Chci najít své články na zastaralém (zastaralém) fóru literatury e-bane.net. Některé z modulů fóra jsou deaktivovány a nemohu získat seznam článků od jejich autora. Stránky také nejsou indexovány vyhledávači jako Google, Yndex atd.
Jediný způsob, jak najít všechny mé články, je otevřít archivní stránku webu (obr.1). Poté musím vybrat určitý rok a měsíc – např. ledna 2013 (obr.1). A pak musím u každého článku (obr.2) zkontrolovat, zda je na začátku napsána moje přezdívka – pa4080 (obr. 3). Ale existuje několik tisíc článků.
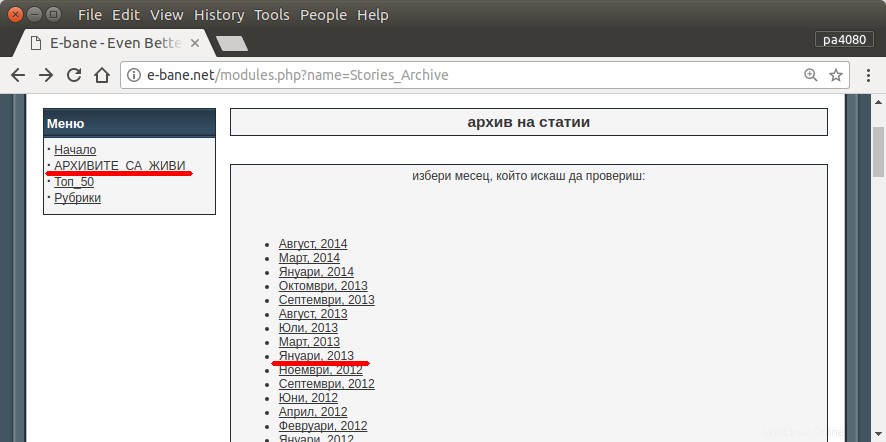
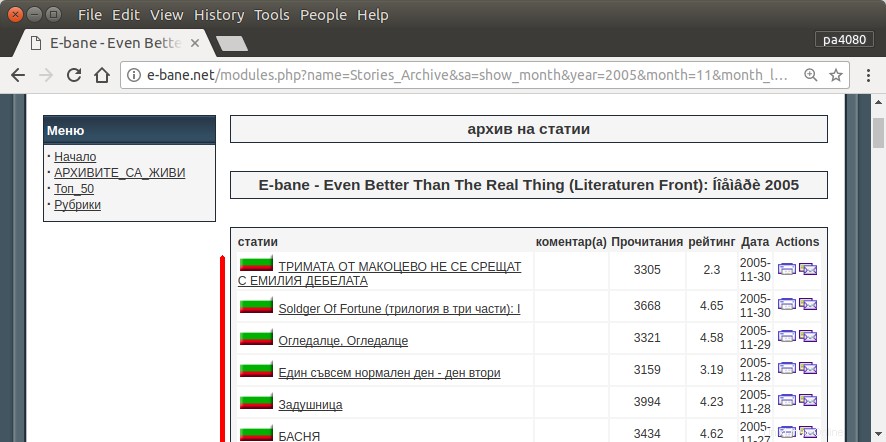
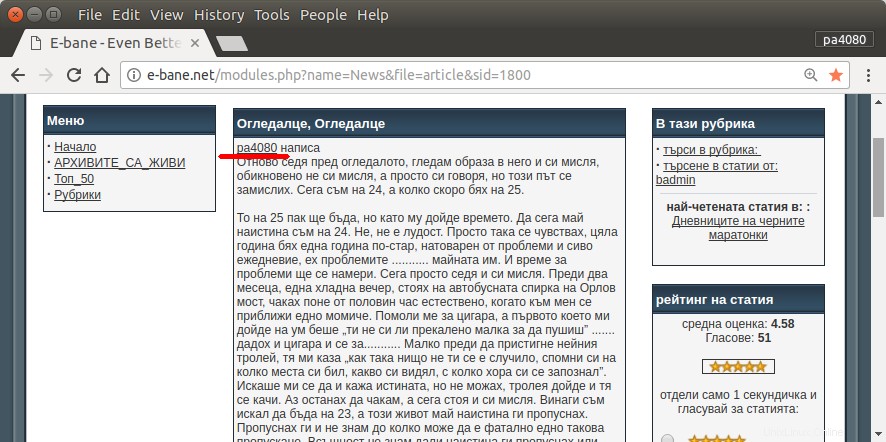
Přečetl jsem několik následujících témat, ale žádné z řešení nevyhovuje mým potřebám:
- Webový pavouk pro Ubuntu
- Jak napsat Web spider v systému Linux
- Získejte seznam adres URL z webu
Uveřejním vlastní řešení. Ale pro mě je zajímavé:
Existuje nějaký elegantnější způsob, jak tento úkol vyřešit?
Přijatá odpověď:
script.py :
#!/usr/bin/python3
from urllib.parse import urljoin
import json
import bs4
import click
import aiohttp
import asyncio
import async_timeout
BASE_URL = 'http://e-bane.net'
async def fetch(session, url):
try:
with async_timeout.timeout(20):
async with session.get(url) as response:
return await response.text()
except asyncio.TimeoutError as e:
print('[{}]{}'.format('timeout error', url))
with async_timeout.timeout(20):
async with session.get(url) as response:
return await response.text()
async def get_result(user):
target_url = 'http://e-bane.net/modules.php?name=Stories_Archive'
res = []
async with aiohttp.ClientSession() as session:
html = await fetch(session, target_url)
html_soup = bs4.BeautifulSoup(html, 'html.parser')
date_module_links = parse_date_module_links(html_soup)
for dm_link in date_module_links:
html = await fetch(session, dm_link)
html_soup = bs4.BeautifulSoup(html, 'html.parser')
thread_links = parse_thread_links(html_soup)
print('[{}]{}'.format(len(thread_links), dm_link))
for t_link in thread_links:
thread_html = await fetch(session, t_link)
t_html_soup = bs4.BeautifulSoup(thread_html, 'html.parser')
if is_article_match(t_html_soup, user):
print('[v]{}'.format(t_link))
# to get main article, uncomment below code
# res.append(get_main_article(t_html_soup))
# code below is used to get thread link
res.append(t_link)
else:
print('[x]{}'.format(t_link))
return res
def parse_date_module_links(page):
a_tags = page.select('ul li a')
hrefs = a_tags = [x.get('href') for x in a_tags]
return [urljoin(BASE_URL, x) for x in hrefs]
def parse_thread_links(page):
a_tags = page.select('table table tr td > a')
hrefs = a_tags = [x.get('href') for x in a_tags]
# filter href with 'file=article'
valid_hrefs = [x for x in hrefs if 'file=article' in x]
return [urljoin(BASE_URL, x) for x in valid_hrefs]
def is_article_match(page, user):
main_article = get_main_article(page)
return main_article.text.startswith(user)
def get_main_article(page):
td_tags = page.select('table table td.row1')
td_tag = td_tags[4]
return td_tag
@click.command()
@click.argument('user')
@click.option('--output-filename', default='out.json', help='Output filename.')
def main(user, output_filename):
loop = asyncio.get_event_loop()
res = loop.run_until_complete(get_result(user))
# if you want to return main article, convert html soup into text
# text_res = [x.text for x in res]
# else just put res on text_res
text_res = res
with open(output_filename, 'w') as f:
json.dump(text_res, f)
if __name__ == '__main__':
main()
requirement.txt :
aiohttp>=2.3.7
beautifulsoup4>=4.6.0
click>=6.7
Zde je verze skriptu python3 (testováno na python3.5 na Ubuntu 17.10 ).
Jak používat:
- Chcete-li jej použít, vložte oba kódy do souborů. Jako příklad je soubor kódu
script.pya soubor balíčku jerequirement.txt. - Spusťte
pip install -r requirement.txt. - Spusťte skript jako příklad
python3 script.py pa4080
Používá několik knihoven:
- kliknutím zobrazíte analyzátor argumentů
- krásná polévka pro analyzátor HTML
- aiohttp pro html downloader
Co byste měli vědět pro další vývoj programu (kromě dokumentu požadovaného balíčku):
- Knihovna python:asyncio, json a urllib.parse
- selektory css (webové dokumenty mdn), také některé html. podívejte se také na to, jak používat selektor css ve vašem prohlížeči, jako je tento článek
Jak to funguje:
- Nejprve vytvořím jednoduchý html downloader. Je to upravená verze z ukázky uvedené na aiohttp doc.
- Po tomto vytvoření jednoduchého analyzátoru příkazového řádku, který akceptuje uživatelské jméno a výstupní název souboru.
- Vytvořte analyzátor pro odkazy na vlákna a hlavní článek. Použití pdb a jednoduchá manipulace s adresami URL by měly fungovat.
- Zkombinujte funkci a vložte hlavní článek do json, aby jej později mohl zpracovat jiný program.
Nějaký nápad, aby se to dalo dále rozvíjet
- Vytvořte další dílčí příkaz, který přijímá odkaz na modul data:lze to provést oddělením metody analýzy modulu data na jeho vlastní funkci a zkombinováním s novým dílčím příkazem.
- Ukládání odkazu na modul data do mezipaměti:po získání odkazu na vlákna vytvořte soubor cache json. takže program nemusí znovu analyzovat odkaz. nebo dokonce uložte do mezipaměti celý hlavní článek vlákna, i když se neshoduje
Toto není nejelegantnější odpověď, ale myslím si, že je lepší než používat bash odpověď.
- Používá Python, což znamená, že jej lze používat napříč platformami.
- Jednoduchá instalace, všechny požadované balíčky lze nainstalovat pomocí pip
- Může být dále vyvíjen, program je čitelnější, lze jej snadněji rozvíjet.
- Provádí stejnou práci jako bash skript pouze po dobu 13 minut .