Scrapy je open-source software, který se používá pro extrakci dat z webových stránek. Scrapy framework je vyvinut v Pythonu a provádí práci procházení rychlým, jednoduchým a rozšiřitelným způsobem. Vytvořili jsme virtuální počítač (VM) ve virtuální krabici a je na něm nainstalováno Ubuntu 14.04 LTS.
Instalovat Scrapy
Scrapy je závislý na Pythonu, vývojových knihovnách a pip softwaru. Nejnovější verze Pythonu je předinstalovaná na Ubuntu. Před instalací Scrapy tedy musíme nainstalovat vývojářské knihovny pip a python.
Pip je náhradou za easy_install pro python package indexer. Používá se pro instalaci a správu balíčků Pythonu.
Chcete-li nainstalovat balíček pip, spusťte:
$ sudo apt-get install python-pip
Musíme nainstalovat vývojové knihovny pythonu pomocí následujícího příkazu. Pokud tento balíček není nainstalován, instalace scrapy frameworku vygeneruje chybu o hlavičkovém souboru python.h.
$ sudo apt-get install python-dev
Scrapy framework lze nainstalovat buď z deb balíčku nebo zdrojového kódu. Nicméně jsme nainstalovali deb balíček pomocí pip (Python package manager).
$ sudo pip install scrapy
Úspěšná instalace Scrapy nějakou dobu trvá.

Extrakce dat pomocí rámce Scrapy
(Základní výukový program)
Scrapy použijeme pro extrakci názvů obchodů (které poskytují karty) z webu fatwallet.com. Nejprve jsme pomocí následujícího příkazu vytvořili nový odpadový projekt „store_name“.
$ sudo scrapy startproject store_name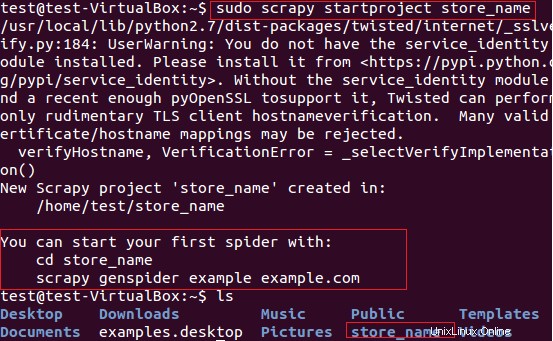
Výše uvedený příkaz vytvoří adresář s názvem „store_name“ na aktuální cestě. Tento hlavní adresář projektu obsahuje soubory/složky, které jsou znázorněny na následujícím obrázku 6.
$ sudo ls –lR store_name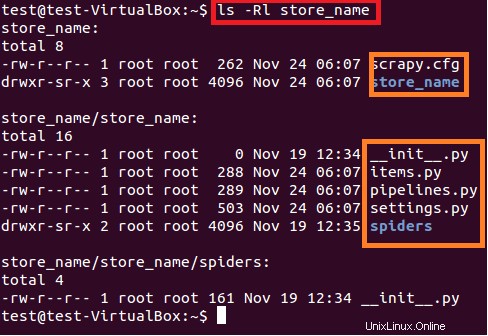
Stručný popis každého souboru/složky je uveden níže:
- scrapy.cfg je konfigurační soubor projektu
- název_obchodu/ je další adresář v hlavním adresáři. Tento adresář obsahuje python kód projektu.
- název_obchodu/items.py obsahuje položky, které budou extrahovány pavoukem.
- název_obchodu/pipelines.py je soubor kanálů.
- Nastavení projektu store_name je v souboru store_name/settings.py.
- a adresář store_name/spiders/ obsahuje pavouka pro procházení
Protože máme zájem extrahovat názvy obchodů karet ze stránky fatwallet.com, aktualizovali jsme obsah souboru, jak je uvedeno níže.
import scrapy
class StoreNameItem(scrapy.Item):
name = scrapy.Field() # extract the names of Cards storePoté musíme napsat nového pavouka do adresáře store_name/spiders/ projektu. Spider je třída pythonu, která se skládá z následujících povinných atributů:
Jméno pavouka (name )
- Počáteční adresa URL pavouka pro procházení (start_urls)
A parse metoda, která se skládá z regulárních výrazů pro extrakci požadovaných položek z odezvy stránky. Metoda analýzy je důležitou součástí pavouka.
Vytvořili jsme pavouka „store_name.py“ v adresáři store_name/spiders/ a přidali jsme následující python kód pro extrakci názvu obchodu ze stránky fatwallet.com. Výstup pavouka je zapsán v souboru (Název_obchodu.txt ).
from scrapy.selector import Selector
from scrapy.spider import BaseSpider
from scrapy.http import Request
from scrapy.http import FormRequest
import re
class StoreNameItem(BaseSpider):
name = "storename"
allowed_domains = ["fatwallet.com"]
start_urls = ["http://fatwallet.com/cash-back-shopping/"]
def parse(self,response):
output = open('StoreName.txt','w')
resp = Selector(response)
tags = resp.xpath('//tr[@class="storeListRow"]|\
//tr[@class="storeListRow even"]|\
//tr[@class="storeListRow even last"]|\
//tr[@class="storeListRow last"]').extract()
for i in tags:
i = i.encode('utf-8', 'ignore').strip()
store_name = ''
if re.search(r"class=\"storeListStoreName\">.*?<",i,re.I|re.S):
store_name = re.search(r"class=\"storeListStoreName\">.*?<",i,re.I|re.S).group()
store_name = re.search(r">.*?<",store_name,re.I|re.S).group()
store_name = re.sub(r'>',"",re.sub(r'<',"",store_name,re.I))
store_name = re.sub(r'&',"&",re.sub(r'&',"&",store_name,re.I))
#print store_name
output.write(store_name+""+"\n")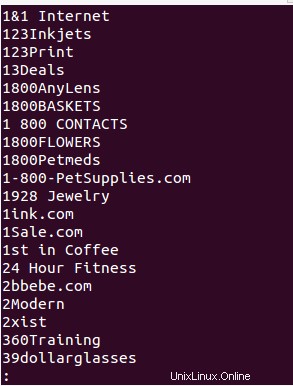
POZNÁMKA:Účelem tohoto tutoriálu je pouze pochopení Scrapy Framework