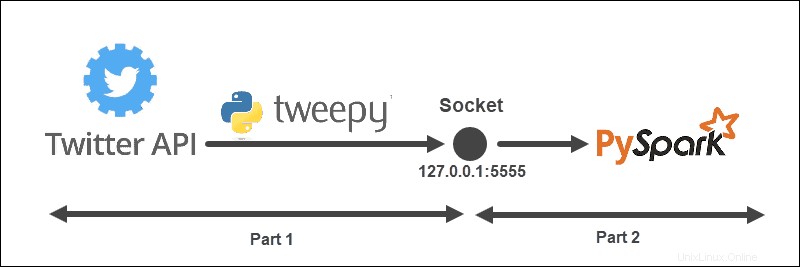
Architektura je rozdělena na dvě části a běží ze dvou souborů:
- Spusťte první soubor k navázání spojení s Twitter API a vytvoření soketu mezi Twitter API a Spark. Udržujte soubor spuštěný.
- Spusťte druhý soubor k vyžádání a zahájení streamování dat tiskem zpracovaných tweetů do konzole. Nezpracovaná odeslaná data se vytisknou v prvním souboru.
Vytvořte objekt posluchače Twitter
TweetListener objekt naslouchá tweetům ze streamu Twitter pomocí StreamListener od tweepy . Když je na soketu odeslán požadavek na server (místní), TweetListener naslouchá datům a extrahuje informace tweetu (text tweetu). Pokud je k dispozici rozšířený objekt Tweet, TweetListener načte rozšířený pole, jinak text pole je načteno. Nakonec posluchač přidá __end na konci každého tweetu. Tento krok nám později pomůže filtrovat datový tok ve Sparku.
import tweepy
import json
from tweepy.streaming import StreamListener
class TweetListener(StreamListener):
# tweet object listens for the tweets
def __init__(self, csocket):
self.client_socket = csocket
def on_data(self, data):
try:
# Load data
msg = json.loads(data)
# Read extended Tweet if available
if "extended_tweet" in msg:
# Add "__end" at the end of each Tweet
self.client_socket\
.send(str(msg['extended_tweet']['full_text']+" __end")\
.encode('utf-8'))
print(msg['extended_tweet']['full_text'])
# Else read Tweet text
else:
# Add "__end" at the end of each Tweet
self.client_socket\
.send(str(msg['text']+"__end")\
.encode('utf-8'))
print(msg['text'])
return True
except BaseException as e:
print("error on_data: %s" % str(e))
return True
def on_error(self, status):
print(status)
return TruePokud se v připojení vyskytnou nějaké chyby, konzola informace vytiskne.
Shromážděte přihlašovací údaje vývojáře Twitter
Twitter Portál pro vývojáře obsahuje přihlašovací údaje OAuth pro navázání připojení API s Twitterem. Informace jsou v aplikaci Klíče a tokeny kartu.
Pro sběr dat:
1. Vygenerujte klíč a tajný klíč API naleznete v Spotřebitelských klíčích části projektu a uložte informace:
Spotřebitelské klíče ověřte na Twitteru svou identitu, například uživatelské jméno.
2. Vygenerujte Access Token &Secret z Autentizačních tokenů a uložte informace:
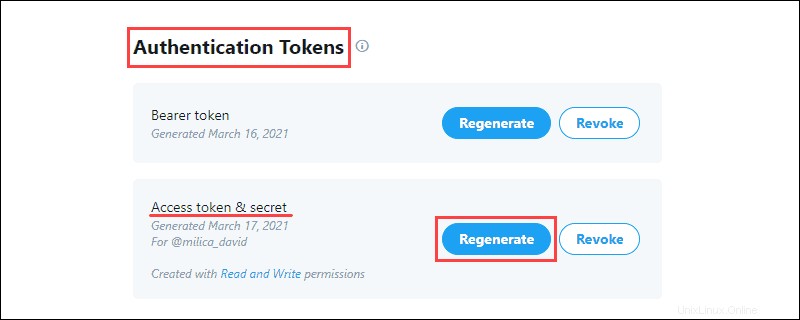
Ověřovací tokeny umožňují stahování konkrétních dat z Twitteru.
Odesílání dat z Twitter API do Socketu
Pomocí přihlašovacích údajů vývojáře vyplňte API_KEY , API_SECRET , ACCESS_TOKEN a ACCESS_SECRET pro přístup k Twitter API.
Funkce sendData spustí stream Twitteru, když klient zadá požadavek. Požadavek na stream je nejprve ověřen, poté je vytvořen objekt posluchače a datový proud se filtruje na základě klíčového slova a jazyka.
Například:
from tweepy import Stream
from tweepy import OAuthHandler
API_KEY = "api_key"
API_SECRET = "api_secret"
ACCESS_TOKEN = "access_token"
ACCESS_SECRET = "access_secret"
def sendData(c_socket, keyword):
print("Start sending data from Twitter to socket")
# Authentication based on the developer credentials from twitter
auth = OAuthHandler(API_KEY, API_SECRET)
auth.set_access_token(ACCESS_TOKEN, ACCESS_SECRET)
# Send data from the Stream API
twitter_stream = Stream(auth, TweetListener(c_socket))
# Filter by keyword and language
twitter_stream.filter(track = keyword, languages=["en"])Vytvoření naslouchacího TCP Socketu na serveru
Poslední část prvního souboru obsahuje vytvoření naslouchajícího soketu na lokálním serveru. Adresa a port jsou svázány a naslouchají připojení z klienta Spark.
Například:
import socket
if __name__ == "__main__":
# Create listening socket on server (local)
s = socket.socket()
# Host address and port
host = "127.0.0.1"
port = 5555
s.bind((host, port))
print("Socket is established")
# Server listens for connections
s.listen(4)
print("Socket is listening")
# Return the socket and the address of the client
c_socket, addr = s.accept()
print("Received request from: " + str(addr))
# Send data to client via socket for selected keyword
sendData(c_socket, keyword = ['covid'])
Jakmile klient Spark zadá požadavek, soket a adresa klienta se vytisknou na konzoli. Poté je datový tok odeslán klientovi na základě vybraného filtru klíčových slov.
Tento krok uzavírá kód v prvním souboru. Jeho spuštěním se vytisknou následující informace:

Ponechte soubor spuštěný a pokračujte k vytvoření klienta Spark.
Vytvořte přijímač Spark DSream
V jiném souboru vytvořte kontext Spark a kontext místního streamování s dávkovými intervaly jedné sekundy. Klient čte z názvu hostitele a portu portu.
import findspark
findspark.init()
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
sc = SparkContext(appName="tweetStream")
# Create a local StreamingContext with batch interval of 1 second
ssc = StreamingContext(sc, 1)
# Create a DStream that conencts to hostname:port
lines = ssc.socketTextStream("127.0.0.1", 5555)Předběžné zpracování dat
Předzpracování RDD zahrnuje rozdělení přijatých řádků dat v místě __end a změní text na malá písmena. Prvních deset prvků se vytiskne na konzolu.
# Split Tweets
words = lines.flatMap(lambda s: s.lower().split("__end"))
# Print the first ten elements of each DStream RDD to the console
words.pprint()Po spuštění kódu se nic neděje, protože vyhodnocení je líné. Výpočet začíná, když začíná kontext streamování.
Spustit kontext a výpočet streamování
Spuštění kontextu streamování odešle požadavek hostiteli. Hostitel odešle shromážděná data z Twitteru zpět klientovi Spark a klient data předzpracuje. Konzole pak vytiskne výsledek.
# Start computing
ssc.start()
# Wait for termination
ssc.awaitTermination()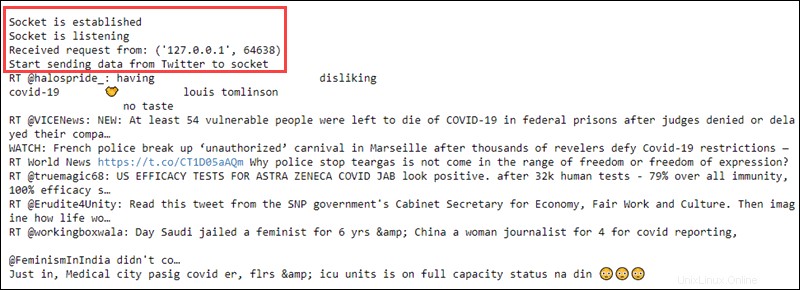
Spuštění kontextu streamování vytiskne do prvního souboru přijatý požadavek a streamuje text nezpracovaných dat:
Druhý soubor čte data každou sekundu ze soketu a na data se vztahuje předběžné zpracování. Prvních pár řádků je prázdných, dokud se spojení nenaváže:
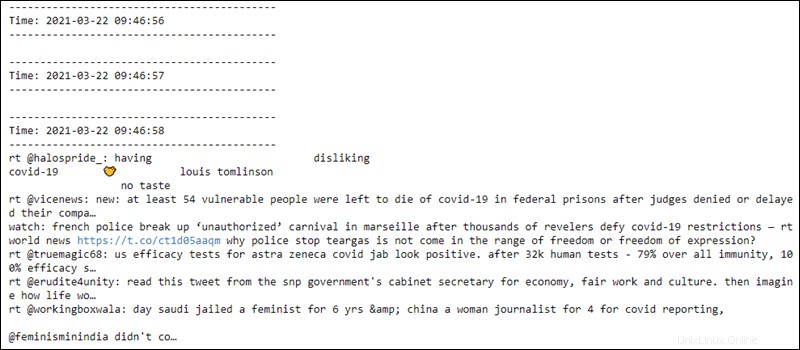
Kontext streamování je připraven k ukončení kdykoli.