Úvod
Na dnešním trhu může i krátké přerušení služby vést ke ztrátě důvěry zákazníků a nakonec k finančním ztrátám. To platí zejména pro firmy pracující v sektoru, jako je SaaS.
Použití zotavení po havárii jako služby ve vašem obchodním procesu je nezbytné, chcete-li zajistit vysokou dostupnost a kontinuitu podnikání. Failover a failback jsou některé z nejběžněji používaných metod obnovy po havárii.
V tomto kurzu vysvětlíme, co je převzetí služeb při selhání a navrácení služeb při selhání, jak fungují a čím se liší.

Failover vs. Failback:Souhrn
Ať už je to kvůli neočekávanému výpadku, přírodní katastrofě nebo plánované údržbě, jsou chvíle, kdy je produkční prostředí dočasně nedostupné. Failover a failback jsou mechanismy obnovy po havárii, které pomáhají udržovat kontinuitu podnikání v případě náhlého výpadku.
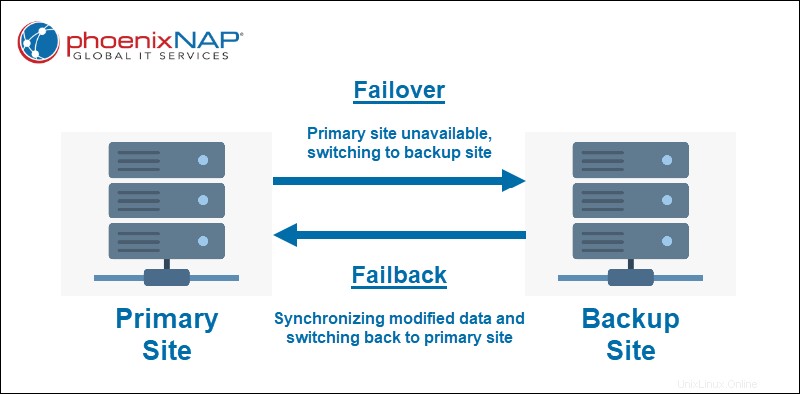
Failover je proces přechodu na určené zařízení pro obnovu zálohy. Obvykle se jedná o web obnovy, který obsahuje replikovanou kopii všech systémů a dat z vašeho primárního produkčního webu. Veškeré změny provedené během převzetí služeb při selhání se uloží do virtuálního úložiště.
Failback je mechanismus kontinuity provozu, který se používá, když je místo primární výroby znovu spuštěno a spuštěno. Produkce je vrácena na své původní (nebo nové) místo během obnovení služeb a veškeré změny uložené ve virtuálním úložišti jsou synchronizovány.
Co je to převzetí služeb při selhání?
Failover je proces bezproblémového přechodu z primárního produkčního místa na místo obnovení zálohy. K převzetí služeb při selhání dojde, když primární server selže v důsledku neočekávané katastrofy nebo v případě plánované údržby.
Aby převzetí služeb při selhání fungovalo, musí existovat záložní server nebo virtuální počítač, který funguje jako systém místa obnovy, připravený nahradit primární místo v případě selhání. Vzhledem k tomu, že převzetí služeb při selhání je základním krokem při obnově po havárii, musí být zálohovací systémy imunní vůči selhání.
U systémů, které vyžadují stálou dostupnost, je vyžadováno úplné zotavení po selhání a po havárii. Na úrovni serveru zálohovací prostředí sleduje "puls" primárního serveru a provede automatické převzetí služeb při selhání, pokud zjistí výpadek.
Jak funguje převzetí služeb při selhání?
Existují dva způsoby, jak nastavit systém převzetí služeb při selhání:aktivní-aktivní a aktivní-pasivní konfigurace (nebo aktivního pohotovostního režimu). Obě nastavení vyžadují ke správnému fungování alespoň dva uzly (servery nebo virtuální počítače).
V aktivní-aktivní nastavení, více uzlů běží současně. To jim umožňuje sdílet pracovní zátěž a zabránit přetížení jednoho uzlu. Pokud jeden uzel přestane fungovat, jeho pracovní zátěž převezmou ostatní aktivní uzly, dokud se znovu neaktivuje.
aktivní-pasivní (aktivní-pohotovostní) nastavení také zahrnuje více uzlů, ale ne všechny jsou aktivní ve stejnou dobu. Jakmile aktivní uzel přestane fungovat, aktivuje se pasivní uzel, který funguje jako uzel přepnutí při selhání. Když primární uzel opět funguje, záložní uzel přepne operace zpět na primární uzel a stane se opět pasivním.
Bez ohledu na metodu převzetí služeb při selhání obě konfigurace vyžadují, aby každý uzel měl identickou konfiguraci. To zajišťuje konzistenci a stabilitu při přepínání mezi weby.
Co je to zpětná vazba?
Failback je proces přepnutí zpět na primární místo po vyřešení plánovaného nebo neplánovaného přerušení. Failback obvykle následuje po převzetí služeb při selhání jako součást plánu obnovy po havárii.
Failback není jediný způsob, jak dokončit převzetí služeb při selhání. Při práci s virtuálními stroji můžete provést trvalé navrácení služeb při selhání, čímž se záložní virtuální stroj stane novým primárním místem.
Jak funguje služba Failback?
Během stavu převzetí služeb při selhání komunikují správci se záložním serverem. Veškeré změny provedené v tomto období se uloží jako údaje o změnách .
Jakmile dojde k navrácení při selhání, synchronizace primárních a obnovovacích stránek zahrnuje zkopírování změn dat z obnovy na primární místo. To zabraňuje potřebě úplné kopie systému, což šetří čas a zvyšuje spolehlivost.
Úspěšné provedení návratu k selhání vyžaduje určitou přípravu. Před přepnutím zpět na primární web zvažte následující kroky:
- Zkontrolujte kvalitu a šířku pásma připojení k primárnímu webu.
- Zkontrolujte, zda všechna data na záložním místě neobsahují potenciální chyby. To je důležité zejména pro kritické soubory a dokumentaci.
- Před spuštěním návratu k selhání důkladně otestujte všechny primární systémy.
- Připravte a implementujte plán obnovení služeb, který minimalizuje prostoje a uživatelské nepohodlí.