Úvod
Apache Hive je systém podnikového datového skladu používaný k dotazování, správě a analýze dat uložených v systému souborů Hadoop Distributed File System.
Hive Query Language (HiveQL) usnadňuje dotazy v prostředí příkazového řádku Hive. Hadoop může používat HiveQL jako most pro komunikaci se systémy pro správu relačních databází a provádění úloh založených na příkazech podobných SQL.
Tento jednoduchý průvodce vám ukáže, jak nainstalovat Apache Hive na Ubuntu 20.04 .

Předpoklady
Apache Hive je založen na Hadoop a vyžaduje plně funkční rámec Hadoop.
Nainstalujte Apache Hive na Ubuntu
Chcete-li nakonfigurovat Apache Hive, musíte si nejprve stáhnout a rozbalit Hive. Poté je třeba upravit následující soubory a nastavení:
- Upravit .bashrc soubor
- Upravte hive-config.sh soubor
- Vytvořte Adresáře podregistru v HDFS
- Nakonfigurujte hive-site.xml soubor
- Spusťte databázi Derby
Krok 1:Stažení a rozbalení Hive
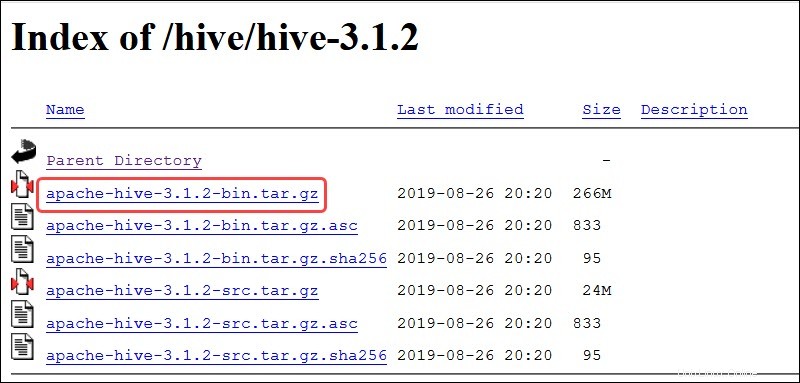
Navštivte oficiální stránku stahování Apache Hive a zjistěte, která verze Hive je pro vaši edici Hadoop nejvhodnější. Jakmile zjistíte, kterou verzi potřebujete, vyberte možnost Stáhnout vydání! možnost.
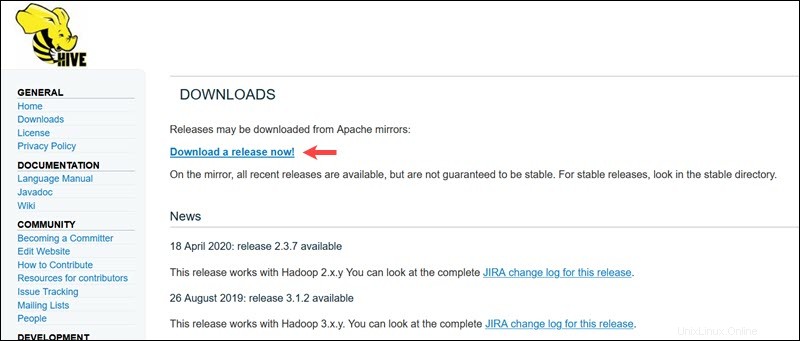
Zrcadlový odkaz na následující stránce vede do adresářů obsahujících dostupné balíčky Hive tar. Tato stránka také poskytuje užitečné pokyny, jak ověřit integritu souborů načtených ze zrcadlových webů.
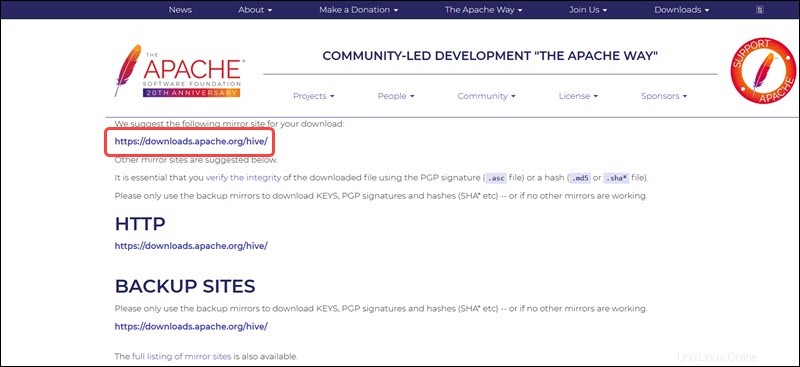
Systém Ubuntu uvedený v této příručce již má Hadoop 3.2.1 nainstalováno. Tato verze Hadoop je kompatibilní s Hive 3.1.2 uvolnit.
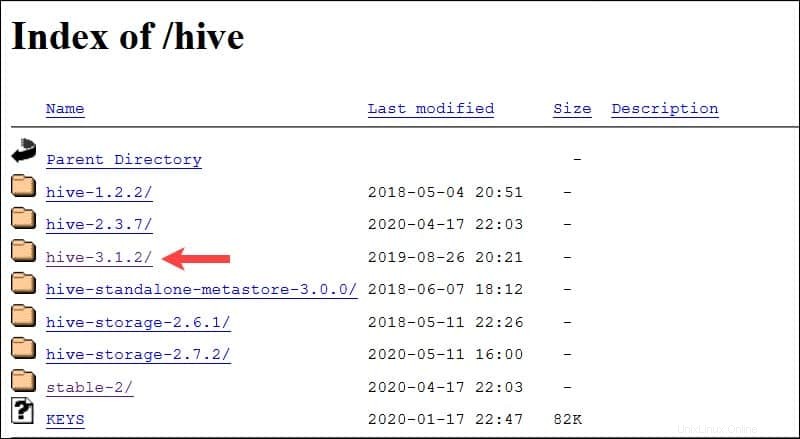
Vyberte souborapache-hive-3.1.2-bin.tar.gz zahájíte proces stahování.
Případně otevřete příkazový řádek Ubuntu a stáhněte si komprimované soubory Hive pomocí a wget příkaz následovaný cestou ke stažení:
wget https://downloads.apache.org/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz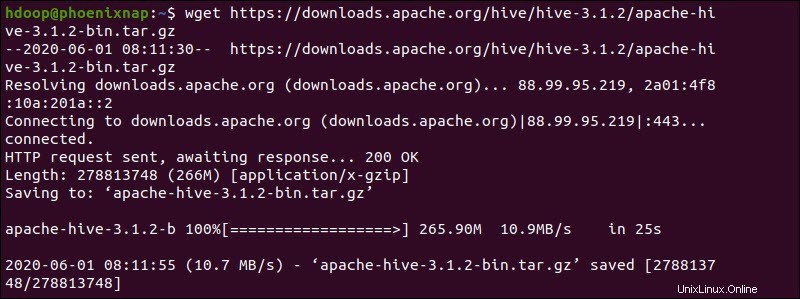
Po dokončení procesu stahování rozbalte komprimovaný balíček Hive:
tar xzf apache-hive-3.1.2-bin.tar.gzBinární soubory Hive jsou nyní umístěny v apache-hive-3.1.2-bin adresář.

Krok 2:Konfigurace proměnných prostředí podregistru (bashrc)
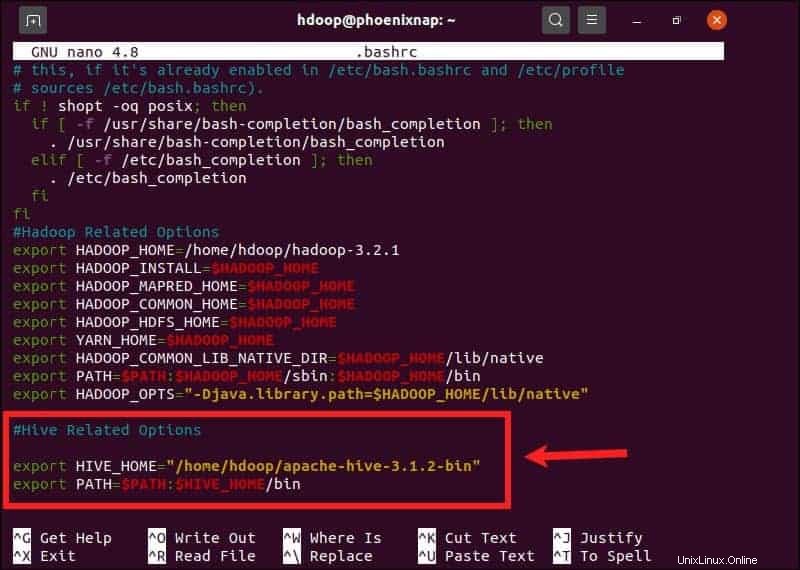
$HIVE_HOME proměnná prostředí musí nasměrovat klientský shell do apache-hive-3.1.2-bin adresář. Upravte soubor .bashrc konfigurační soubor shellu pomocí textového editoru dle vašeho výběru (my budeme používat nano):
sudo nano .bashrcPřipojte následující proměnné prostředí Hive k souboru .bashrc soubor:
export HIVE_HOME= "home/hdoop/apache-hive-3.1.2-bin"
export PATH=$PATH:$HIVE_HOME/binProměnné prostředí Hadoop jsou umístěny ve stejném souboru.
Uložte a ukončete soubor .bashrc Jakmile přidáte proměnné Hive. Aplikujte změny na aktuální prostředí pomocí následujícího příkazu:
source ~/.bashrcKrok 3:Upravte soubor hive-config.sh
Apache Hive musí být schopen komunikovat s Hadoop Distributed File System. Přejděte na hive-config.sh pomocí dříve vytvořeného $HIVE_HOME proměnná:
sudo nano $HIVE_HOME/bin/hive-config.sh
Přidejte HADOOP_HOME proměnnou a úplnou cestu k vašemu adresáři Hadoop:
export HADOOP_HOME=/home/hdoop/hadoop-3.2.1
Uložte úpravy a ukončete hive-config.sh soubor.
Krok 4:Vytvořte podregistrové adresáře v HDFS
Vytvořte dva samostatné adresáře pro ukládání dat ve vrstvě HDFS:
- Dočasný, tmp adresář bude ukládat mezivýsledky procesů Hive.
- sklad adresář bude ukládat tabulky související s Hive.
Vytvořit adresář tmp
Vytvořte tmp adresář ve vrstvě úložiště HDFS. Tento adresář bude ukládat zprostředkující data, která Hive odešle do HDFS:
hdfs dfs -mkdir /tmpPřidejte oprávnění k zápisu a spouštění členům skupiny tmp:
hdfs dfs -chmod g+w /tmpZkontrolujte, zda byla oprávnění přidána správně:
hdfs dfs -ls /Výstup potvrzuje, že uživatelé nyní mají oprávnění k zápisu a spouštění.

Vytvořit adresář skladu
Vytvořte sklad adresář v /user/hive/ nadřazený adresář:
hdfs dfs -mkdir -p /user/hive/warehousePřidat zápis a provést oprávnění ke skladu členové skupiny:
hdfs dfs -chmod g+w /user/hive/warehouseZkontrolujte, zda byla oprávnění přidána správně:
hdfs dfs -ls /user/hiveVýstup potvrzuje, že uživatelé nyní mají oprávnění k zápisu a spouštění.

Krok 5:Konfigurace souboru hive-site.xml (volitelné)
Distribuce Apache Hive ve výchozím nastavení obsahují konfigurační soubory šablon. Soubory šablon jsou umístěny v conf Hive adresář a výchozí nastavení Hive.
Pomocí následujícího příkazu vyhledejte správný soubor:
cd $HIVE_HOME/conf
Seznam souborů obsažených ve složce pomocí ls příkaz.

Použijte hive-default.xml.template vytvořit hive-site.xml soubor:
cp hive-default.xml.template hive-site.xmlPřejděte na hive-site.xml pomocí textového editoru nano:
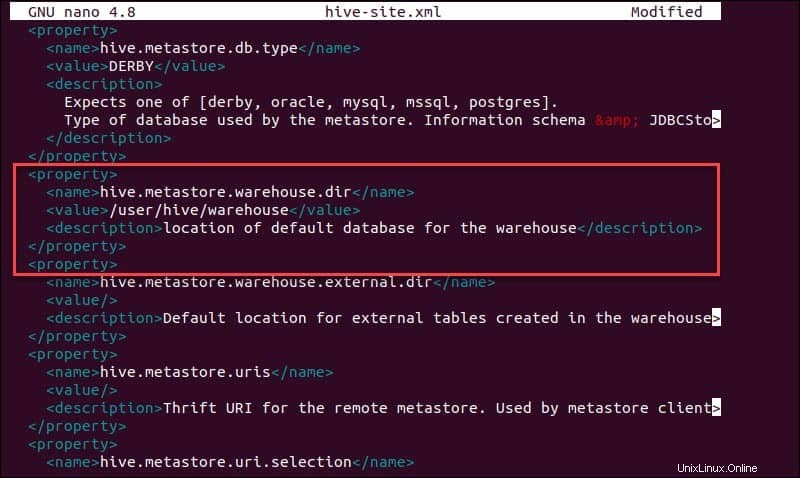
sudo nano hive-site.xmlPoužití Hive v samostatném režimu spíše než v reálném clusteru Apache Hadoop je bezpečnou možností pro nováčky. Nastavením hive.metastore.warehouse.dir můžete systém nakonfigurovat tak, aby místo vrstvy HDFS používal vaše místní úložiště hodnotu parametru k umístění vašeho skladu Hive adresář.
Krok 6:Spusťte databázi Derby
Apache Hive používá k ukládání metadat databázi Derby. Spusťte databázi Derby z přihrádky Úlu adresář pomocí schematool příkaz:
$HIVE_HOME/bin/schematool -dbType derby -initSchemaDokončení procesu může chvíli trvat.
Derby je výchozí úložiště metadat pro Hive. Pokud plánujete použít jiné databázové řešení, jako je MySQL nebo PostgreSQL, můžete zadat typ databáze v hive-site.xml soubor.
Jak opravit chybu nekompatibility guavy v Hive
Pokud se databáze Derby nespustí úspěšně, může se zobrazit chyba s následujícím obsahem:
“Výjimka ve vláknu “main” java.lang.NoSuchMethodError:com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V”
Tato chyba naznačuje, že s největší pravděpodobností došlo k problému s nekompatibilitou mezi Hadoop a Hive guava verze.
Najděte guava jar soubor v lib Hive adresář:
ls $HIVE_HOME/lib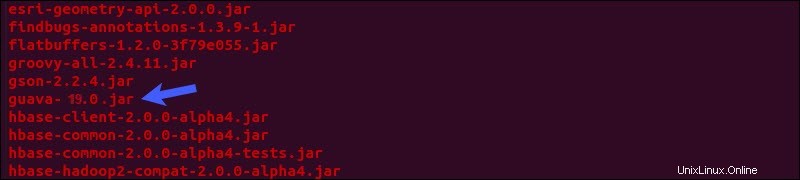
Najděte guava jar soubor v lib Hadoop adresář také:
ls $HADOOP_HOME/share/hadoop/hdfs/lib
Dvě uvedené verze nejsou kompatibilní a způsobují chybu. Odstraňte stávající guavu soubor z lib Hive adresář:
rm $HIVE_HOME/lib/guava-19.0.jarZkopírujte guavu soubor z Hadoop lib do adresáře Hive lib adresář:
cp $HADOOP_HOME/share/hadoop/hdfs/lib/guava-27.0-jre.jar $HIVE_HOME/lib/
Použijte schematool znovu spustit databázi Derby:
$HIVE_HOME/bin/schematool -dbType derby -initSchemaSpusťte prostředí Hive Client Shell na Ubuntu
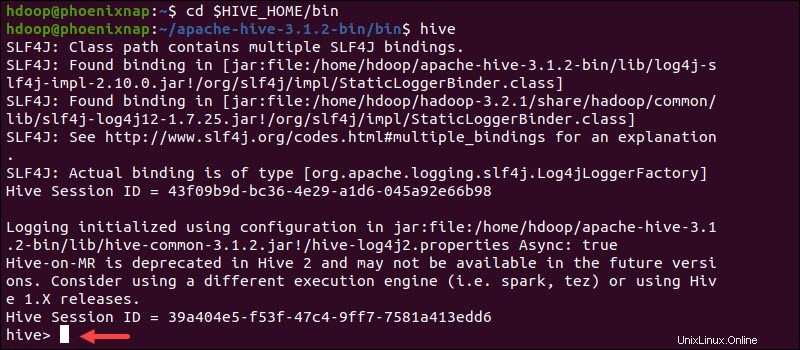
Spusťte rozhraní příkazového řádku Hive pomocí následujících příkazů:
cd $HIVE_HOME/binhiveNyní můžete zadávat příkazy podobné SQL a přímo interagovat s HDFS.