Úvod
Existuje několik případů, kdy se můžete setkat s duplicitními řádky ve vaší databázi MySQL. Tento průvodce vás provede procesem odstranění duplicitních hodnot řádků v MySQL.

Předpoklady
- Systém s nainstalovaným MySQL
- Kořenový uživatelský účet MySQL
- Přístup do okna terminálu / příkazového řádku (Ctrl-Alt-T, Hledat> Terminál)
Nastavení testovací databáze
Pokud již máte databázi MySQL, na které můžete pracovat, přejděte k další části.
V opačném případě otevřete okno terminálu a zadejte následující:
mysql –u root –pPo zobrazení výzvy zadejte root heslo pro vaši instalaci MySQL. Pokud máte konkrétní uživatelský účet, použijte tyto přihlašovací údaje místo roota.
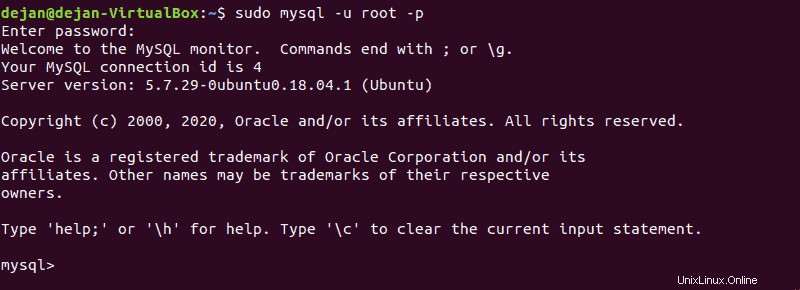
Systémová výzva by se měla změnit na:
mysql>Vytvořit testovací databázi
V existující databázi můžete vytvořit novou tabulku. Chcete-li tak učinit, vyhledejte příslušnou databázi uvedením všech existujících instancí s:
SHOW DATABASES;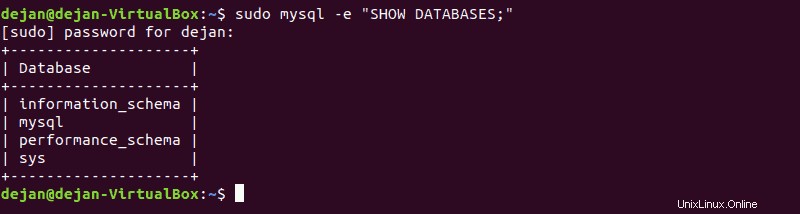
Případně můžete vytvořit novou databázi zadáním následujícího příkazu:
CREATE DATABASE IF NOT EXISTS testdata;
Chcete-li začít pracovat s novými testdata použití databáze:
USE testdata;Přidat tabulku a data
Jakmile budete v databázi, přidejte tabulku s níže uvedenými daty pomocí následujícího příkazu:
CREATE TABLE dates (
id INT PRIMARY KEY AUTO_INCREMENT,
day VARCHAR(2) NOT NULL,
month VARCHAR(10) NOT NULL,
year VARCHAR(4) NOT NULL
);
INSERT INTO dates (day,month,year)
VALUES (’29’,’January’,’2011’),
(’30’,’January’,’2011’),
(’30’,’January’,’2011’),
(’14’,’February,’2017’),
(’14’,’February,’2018’),
(‘23’,’March’,’2018’),
(‘23’,’March’,’2018’),
(‘23’,’March’,’2019’),
(‘29’,’October’,’2019’),
(‘29’,’November’,’2019’),
(‘12’,’November’,’2017’),
(‘17’,’August’,’2018’),
(‘05’,’June’,’2016’);Zobrazte obsah tabulky s daty
Chcete-li zobrazit všechna zadaná data seřazená podle roku, zadejte:
SELECT * FROM dates ORDER BY year;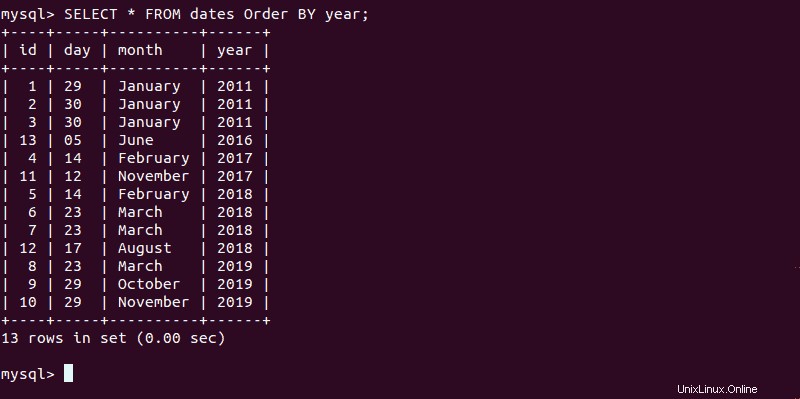
Výstup by měl zobrazovat seznam dat v příslušném pořadí.
Zobrazit duplicitní řádky
Chcete-li zjistit, zda jsou v testovací databázi duplicitní řádky, použijte příkaz:
SELECT
day, COUNT(day),
month, COUNT(month),
year, COUNT(year)
FROM
dates
GROUP BY
day,
month,
year
HAVING
COUNT(day) > 1
AND COUNT(month) > 1
AND COUNT(year) > 1;Systém zobrazí všechny duplicitní hodnoty. V tomto případě byste měli vidět:
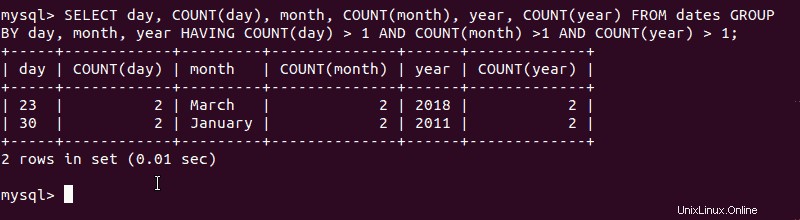
Tento formát funguje pro výběr více sloupců. Pokud máte sloupec s jedinečným identifikátorem, jako je e-mailová adresa v seznamu kontaktů nebo sloupec s jedním datem, můžete jednoduše vybrat z tohoto sloupce.
Odstranění duplicitních řádků
Před použitím některé z níže uvedených metod nezapomeňte, že musíte pracovat v existující databázi. Budeme používat naši vzorovou databázi:
USE testdata;Možnost 1:Odstraňte duplicitní řádky pomocí INNER JOIN
Chcete-li odstranit duplicitní řádky v naší testovací MySQL tabulce, použijte MySQL JOINS a zadejte následující:
delete t1 FROM dates t1
INNER JOIN dates t2
WHERE
t1.id < t2.id AND
t1.day = t2.day AND
t1.month = t2.month AND
t1.year = t2.year;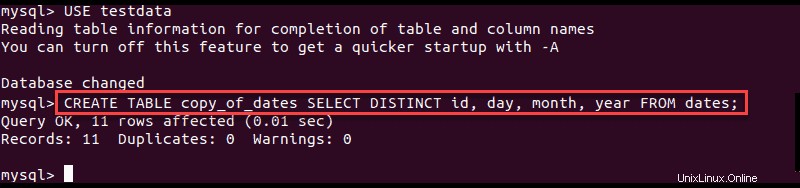
Můžete také použít příkaz z Zobrazit duplikát Řádky pro ověření smazání.
Možnost 2:Odstraňte duplicitní řádky pomocí mezilehlé tabulky
Můžete vytvořit střední tabulku a použijte jej k odstranění duplicitních řádků. To se provádí přenesením pouze jedinečných řádků do nově vytvořené tabulky a smazáním původního (se zbývajícími duplicitními řádky).
Chcete-li tak učinit, postupujte podle pokynů níže.
1. Vytvořte přechodnou tabulku, která má stejnou strukturu jako zdrojová tabulka, a přeneste jedinečné řádky nalezené ve zdroji:
CREATE TABLE [copy_of_source] SELECT DISTINCT [columns] FROM [source_table];
Chcete-li například vytvořit kopii struktury ukázkové tabulky dates příkaz je:
CREATE TABLE copy_of_dates SELECT DISTINCT id, day, month, year FROM dates;2. Po dokončení můžete zdrojovou tabulku odstranit příkazem drop a přejmenovat novou:
DROP TABLE [source_table];ALTER TABLE [copy_of_source] RENAME TO [source_table];Například:
DROP TABLE dates;ALTER TABLE copy_of_dates RENAME TO dates;
Možnost 3:Odstraňte duplicitní řádky pomocí ROW_NUMBER()
Důležité: Tato metoda je dostupná pouze pro MySQL verze 8.02 a později. Před pokusem o tuto metodu zkontrolujte verzi MySQL.
Dalším způsobem, jak odstranit duplicitní řádky, je ROW_NUMBER() funkce.
SELECT *. ROW_NUMBER () Over (PARTITION BY [column] ORDER BY [column]) as [row_number_name];Příkaz pro naši ukázkovou tabulku by tedy byl:
SELECT *. ROW_NUMBER () Over (PARTITION BY id ORDER BY id) as row_number;Výsledky zahrnují číslo_řádku sloupec. Data jsou rozdělena podle id a v každém oddílu jsou jedinečná čísla řádků. Jedinečné hodnoty jsou označeny číslem řádku 1 , zatímco duplikáty jsou 2 , 3 , a tak dále.
Chcete-li tedy odstranit duplicitní řádky, musíte smazat vše kromě těch, které jsou označeny 1. To se provede spuštěním DELETE dotaz pomocí row_number jako filtr.
Chcete-li odstranit duplicitní řádky, spusťte:
DELETE FROM [table_name] WHERE row_number > 1;V našem příkladu data tabulka, příkaz by byl:
DELETE FROM dates WHERE row_number > 1;Výstup vám řekne, kolik řádků bylo ovlivněno, to znamená, kolik duplicitních řádků bylo odstraněno.
Neexistenci duplicitních řádků můžete ověřit spuštěním:
SELECT * FROM [table_name];Například:
SELECT * FROM dates;