Úvod
Řetězcové funkce MySQL umožňují uživatelům manipulovat s datovými řetězci nebo dotazovat se na informace o řetězci vráceném pomocí SELECT dotaz.
V tomto článku se dozvíte, jak používat funkce řetězce MySQL.

Předpoklady
- Nainstalován server MySQL a prostředí MySQL
- Uživatelský účet MySQL s právy root
Cheat Sheet pro funkce řetězců MySQL
Každá funkce řetězce je vysvětlena a uvedena na příkladu v článku níže. Pokud je to pro vás pohodlnější, můžete si uložit cheat ve formátu PDF kliknutím na Stáhnout cheat pro funkce MySQL String Functions odkaz.
Stáhněte si Cheat Sheet funkcí MySQL String Functions
ASCII()
Syntaxe pro ASCII() funkce je:
ASCII('str')
ASCII() řetězec vrací ASCII (numerickou) hodnotu znaku zcela vlevo zadaného str tětiva. Funkce vrátí 0, pokud není str je specifikováno. Vrátí NULL if str je NULL .
Použijte ASCII() pro znaky s číselnými hodnotami od 0 do 255.
Například:

V tomto příkladu ASCII() funkce vrací číselnou hodnotu p , znak zcela vlevo ze zadaného str řetězec.
BIN()
Syntaxe pro BIN() funkce je:
BIN(number)
BIN() funkce vrací binární hodnotu zadaného number argument, kde number je BIGINTEGER číslo. Vrátí NULL pokud number argument je NULL .
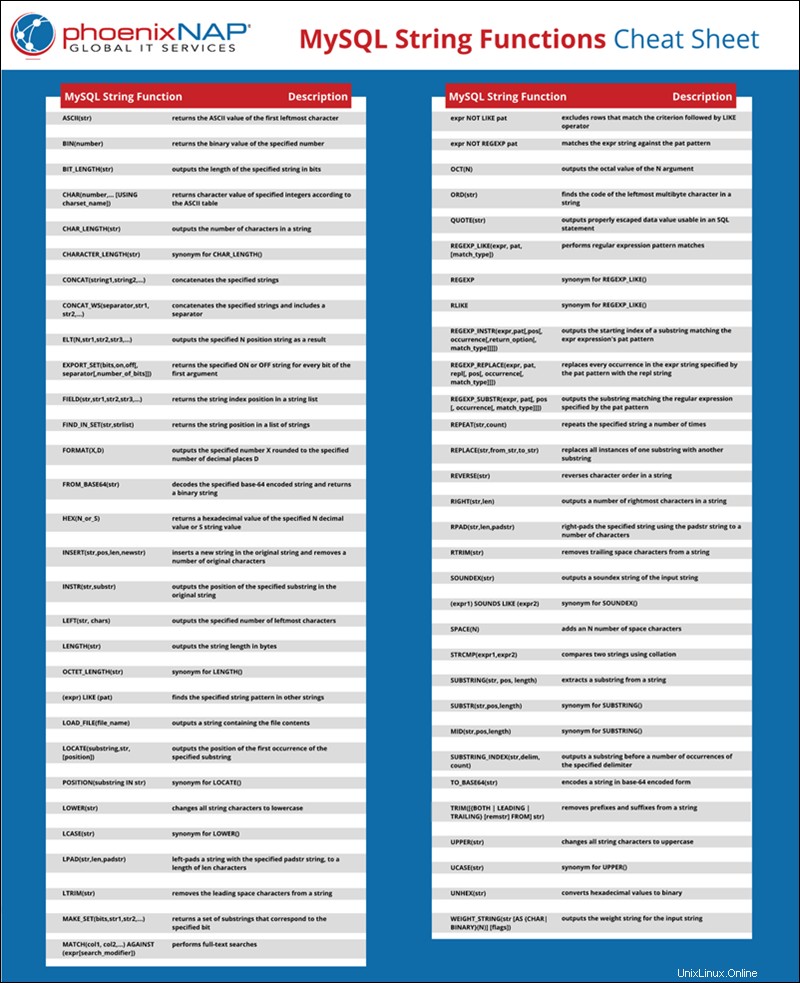
Například následující dotaz vrátí binární reprezentaci čísla 25:
BIT_LENGTH()
Syntaxe pro BIT_LENGTH() funkce je:
BIT_LENGTH('str')
Funkce vypíše délku zadaného str řetězec v bitech.
Například následující dotaz vrátí bitovou délku zadaného „příkladu ' řetězec:

CHAR()
Syntaxe pro CHAR() funkce je:
CHAR(number,... [USING charset_name])
CHAR() interpretuje každé zadané number argument jako celé číslo a vypíše binární řetězec znaků z tabulky ASCII. Funkce přeskočí NULL hodnoty.
Například:

Pokud chcete vytvořit výstup jiný než binární, použijte nepovinné USING klauzuli a zadejte požadovanou znakovou sadu. MySQL vydá varování, pokud je výsledný řetězec pro zadanou znakovou sadu neplatný.
CHAR_LENGTH(), tj. CHARACTER_LENGTH()
Syntaxe pro CHAR_LENGTH funkce je:
CHAR_LENGTH(str)
Funkce vypíše délku zadaného str řetězec, měřený ve znacích.
CHAR_LENGTH() považuje vícebajtový znak za jeden znak, což znamená, že řetězec obsahující čtyři dvoubajtové znaky ve výsledku vrátí 4, zatímco LENGTH() vrátí 8.
Například:

CHARACTER_LENGTH() je synonymem pro CHAR_LENGTH() .
CONCAT()
CONCAT() funkce zřetězí dva nebo více zadaných řetězců. Syntaxe je:
CONCAT(string1,string2,...)
CONCAT funkce převede všechny argumenty na typ řetězce před zřetězením. Pokud jsou všechny argumenty nebinární řetězce, výsledkem je nebinární řetězec. Na druhé straně zřetězení binárních řetězců vede k binárnímu řetězci. Číselný argument je převeden na ekvivalentní formu nebinárního řetězce.
Pokud je některý ze zadaných argumentů NULL , CONCAT() vrátí NULL v důsledku toho.
Například:

Funkce spojí zadané řetězce do jednoho, v tomto případě 'phoenixNAP '.
CONCAT_WS()
Syntaxe pro CONCAT_WS() je:
CONCAT_WS(separator,str1,str2,...)
CONCAT_WS() je speciální forma CONCAT() který spojuje dva nebo více výrazů a obsahuje oddělovač. Oddělovač rozdělí řetězce, které chcete zřetězit. Pokud je oddělovač NULL , výsledkem je NULL .
Například:

V tomto příkladu je oddělovač prázdný prostor, který odděluje zadané řetězce ve výstupu.
ELT()
Syntaxe pro ELT() funkce je:
ELT(N,str1,str2,str3,...)
N argument definuje, který ze zadaných řetězců se má jako výsledek vrátit. ELT() vrátí NULL pokud N je menší než 1 nebo větší než počet zadaných řetězců.
Například:

EXPORT_SET()
Syntaxe pro EXPORT_SET() je:
EXPORT_SET(bits,on,off[,separator[,number_of_bits]])
EXPORT_SET() funkce vrátí ON nebo OFF řetězec pro každý bit prvního argumentu, kontrola zprava doleva. Argument je celé číslo, ale funkce jej převede na bity.
Pokud je bit 1, funkce vrátí ON tětiva. Pokud je bit 0, funkce vrátí OFF . EXPORT_SET() umístí oddělovač mezi návratové hodnoty. Výchozím oddělovačem je čárka, ale jako čtvrtý argument můžete zadat jiný.
Řetězce se přidávají do výstupního výsledku zleva doprava, oddělené oddělovacím řetězcem. number_of_bits argument určuje, kolik bitů se má prozkoumat.
Například:

Vysvětlení:
1. Po převodu první argument 5 znamená 00000101.
2. Kontrola zprava doleva, první bit je 1, takže funkce vrátí 'Ano argument ' (ON tětiva). Druhý bit je 0, takže funkce vrátí 'Ne ' (OFF tětiva). U třetího bitu vrátí „Ano .' Pro všechny zbývající bity (nuly) vrátí 'Ne .'
3. Čtvrtý argument '- ' je určen jako oddělovač ve výsledku návratu.
FIELD()
Syntaxe pro FIELD() syntaxe je:
FIELD(str,str1,str2,str3,...)
Funkce vrací pozici indexu řetězce v seznamu řetězců. Pokud takový řetězec neexistuje, výstup je 0. Pokud je řetězec NULL , funkce vrátí 0. FIELD() funkce nerozlišuje malá a velká písmena.
Například:

Funkce vrátí 6, což je pozice řetězce 'f ' v seznamu.
FIND_IN_SET()
Syntaxe pro FIND_IN_SET() funkce je:
FIND_IN_SET(str,strlist)Funkce vrací pozici řetězce v seznamu řetězců. Pokud existuje několik instancí řetězce, výstup vrátí pouze první pozici zadaného řetězce.
Například:

FORMAT()
Syntaxe pro FORMAT() funkce je:
FORMAT(X,D)
Funkce vypíše zadané číslo X ve formátu jako '#,###,###.##', zaokrouhleno na zadaný počet desetinných míst D . Pokud D, výsledek nemá desetinnou čárku je 0.
Uživatelé mohou také zadat národní prostředí za D argument, který ovlivňuje výstup.
Například:

Výstup zaokrouhlí číslo na 3 desetinná místa a německé národní prostředí způsobí . symbol pro označení tisíců a , znak pro označení zlomků.
FROM_BASE64()
Syntaxe pro FROM_BASE64() funkce je:
FROM_BASE64(str)
Funkce dekóduje zadaný řetězec kódovaný base-64 a vrátí výsledek jako binární řetězec. Pokud je argument NULL nebo neplatný řetězec base-64, výsledkem je NULL .
FROM_BASE64() je opakem TO_BASE64() jako TO_BASE64() zakóduje dotaz v base64.
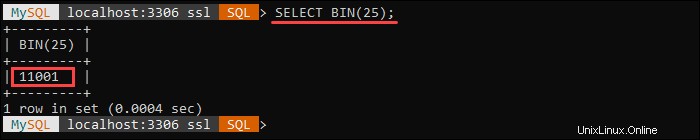
Například:
První dotaz zakóduje zadaný řetězec v base64. Druhý dotaz dekóduje zakódovaný řetězec base64 a vrátí původní hodnotu.
HEX()
Syntaxe pro HEX() funkce je:
HEX(N_or_S)
Funkce vrací řetězcovou reprezentaci hexadecimální hodnoty zadaného N desetinná hodnota nebo S hodnota řetězce.
Pokud je argumentem string , HEX převede každý znak na dvě hexadecimální číslice. Na druhou stranu, pokud je argument decimal , výstupem je hexadecimální řetězec reprezentace argumentu a považuje se za BIGINTEGER číslo.
HEX() funkce string je ekvivalentní matematické funkci CONV(N,10,16) .
Například:

Výstup vrátí hexadecimální hodnotu zadaného řetězce.
INSERT()
Syntaxe pro INSERT() funkce je:
INSERT(str,pos,len,newstr)
Funkce vloží newstr řetězec v str řetězec a odstraní len počet původních znaků začínajících na pos pozici.
Pokud pos argument není v rámci původní délky řetězce, INSERT() vrátí původní řetězec.
Pokud len argument není v rámci délky zbytku řetězce, INSERT() nahradí zbytek řetězce z pos pozici.
Pokud je některý argument NULL , INSERT() vrátí NULL .
Například:

Výstupem je původní řetězec s novým řetězcem vloženým na pozici 5, bez odstranění původních znaků.
INSTR()
Syntaxe pro INSTR() funkce je:
INSTR(str,substr)
Funkce vypíše pozici prvního výskytu substr podřetězec v původním str řetězec.
Funkce funguje stejným způsobem jako LOCATE() , kromě toho, že pořadí argumentů je obrácené.
Například:

Výstup označuje umístění podřetězce - pozice 8.
LEFT()
Syntaxe pro LEFT() funkce je:
LEFT('str', chars)
Funkce vypíše počet znaků chars nejvíce vlevo ze zadaného str řetězec.
Pokud je některý argument NULL , výstup je také NULL .
Například:

LENGTH(), tj. OCTET_LENGTH()
Syntaxe pro LENGTH() funkce je:
LENGTH(str)
Funkce vypíše str délka řetězce v bajtech. Vícebajtové znaky se počítají jako více bajtů.
Například:

OCTET_LENGTH() funkce je synonymem pro LENGTH() .
LIKE
Syntaxe pro LIKE funkce je:
expr LIKE patFunkce provádí porovnávání vzorů nalezením zadaného vzoru řetězce v jiných řetězcích.
LIKE podporuje zástupné znaky:
%-Odpovídá libovolnému počtu znaků, dokonce i nule._- Odpovídá přesně jednomu znaku.
LIKE vrátí 1 (pravda) nebo 0 (nepravda). Pokud expr výraz nebo pat vzor je NULL , výstup je také NULL .
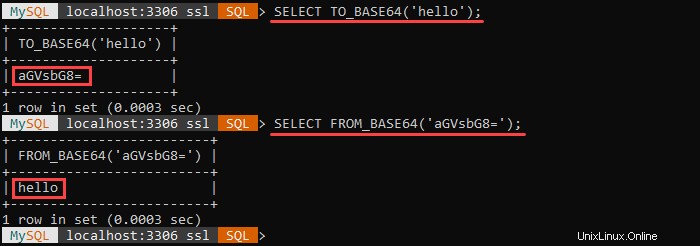
Například:
V tomto příkladu jsme získali všechny zákazníky, jejichž jméno začíná „A '.
LOAD_FILE()
Syntaxe pro LOAD_FILE() funkce je:
LOAD_FILE(file_name)Funkce přečte soubor a vypíše řetězec obsahující obsah souboru. Předpoklady pro tuto funkci jsou:
- Soubor na hostiteli serveru.
- Zadání úplné cesty k souboru namísto argumentu název_souboru.
- Máte právo FILE .
Server musí být schopen číst soubor a jeho velikost musí být menší než max_allowed_packet bajtů. Pokud secure_file_priv systémová proměnná je neprázdný název adresáře, umístěte soubor do tohoto adresáře.
Pokud soubor neexistuje nebo jej funkce nemůže přečíst z jednoho z výše uvedených důvodů, výstup je NULL .
Například:

LOCATE(), tj. POSITION()
Syntaxe pro LOCATE() funkce je:
LOCATE(substring,str,[position])
Funkce vypíše pozici prvního výskytu zadaného substring argument v str tětiva. position argument je volitelný a používá se k určení, ze kterého str pozice řetězce pro zahájení vyhledávání. Vynechání position argument začne hledat od začátku.
Pokud substring není v str řetězec, LOCATE() vrátí 0. Pokud je některý argument NULL , funkce vrátí NULL .
Například:

POSITION(substring IN str) funkce je synonymem pro LOCATE(substr,str) .
LOWER(), tj. LCASE()
Syntaxe pro LOWER() funkce je:
LOWER(str)
Funkce změní všechny znaky zadaného str řetězec na malá písmena a vypíše výsledek. Výchozí mapování znakové sady, které používá, je utf8mb4. LOWER() je vícebajtový bezpečný.
Například:

LCASE() funkce je synonymem pro LOWER() .
LPAD()
Syntaxe pro LPAD() funkce je:
LPAD(str,len,padstr)
Funkce vypíše zadaný str řetězec, doleva doplněný padstr řetězec na délku len znaky. Funkce zkrátí výstup na len znaků, pokud str argument je delší než len .
LPAD() je vícebajtový bezpečný.
Například:

V tomto příkladu LPAD() funkce doleva doplní zadaný argument zadaným padstr , až 10 znaků.
LTRIM()
Syntaxe pro LTRIM() funkce je:
LTRIM(str)
Funkce vypíše zadaný str řetězec bez úvodních mezer.
Například:

MAKE_SET()
Syntaxe pro MAKE_SET() funkce je:
MAKE_SET(bits,str1,str2,...)
Funkce vypíše nastavenou hodnotu, tj. řetězec obsahující zadané podřetězce s odpovídajícím bitem zadaným v bits argument.
str1 argument odpovídá bitu 0, str2 odpovídá bitu 1 atd. Pokud je některý z argumentů NULL , neobjeví se ve výsledku.
Například:

V tomto příkladu je první bit 1, tj. 001. Číslice zcela vpravo je 1, takže funkce vrátí 'fénix .' Druhý bit je 2, tj. 010, prostřední číslo je 1, takže funkce vrací 'NAP ,“ čímž je výstup dokončen.
MATCH()
Syntaxe pro MATCH() funkce je:
MATCH(col1, col2,…) AGAINST(expr[search_modifier])
Funkce umožňuje uživatelům provádět fulltextové vyhledávání zadáním seznamu sloupců oddělených čárkami. Zadejte řetězec, který chcete vyhledat, namísto expr argument.
search_modifier argument je volitelný a označuje typ vyhledávání. Přijímané hodnoty jsou:
IN NATURAL LANGUAGE MODE(výchozí)IN NATURAL LANGUAGE MODE WITH QUERY EXPANSIONIN BOOLEAN MODEWITH QUERY EXPANSION
Například:
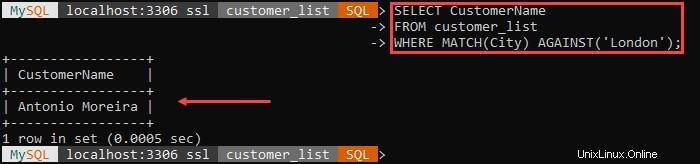
NELÍBÍ se
Syntaxe pro NOT LIKE funkce je:
expr NOT LIKE pat [ESCAPE 'escape_char']
NOT LIKE je negací LIKE , což znamená, že funguje za stejných podmínek jako LIKE a používá stejné zástupné znaky.
Například:
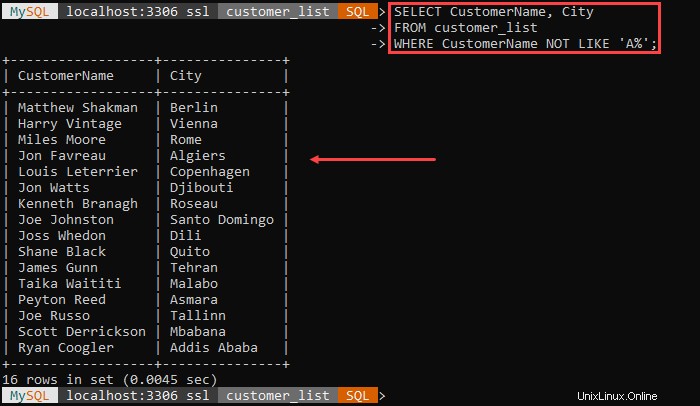
Výstup uvádí všechny zákazníky a jejich město kromě zákazníků, jejichž jméno začíná „A .'
NENÍ REGEXP
Syntaxe pro NOT REGEXP funkce je:
expr NOT REGEXP pat
Funkce provede shodu se vzorem expr řetězec proti pat vzor. Vzorem může být rozšířený regulární výraz.
NOT REGEXP je negací REGEXP .
Pokud expr argument odpovídá pat argument, výstup je 1. V opačném případě je výstup 0. Pokud je některý argument NULL , výstup je NULL .
Například:
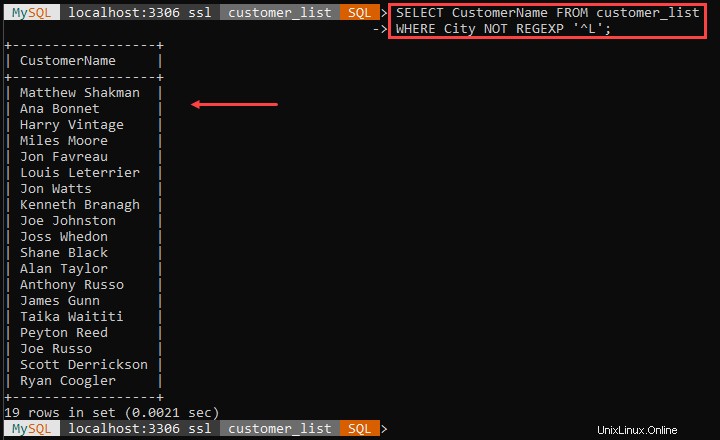
Výše uvedený příklad zobrazuje všechny zákazníky, kteří nežijí ve městech začínajících na L. The '^ Znak ' označuje začátek názvu města.
OCT()
Syntaxe pro OCT() funkce je:
OCT(N)
Funkce vypíše osmičkovou hodnotu zadaného N argument, kde N je BIGINTEGER číslo. Pokud N je NULL , funkce vrátí NULL .
Například:

ORD()
Syntaxe pro ORD() funkce je:
ORD(str)
Funkce najde kód vícebajtového znaku nejvíce vlevo v řetězci. Pokud znak zcela vlevo není vícebajtový, ORD() vrátí hodnotu ASCII znaku.
Funkce vypočítá kód znaku z číselných hodnot bajtů, které jej tvoří. Vzorec použitý pro tuto operaci je:
(1. bajtový kód) + (2. bajtový kód * 256) + (3. bajtový kód * 256^2) ...
Například:

CITACE()
Syntaxe pro QUOTE() funkce je:
QUOTE(str)Funkce vypíše řetězec, který představuje správně escapovanou datovou hodnotu použitelnou v příkazu SQL. Řetězec je uzavřen v jednoduchých uvozovkách a obsahuje zpětné lomítko (\ ) před každou instancí zpětného lomítka (\ ), jednoduchá uvozovka (' ), ASCII NUL a Ctrl+Z .
Pokud str argument je NULL , výstup je NULL .
Například:
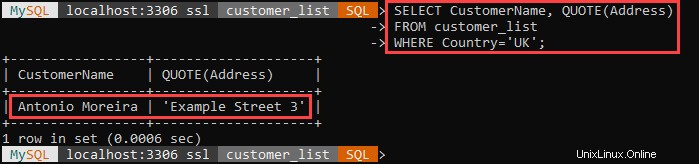
Výše uvedený příklad vybere všechny zákazníky, kteří žijí ve Spojeném království, a jejich adresy uzavře do jednoduchých uvozovek.
REGEXP_LIKE(), REGEXP, RLIKE
Syntaxe pro REGEXP_LIKE() funkce je:
REGEXP_LIKE(expr, pat, [match_type])
Funkce vydá 1, pokud expr řetězec odpovídá výrazu zadanému namísto pat argument. V opačném případě je výstup 0. Pokud expr nebo pat argument je NULL , výstupní hodnota je NULL .
match_type argument je volitelný a představuje řetězec, který může obsahovat některý nebo všechny následující příznaky určující typ shody:
- Shoda rozlišující malá a velká písmena (
c). Pokud je některý z argumentů binární řetězec, zacházejte s argumenty jako s binárními řetězci s rozlišováním velkých a malých písmen.cpříznak znamená, že se rozlišuje malá a velká písmena, i kdyžije také specifikován příznak. - Přiřazování bez rozlišení malých a velkých písmen (
i). Zvládejte argumenty bez rozlišování velkých a malých písmen. - Režim více řádků (
m). Rozpoznejte zakončení řádku v řetězci. Ve výchozím nastavení se shodují zakončení řádků pouze na začátku a na konci řetězcového výrazu. - Příkaz . znak se shoduje se zakončením řádku (
n). Používá se k úpravě . (tečka), aby odpovídaly zakončení řádků. Ve výchozím nastavení . odpovídající zastávky na konci řádku. - Pouze pro Unixové zakončení řádků (
u). Koncovky řádků pouze pro Unix, které rozpoznávají pouze znak nového řádku pomocí operátorů shody ., ^ a $.
Pokud jsou v rámci match_type specifikovány protichůdné příznaky , má přednost ten úplně vpravo.
REGEXP a RLIKE jsou synonyma pro REGEXP_LIKE() .
Například:

V tomto příkladu může regulární výraz zadat jakýkoli znak namísto tečky, takže funkce vydá 1, která označuje shodu.
REGEXP_INSTR()
Syntaxe pro REGEXP_INSTR() funkce je:
REGEXP_INSTR(expr, pat[, pos[, occurrence[, return_option[, match_type]]]])
Funkce vypíše počáteční index podřetězce, který odpovídá expr výraz pat vzor. Pokud není shoda, výstup je 0. Pokud je některý argument NULL , výstup je NULL . Indexy znaků začínají na 1.
Volitelné argumenty jsou:
pos- Zadejte pozici vexprkde začít s hledáním. Pokud je vynechán, výchozí hodnota je 1.occurrence- Určete, který výskyt shody se má hledat. Pokud je vynechán, výchozí hodnota je 1.return_option- Jaký typ pozice vrátit. Pokud je nastaveno na 0,REGEXP_INSTR()vrátí pozici prvního znaku shodného podřetězce. Pokud je nastaveno na 1,REGEXP_INSTR()vrátí pozici po odpovídajícím podřetězci. Pokud je vynechán, výchozí hodnota je 0.match_type- Určuje způsob spárování. Argument je stejný jako vREGEXP_LIKE()a bere stejné příznaky.
Například:

V tomto příkladu existuje shoda a podřetězec začíná na pozici 1.
REGEXP_REPLACE()
Syntaxe pro REGEXP_REPLACE() funkce je:
REGEXP_REPLACE(expr, pat, repl[, pos[, occurrence[, match_type]]])
Funkce nahradí každý výskyt v expr řetězec určený pomocí pat vzor s repl string a vypíše výsledný řetězec. Pokud existuje shoda, výstupem je celý řetězec s náhradami. Pokud neexistuje žádná shoda, výstupem je původní expr tětiva. Pokud je některý argument NULL , výstup je NULL .
Volitelné REGEXP_REPLACE() argumenty jsou:
pos– Pozice vexprkde začít s hledáním. Pokud je vynechán, výchozí hodnota je 1.occurrence- Který výskyt shody nahradit. Pokud je vynechán, výchozí hodnota je 0 a nahradí všechny výskyty.match_type- Určuje způsob spárování. Argument je stejný jako vREGEXP_LIKE()a bere stejné příznaky.
Například:

REGEXP_SUBSTR()
Syntaxe pro REGEXP_SUBSTR() funkce je:
REGEXP_SUBSTR(expr, pat[, pos[, occurrence[, match_type]]])
Funkce vypíše podřetězec expr řetězec, který odpovídá regulárnímu výrazu zadanému pomocí pat vzor. Pokud neexistuje žádná shoda, výsledek je NULL . Pokud je některý argument NULL , výstup je NULL .
Volitelné argumenty jsou:
pos– Pozice vexprkde začít s hledáním. Pokud je vynechán, výchozí hodnota je 1.occurrence- Který výskyt shody nahradit. Pokud je vynechán, výchozí hodnota je 1.match_type- Určuje způsob spárování. Argument je stejný jako vREGEXP_LIKE()a bere stejné příznaky.
Například:

V tomto příkladu výsledek vypíše odpovídající podřetězec ze zadaného expr řetězec.
OPAKOVAT()
Syntaxe pro REPEAT() funkce je:
REPEAT(str,count)
Funkce vypíše řetězec, který opakuje str řetězec count časy. Pokud count argument je menší než 1, funkce vypíše prázdný řetězec. Pokud je některý z argumentů NULL , výsledkem je NULL .
Například:

Ve výše uvedeném příkladu funkce výstupem řetězec skládající se z 'Práce ' řetězec opakovaný šestkrát.
REPLACE()
Syntaxe pro REPLACE() funkce je:
REPLACE(str,from_str,to_str)
Funkce nahradí všechny instance from_str v str řetězec se zadaným to_str tětiva. Tato funkce rozlišuje malá a velká písmena a je bezpečná pro vícebajt.
Například:

REVERSE()
Syntaxe pro REVERSE() funkce je:
REVERSE(str)
Funkce vypíše str řetězec s obráceným pořadím znaků. REVERSE() je vícebajtová funkce.
Například:

RIGHT()
Syntaxe pro RIGHT() funkce je:
RIGHT(str,len)
Funkce zobrazuje len nejvíce vpravo počet znaků z str tětiva. Pokud je některý argument NULL , výsledkem je NULL . RIGHT() je vícebajtová funkce.
Například:

RPAD()
Syntaxe pro RPAD() funkce je:
RPAD(str,len,padstr)
Funkce vypíše zadaný str řetězec, vpravo doplněný padstr řetězec na délku len znaky. str argument je delší než len zkrátí výstup na len znaky.
RPAD() je vícebajtový bezpečný.
Například:

RTRIM()
Syntaxe pro RTRIM() funkce je:
RTRIM(str)
Funkce vypíše str řetězec bez koncových mezer. RTRIM() funkce je vícebajtová bezpečná.
Například:

SOUNDEX(), tj. SOUNDS LIKE
Syntaxe pro SOUNDEX() funkce je:
SOUNDEX(str)
Funkce vygeneruje řetězec soundex, tj. fonetickou reprezentaci vstupu str tětiva. SOUNDEX() function allows users to compare English words that are spelled differently but sound alike.
SOUNDEX() ignores all non-alphabetic characters in the input string and treats all characters outside the A-Z range as vowels.
Důležité: The SOUNDEX() function works well only with strings in English. Results are unreliable for strings in other languages and for strings that use multibyte character sets, including utf-8.
Například:

The (expr1) SOUNDS LIKE (expr2) function is the same as SOUNDEX(expr1) = SOUNDEX(expr2) .
SPACE()
The syntax for the SPACE() function is:
SPACE(N)
The function outputs a string consisting of N number of space characters.
Například:

STRCMP()
The syntax for the STRCMP() function is:
STRCMP(expr1,expr2)The function compares the two expressions and outputs:
0- If the two expressions are the same.-1- If the first expression is smaller than the second depending on the current sort order.1- If the second expression is smaller than the first one.
Například:

In this example, the output is 1 because the second argument is smaller than the first one.
SUBSTRING(), i.e., SUBSTR(), MID()
The syntax for the SUBSTRING() function is:
SUBSTRING(str, pos, length)nebo:
SUBSTRING(str FROM pos FOR length)The function extracts a substring from a string, starting at a specified position.
The length argument is optional and used to return a substring length characters long from the str string, starting at pos position.
The pos argument specifies from which position to extract the substring. If pos is a positive number, the function extracts a substring from the beginning of the string. If pos is a negative number, the function extracts a substring from the end of the string.
Například:

MID(str,pos,length) and SUBSTR() are synonyms for SUBSTRING(str,pos,length) .
SUBSTRING_INDEX()
The syntax for the SUBSTRING_INDEX() function is:
SUBSTRING_INDEX(str,delim,count)
The function outputs a substring from the str string before a specified count number of delim delimiter occurs.
If the count argument is positive, the function outputs everything left of the final delimiter, counting from the left side.
If the count argument is negative, the function outputs everything right of the final delimiter, counting from the right side.
SUBSTRING_INDEX() searches for the delimiter in a case-sensitive fashion, and it is multibyte safe.
Například:
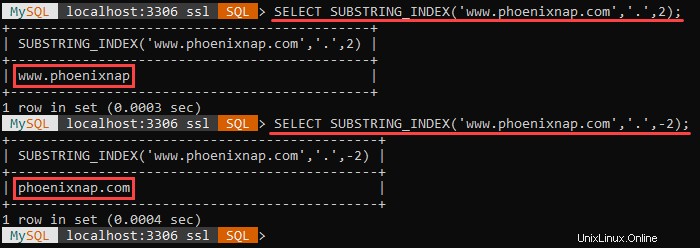
The example above shows the different outputs when the count argument is positive and negative.
TO_BASE64()
The syntax for the TO_BASE64() function is:
TO_BASE64(str)The function encodes a string argument to a base-64 encoded form and returns the result. If the argument isn't a string, the function converts it to a string before base-64 encoding.
If the argument is NULL , the result is NULL .
TO_BASE64() is the reverse of FROM_BASE64() .
Například:

The output is a base-64 encoded string.
TRIM()
The syntax for the TRIM() function is:
TRIM([{BOTH | LEADING | TRAILING} [remstr] FROM] str)
The function removes all remstr prefixes and suffixes from the specified str string and outputs the result.
Unless specifying the BOTH, LEADING ,or TRAILING specifiers, the function assumes BOTH .
The remstr argument is optional, and omitting it removes the space characters from the string.
TRIM() is multibyte safe.
Například:

In this example, the function removes the specified leading prefix from the string.
UPPER(), i.e., UCASE()
The syntax for the UPPER() function is:
UPPER(str)
The function changes all characters of the specified str string to uppercase and outputs the result. The default character set mapping it uses is utf8mb4. UPPER() is multibyte safe.
Například:

The UCASE() function is a synonym for UPPER() .
UNHEX()
The syntax for the UNHEX() function is:
UNHEX(str)The function interprets each pair of characters in a string argument as a hexadecimal number and converts it to the byte represented by the number. The output is a binary result.
If the str argument contains non-hexadecimal digits, the output is NULL . A NULL output can also occur if the argument is a BINARY sloupec.
UNHEX() is the opposite of HEX() . However, you shouldn't use UNHEX() to inverse the HEX() result of numeric arguments. Instead, use the mathematical function CONV(HEX(N),16,10) .
Například:

WEIGHT_STRING()
The syntax for the WEIGHT_STRING() function is:
WEIGHT_STRING(str [AS {CHAR|BINARY}(N)] [flags])str- The input string argument.AS- Optional clause, permits casting the input string to a binary or non-binary string, and to a specific length.flags- Optional argument, currently unused.
The function outputs the weight string for the input str string. The output value represents the string's sorting and comparison value.
If used, the AS BINARY(N) argument measures the length in bytes rather than characters, and right-pads with 0x00 bytes to the specified length.
On the other hand, the AS CHAR(N) argument measures the characters' length and right-pads with spaces to the specified length.
N has a minimum value of 1. If N is less than the input string length, the string is truncated without issuing a warning.
If the input string is a non-binary value (CHAR , VARCHAR , or TEXT ) , the output contains the collation weights for the string. If the input string is a binary value (BINARY , VARBINARY , or BLOB ), the output is the same as the input string because the weight for each byte in a binary string is the byte value.
If the input string is NULL , the output is NULL .
Important:WEIGHT_STRING() is a debugging function intended for internal use and collation testing and debugging. Its behavior is subject to change between different MySQL versions.
Například:

In this example, we used HEX() to display the output because HEX() can display binary results containing nonprinting values in a printable form.