Apache Spark je bezplatný a open source cluster-computing framework používaný pro analýzu, strojové učení a zpracování grafů na velkých objemech dat. Spark přichází s 80+ operátory na vysoké úrovni, které vám umožňují vytvářet paralelní aplikace a používat je interaktivně z prostředí Scala, Python, R a SQL. Jedná se o bleskově rychlý motor pro zpracování dat v paměti speciálně navržený pro datovou vědu. Poskytuje bohatou sadu funkcí včetně rychlosti, odolnosti proti chybám, zpracování streamu v reálném čase, počítání v paměti, pokročilé analýzy a mnoha dalších.
V tomto tutoriálu vám ukážeme, jak nainstalovat Apache Spark na server Debian 10.
Předpoklady
- Server se systémem Debian 10 s 2 GB RAM.
- Na vašem serveru je nakonfigurováno heslo uživatele root.
Začínáme
Před spuštěním se doporučuje aktualizovat server na nejnovější verzi. Můžete jej aktualizovat pomocí následujícího příkazu:
apt-get update -y
apt-get upgrade -y
Jakmile je váš server aktualizován, restartujte jej, aby se změny implementovaly.
Instalovat Javu
Apache Spark je napsán v jazyce Java. Budete tedy muset do svého systému nainstalovat Javu. Ve výchozím nastavení je ve výchozím úložišti Debian 10 k dispozici nejnovější verze Javy. Můžete jej nainstalovat pomocí následujícího příkazu:
apt-get install default-jdk -y
Po instalaci Javy ověřte nainstalovanou verzi Javy pomocí následujícího příkazu:
java --version
Měli byste získat následující výstup:
openjdk 11.0.5 2019-10-15 OpenJDK Runtime Environment (build 11.0.5+10-post-Debian-1deb10u1) OpenJDK 64-Bit Server VM (build 11.0.5+10-post-Debian-1deb10u1, mixed mode, sharing)
Stáhnout Apache Spark
Nejprve si budete muset stáhnout nejnovější verzi Apache Spark z jeho oficiálních stránek. V době psaní tohoto článku je nejnovější verze Apache Spark 3.0. Můžete si jej stáhnout do adresáře /opt pomocí následujícího příkazu:
cd /opt
wget http://apachemirror.wuchna.com/spark/spark-3.0.0-preview2/spark-3.0.0-preview2-bin-hadoop2.7.tgz
Po dokončení stahování rozbalte stažený soubor pomocí následujícího příkazu:
tar -xvzf spark-3.0.0-preview2-bin-hadoop2.7.tgz
Dále přejmenujte extrahovaný adresář na jiskru, jak je znázorněno níže:
mv spark-3.0.0-preview2-bin-hadoop2.7 spark
Dále budete muset nastavit prostředí pro Spark. Můžete to udělat úpravou souboru ~/.bashrc:
nano ~/.bashrc
Na konec souboru přidejte následující řádky:
export SPARK_HOME=/opt/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
Po dokončení uložte a zavřete soubor. Poté aktivujte prostředí pomocí následujícího příkazu:
source ~/.bashrc
Spusťte hlavní server
Nyní můžete spustit hlavní server pomocí následujícího příkazu:
start-master.sh
Měli byste získat následující výstup:
starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-debian10.out
Ve výchozím nastavení Apache Spark naslouchá na portu 8080. Můžete to ověřit pomocí následujícího příkazu:
netstat -ant | grep 8080
Výstup:
tcp6 0 0 :::8080 :::* LISTEN
Nyní otevřete webový prohlížeč a zadejte URL http://server-ip-address:8080. Měli byste vidět následující stránku:
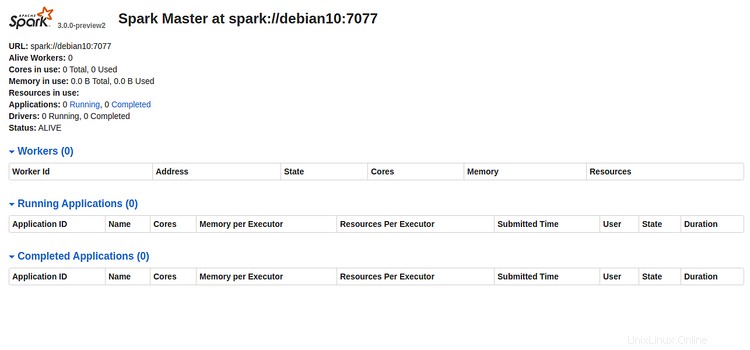
Poznamenejte si Spark URL "spark://debian10:7077 " z výše uvedeného obrázku. To bude použito ke spuštění pracovního procesu Spark.
Spustit proces Spark Worker
Nyní můžete spustit pracovní proces Spark pomocí následujícího příkazu:
start-slave.sh spark://debian10:7077
Měli byste získat následující výstup:
starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-debian10.out
Přístup k Spark Shell
Spark Shell je interaktivní prostředí, které poskytuje jednoduchý způsob, jak se naučit rozhraní API a interaktivně analyzovat data. K shellu Spark se dostanete pomocí následujícího příkazu:
spark-shell
Měli byste vidět následující výstup:
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform (file:/opt/spark/jars/spark-unsafe_2.12-3.0.0-preview2.jar) to constructor java.nio.DirectByteBuffer(long,int)
WARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
19/12/29 15:53:11 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://debian10:4040
Spark context available as 'sc' (master = local[*], app id = local-1577634806690).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.0.0-preview2
/_/
Using Scala version 2.12.10 (OpenJDK 64-Bit Server VM, Java 11.0.5)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
Zde se můžete naučit, jak rychle a pohodlně využít Apache Spark na maximum.
Pokud chcete zastavit Spark Master a Slave server, spusťte následující příkazy:
stop-slave.sh
stop-master.sh
To je prozatím vše, úspěšně jste nainstalovali Apache Spark na server Debian 10. Další informace najdete v oficiální dokumentaci Spark na Spark Doc.