
V tomto tutoriálu vám ukážeme, jak nainstalovat Apache Hadoop na Ubuntu 20.04 LTS. Pro ty z vás, kteří nevěděli, Apache Hadoop je open-source framework používaný pro distribuované úložiště stejně jako distribuované zpracování velkých dat na klastrech počítačů, které běží na komoditním hardwaru. Spíše než se spoléhat na hardware při poskytování vysoké dostupnosti, je samotná knihovna navržena tak, aby detekovala a řešila selhání na aplikační vrstvě, takže poskytuje vysoce dostupnou službu na shluku počítačů, z nichž každý může být náchylný k selhání.
Tento článek předpokládá, že máte alespoň základní znalosti Linuxu, víte, jak používat shell, a co je nejdůležitější, hostujete svůj web na vlastním VPS. Instalace je poměrně jednoduchá a předpokládá, že běží v účtu root, pokud ne, možná budete muset přidat 'sudo ‘ k příkazům pro získání oprávnění root. Ukážu vám krok za krokem instalaci Flask na Ubuntu 20.04 (Focal Fossa). Můžete postupovat podle stejných pokynů pro Ubuntu 18.04, 16.04 a jakoukoli jinou distribuci založenou na Debianu, jako je Linux Mint.
Předpoklady
- Server s jedním z následujících operačních systémů:Ubuntu 20.04, 18.04, 16.04 a jakoukoli jinou distribucí založenou na Debianu, jako je Linux Mint.
- Abyste předešli případným problémům, doporučujeme použít novou instalaci operačního systému.
- Přístup SSH k serveru (nebo stačí otevřít Terminál, pokud jste na počítači).
non-root sudo usernebo přístup kroot user. Doporučujeme jednat jakonon-root sudo user, protože však můžete poškodit svůj systém, pokud nebudete při jednání jako root opatrní.
Nainstalujte Apache Hadoop na Ubuntu 20.04 LTS Focal Fossa
Krok 1. Nejprve se ujistěte, že všechny vaše systémové balíčky jsou aktuální, spuštěním následujícího apt příkazy v terminálu.
sudo apt update sudo apt upgrade
Krok 2. Instalace Java.
Abyste mohli spustit Hadoop, musíte mít na svém počítači nainstalovanou Javu 8. K tomu použijte následující příkaz:
sudo apt install default-jdk default-jre
Po instalaci můžete ověřit nainstalovanou verzi Javy pomocí následujícího příkazu:
java -version
Krok 3. Vytvořte uživatele Hadoop.
Nejprve vytvořte nového uživatele s názvem Hadoop pomocí následujícího příkazu:
sudo addgroup hadoopgroup sudo adduser —ingroup hadoopgroup hadoopuser
Dále se přihlaste jako uživatel Hadoop a vygenerujte pár klíčů SSH pomocí následujícího příkazu:
su - hadoopuser ssh-keygen -t rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 0600 ~/.ssh/authorized_keys
Poté ověřte SSH bez hesla pomocí následujícího příkazu:
ssh localhost
Jakmile se přihlásíte bez hesla, můžete přejít k dalšímu kroku.
Krok 4. Instalace Apache Hadoop na Ubuntu 20.04.
Nyní stahujeme nejnovější stabilní verzi Apache Hadoop, v okamžiku psaní tohoto článku je to verze 3.3.0:
su - hadoop wget https://downloads.apache.org/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz tar -xvzf hadoop-3.3.0.tar.gz
Dále přesuňte extrahovaný adresář do /usr/local/ :
sudo mv hadoop-3.3.0 /usr/local/hadoop sudo mkdir /usr/local/hadoop/logs
Změníme vlastnictví adresáře Hadoop na Hadoop:
sudo chown -R hadoop:hadoop /usr/local/hadoop
Krok 5. Nakonfigurujte Apache Hadoop.
Nastavení proměnných prostředí. Upravit ~/.bashrc souboru a na konec souboru připojte následující hodnoty:
nano ~/.bashrc
Přidejte následující řádky:
export HADOOP_HOME=/usr/local/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
Použijte proměnné prostředí na aktuálně běžící relaci:
source ~/.bashrc
Dále budete muset definovat proměnné prostředí Java v hadoop-env.sh pro konfiguraci nastavení projektu YARN, HDFS, MapReduce a Hadoop:
sudo nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh
Přidejte následující řádky:
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64 export HADOOP_CLASSPATH+=" $HADOOP_HOME/lib/*.jar"
Nyní můžete ověřit verzi Hadoop pomocí následujícího příkazu:
hadoop version
Krok 6. Nakonfigurujte core-site.xml soubor.
Otevřete soubor core-site.xml soubor v textovém editoru:
sudo nano $HADOOP_HOME/etc/hadoop/core-site.xml
Přidejte následující řádky:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://0.0.0.0:9000</value>
<description>The default file system URI</description>
</property>
</configuration>
Krok 7. Nakonfigurujte hdfs-site.xml Soubor.
K otevření souboru hdfs-site.xml použijte následující příkaz soubor pro úpravu:
sudo nano $HADOOP_HOME/etc/hadoop/hdfs-site.xml
Přidejte následující řádky:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hdfs/datanode</value>
</property>
</configuration>
Krok 8. Nakonfigurujte mapred-site.xml Soubor.
Pro přístup k mapred-site.xml použijte následující příkaz soubor:
sudo nano $HADOOP_HOME/etc/hadoop/mapred-site.xml
Přidejte následující řádky:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
Krok 9. Nakonfigurujte yarn-site.xml Soubor.
Otevřete soubor yarn-site.xml soubor v textovém editoru:
sudo nano $HADOOP_HOME/etc/hadoop/yarn-site.xml
Přidejte následující řádky:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration> Krok 10. Naformátujte HDFS NameNode.
Nyní se přihlásíme jako uživatel Hadoop a naformátujeme HDFS NameNode pomocí následujícího příkazu:
su - hadoop hdfs namenode -format
Krok 11. Spusťte Hadoop Cluster.
Nyní spusťte NameNode a DataNode následujícím příkazem:
start-dfs.sh
Potom spusťte správce zdrojů a uzlů YARN:
start-yarn.sh
Měli byste sledovat výstup, abyste se ujistili, že se pokouší spustit datanode na podřízených uzlech jeden po druhém. Chcete-li zkontrolovat, zda jsou všechny služby spuštěny dobře, pomocí 'jps ‘ příkaz:
jps
Krok 12. Přístup k Apache Hadoop.
Výchozí číslo portu 9870 vám poskytuje přístup k uživatelskému rozhraní Hadoop NameNode:
http://your-server-ip:9870
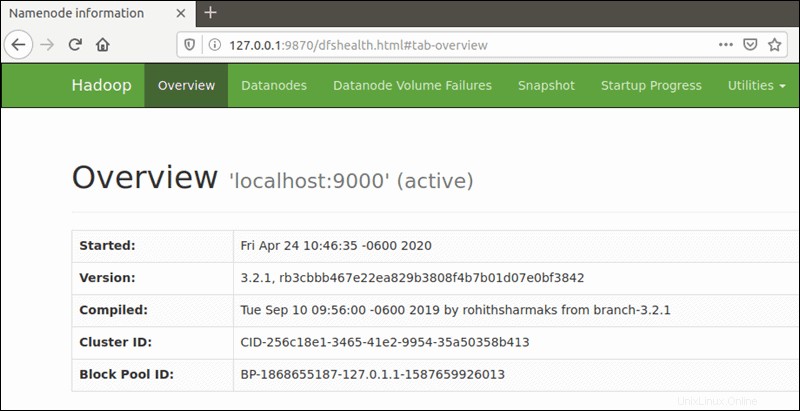
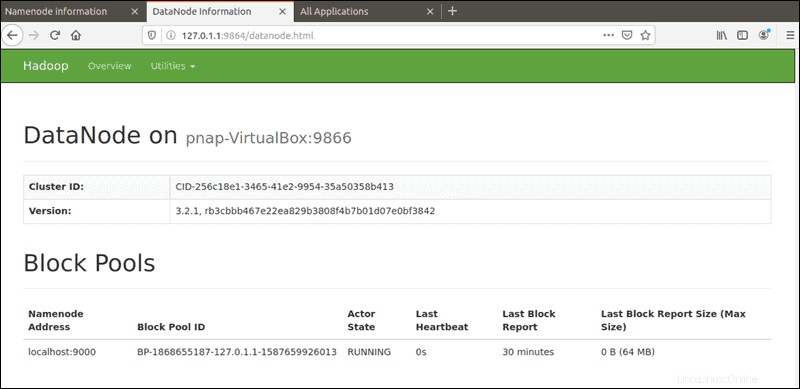
Výchozí port 9864 se používá pro přístup k jednotlivým DataNodes přímo z vašeho prohlížeče:
http://your-server-ip:9864
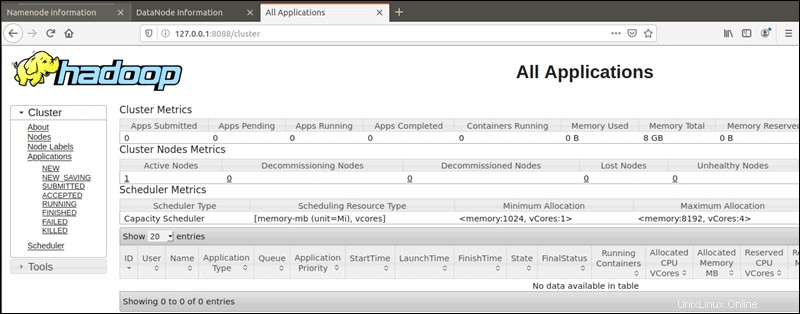
Správce zdrojů YARN je přístupný na portu 8088:
http://your-server-ip:8088
Blahopřejeme! Úspěšně jste nainstalovali Hadoop. Děkujeme, že jste použili tento návod k instalaci Apache Hadoop do vašeho systému Ubuntu 20.04 LTS Focal Fossa. Pro další pomoc nebo užitečné informace vám doporučujeme navštívit oficiální Web Apache Hadoop.