Apache Hadoop je open source framework používaný pro distribuované úložiště i distribuované zpracování velkých dat na klastrech počítačů, které běží na komoditních hardwarech. Hadoop ukládá data v Hadoop Distributed File System (HDFS) a zpracování těchto dat se provádí pomocí MapReduce. YARN poskytuje API pro vyžádání a přidělování prostředků v clusteru Hadoop.
Rámec Apache Hadoop se skládá z následujících modulů:
- Hadoop Common
- Hadoop Distributed File System (HDFS)
- PŘÍZE
- MapReduce
Tento článek vysvětluje, jak nainstalovat Hadoop verze 2 na RHEL 8 nebo CentOS 8. Nainstalujeme HDFS (Namenode a Datanode), YARN, MapReduce na cluster s jedním uzlem v Pseudo Distributed Mode, což je distribuovaná simulace na jednom počítači. Každý hadoop démon jako hdfs, yarn, mapreduce atd. poběží jako samostatný/individuální java proces.
V tomto tutoriálu se naučíte:
- Jak přidat uživatele pro prostředí Hadoop
- Jak nainstalovat a nakonfigurovat Oracle JDK
- Jak nakonfigurovat SSH bez hesla
- Jak nainstalovat Hadoop a nakonfigurovat potřebné související xml soubory
- Jak spustit Hadoop Cluster
- Jak získat přístup k webovému uživatelskému rozhraní NameNode a ResourceManager
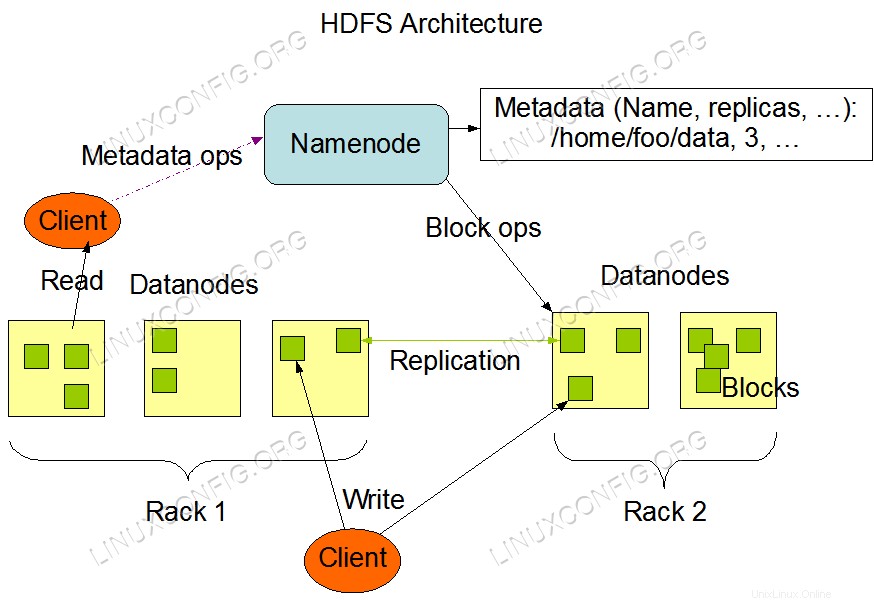 Architektura HDFS.
Architektura HDFS. Požadavky na software a použité konvence
| Kategorie | Požadavky, konvence nebo použitá verze softwaru |
|---|---|
| Systém | RHEL 8 / CentOS 8 |
| Software | Hadoop 2.8.5, Oracle JDK 1.8 |
| Jiné | Privilegovaný přístup k vašemu systému Linux jako root nebo prostřednictvím sudo příkaz. |
| Konvence | # – vyžaduje, aby dané linuxové příkazy byly spouštěny s právy root buď přímo jako uživatel root, nebo pomocí sudo příkaz$ – vyžaduje, aby dané linuxové příkazy byly spouštěny jako běžný neprivilegovaný uživatel |
Přidat uživatele pro prostředí Hadoop
Vytvořte nového uživatele a skupinu pomocí příkazu:
# useradd hadoop# passwd hadoop
[root@hadoop ~]# useradd hadoop[root@hadoop ~]# passwd hadoopZměna hesla pro uživatele hadoop.Nové heslo:Znovu zadejte nové heslo:passwd:všechny ověřovací tokeny byly úspěšně aktualizovány.[root@hadoop ~]# kočka / etc/passwd | grep hadoophadoop:x:1000:1000::/home/hadoop:/bin/bash
Nainstalujte a nakonfigurujte Oracle JDK
Stáhněte a nainstalujte oficiální balíček jdk-8u202-linux-x64.rpm pro instalaci Oracle JDK.
[root@hadoop ~]# rpm -ivh jdk-8u202-linux-x64.rpmwarning:jdk-8u202-linux-x64.rpm:Hlavička V3 RSA/SHA256 Podpis, ID klíče ec551f03:NOKEYVerifying... ## ############################### [100%]Příprava... ########### ##################### [100%]Aktualizace / instalace... 1:jdk1.8-2000:1.8.0_202-fcs ##### ############################ [100%]Rozbalování souborů JAR... tools.jar... plugin.jar... javaws.jar... deploy.jar... rt.jar... jsse.jar... charsets.jar... localedata.jar...
Po instalaci, abyste ověřili, že java byla úspěšně nakonfigurována, spusťte následující příkazy:
[root@hadoop ~]# java -versionjava verze "1.8.0_202" Java(TM) SE Runtime Environment (sestavení 1.8.0_202-b08)Java HotSpot(TM) 64-Bit Server VM (sestavení 25.202-b08, smíšený režim)[root@hadoop ~]# update-alternatives --config javaJe zde 1 program, který poskytuje 'java'. Příkaz výběru-----------------------------------------------* + 1 /usr/java/jdk1.8.0_202-amd64/jre/bin/java
Konfigurace SSH bez hesla
Nainstalujte Open SSH Server a Open SSH Client, nebo pokud jsou již nainstalovány, zobrazí se níže uvedené balíčky.
[root@hadoop ~]# ot./min -qa | grep openssh*openssh-server-7.8p1-3.el8.x86_64openssl-libs-1.1.1-6.el8.x86_64openssl-1.1.1-6.el8.x86_64openssh-clients-7.8p1-3.el64.x p1-3.el8.x86_64openssl-pkcs11-0.4.8-2.el8.x86_64
Vygenerujte páry veřejných a soukromých klíčů pomocí následujícího příkazu. Terminál vás vyzve k zadání názvu souboru. Stiskněte ENTER a pokračujte. Poté zkopírujte veřejné klíče z formuláře id_rsa.pub na authorized_keys .
$ ssh-keygen -t rsa$ cat ~/.ssh/id_rsa.pub>> ~/.ssh/authorized_keys$ chmod 640 ~/.ssh/authorized_keys
[hadoop@hadoop ~]$ ssh-keygen -t rsaGenerování páru veřejného/soukromého rsa klíčů.Zadejte soubor, do kterého se má klíč uložit (/home/hadoop/.ssh/id_rsa):Vytvořený adresář '/home/hadoop /.ssh'.Zadejte přístupové heslo (prázdné pro žádné heslo):Zadejte stejné přístupové heslo znovu:Vaše identifikace byla uložena do /home/hadoop/.ssh/id_rsa.Váš veřejný klíč byl uložen do /home/hadoop/.ssh/ id_rsa.pub. Otisk klíče je:SHA256:H+LLPkaJJDD7B0f0Je/NFJRP5/FUeJswMmZpJFXoelg hadoop@hadoop.sandbox.comNáhodný obrázek klíče je:+---[RSA 2048]----+| .. ..++*o .o|| o .. +.O.+o.+|| + . . * +oo==|| . o o E .oo|| . =.S.* o || . o.o=o || . .. o || .Ó. || o+. |+----[SHA256]-----+[hadoop@hadoop ~]$ cat ~/.ssh/id_rsa.pub>> ~/.ssh/authorized_keys[hadoop@hadoop ~]$ chmod 640 ~/ .ssh/authorized_keys
Ověřte konfiguraci ssh bez hesla pomocí příkazu :
$ ssh
[hadoop@hadoop ~]$ ssh hadoop.sandbox.comWebová konzole:https://hadoop.sandbox.com:9090/ nebo https://192.168.1.108:9090/Poslední přihlášení:So 13. dubna 12:09 :55 2019[hadoop@hadoop ~]$
Nainstalujte Hadoop a nakonfigurujte související soubory xml
Stáhněte a extrahujte Hadoop 2.8.5 z oficiálních stránek Apache.
# wget https://archive.apache.org/dist/hadoop/common/hadoop-2.8.5/hadoop-2.8.5.tar.gz# tar -xzvf hadoop-2.8.5.tar.gz[root@rhel8-sandbox ~]# wget https://archive.apache.org/dist/hadoop/common/hadoop-2.8.5/hadoop-2.8.5.tar.gz--2019-04- 13 11:14:03-- https://archive.apache.org/dist/hadoop/common/hadoop-2.8.5/hadoop-2.8.5.tar.gzResolving archive.apache.org (archive.apache.org )... 163.172.17.199Připojování k archive.apache.org (archive.apache.org)|163.172.17.199|:443... připojeno.Požadavek HTTP odeslán, čeká se na odpověď... 200 OKDélka:246543928 (235M) [ application/x-gzip]Ukládání do:'hadoop-2.8.5.tar.gz'hadoop-2.8.5.tar.gz 100 %[========================================================================================>] 235,12 M 1,47 MB/s za 2 m 53s 2019-04-13 11:16:57 (1,36 MB/s) – 'hadoop-2.8.5 .tar.gz' uloženo [246543928/246543928]Nastavení proměnných prostředí
Upravte
bashrcpro uživatele Hadoop prostřednictvím nastavení následujících proměnných prostředí Hadoop:export HADOOP_HOME=/home/hadoop/hadoop-2.8.5 export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"Zdrojový kód
.bashrcv aktuální relaci přihlášení.zdroj $ ~/.bashrcUpravte soubor
hadoop-env.shsoubor, který je v/etc/hadoopuvnitř instalačního adresáře Hadoop a proveďte následující změny a zkontrolujte, zda chcete změnit nějaké další konfigurace.export JAVA_HOME=${JAVA_HOME:-"/usr/java/jdk1.8.0_202-amd64"} export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-"/home/hadoop/hadoop-2.8.5/etc/hadoop"}Změny konfigurace v souboru core-site.xml
Upravte soubor
core-site.xmls vim nebo můžete použít některý z editorů. Soubor je pod/etc/hadoopuvnitřhadoopdomovský adresář a přidejte následující položky.<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop.sandbox.com:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/hadoop/hadooptmpdata</value> </property> </configuration>Kromě toho vytvořte adresář pod
hadoopdomovská složka.$ mkdir hadooptmpdataZměny konfigurace v souboru hdfs-site.xml
Upravte
hdfs-site.xmlkterý je přítomen pod stejným umístěním, tj./etc/hadoopuvnitřhadoopinstalační adresář a vytvořteNamenode/Datanodeadresáře podhadoopdomovský adresář uživatele.$ mkdir -p hdfs/namenode$ mkdir -p hdfs/datanode<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.name.dir</name> <value>file:///home/hadoop/hdfs/namenode</value> </property> <property> <name>dfs.data.dir</name> <value>file:///home/hadoop/hdfs/datanode</value> </property> </configuration>Změny konfigurace v souboru mapred-site.xml
Zkopírujte soubor
mapred-site.xmlzmapred-site.xml.templatepomocícpa poté upravtemapred-site.xmlumístěn v/etc/hadooppodhadoopinstilační adresář s následujícími změnami.$ cp mapred-site.xml.template mapred-site.xml<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>Změny konfigurace v souboru yarn-site.xml
Upravte
yarn-site.xmls následujícími položkami.<configuration> <property> <name>mapreduceyarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>Spuštění klastru Hadoop
Před prvním použitím jmenný uzel naformátujte. Jako uživatel hadoop spusťte níže uvedený příkaz k formátování Namenode.
$ hdfs namenode -format[hadoop@hadoop ~]$ hdfs namenode -format19/04/13 11:54:10 INFO namenode.NameNode:STARTUP_MSG:/************************ *****************************************STARTUP_MSG:Počáteční NameNodeSTARTUP_MSG:uživatel =hadoopSTARTUP_MSG:hostitel =hadoop.sandbox.com/192.168.1.108STARTUP_MSG:args =[-formát]STARTUP_MSG:verze =2.8.519/04/13 11:54:17 INFO namenode.FSNamesystem:dfs.namenode.safect =bezpečný režim. 0,999000012874603319/04/13 11:54:17 INFO namenode.FSNamesystem:dfs.namenode.safemode.min.datanodes =019/04/13 11:54:17 INFO namenode.FSName.system. 04/13 11:54:18 INFO metrics.TopMetrics:NNTtop conf:dfs.namenode.top.window.num.buckets =1019/04/13 11:54:18 INFO metrics.TopMetrics:NNTtop conf:dfs.namenode. top.num.users =1019/04/13 11:54:18 INFO metrics.TopMetrics:NNTtop conf:dfs.namenode.top.windows.minutes =1,5,2519/04/13 11:54:18 INFO namenode .FSNamesystem:Opakovat mezipaměť na namenode je povolena19/04/13 11:54:18 INFO namenode.FS Namesystem:Mezipaměť pro opakování použije 0,03 z celkové haldy a doba vypršení záznamu mezipaměti pro opakování je 600 000 milis19/04/13 11:54:18 INFO util.GSet:Výpočetní kapacita pro mapu NameNodeRetryCache19/04/13 11:54:18 INFO util. GSet:Typ VM =64-bit19/04/13 11:54:18 INFO util.GSet:0,029999999329447746 % max. paměť 966,7 MB =297,0 KB19/04/13 11:54:18 kapacita INFO^5 GSet:18 =32768 záznamů19/04/13 11:54:18 INFO namenode.FSImage:Přiděleno nové BlockPoolId:BP-415167234-192.168.1.108-155514205816719/04/13:opytorage INFO/13 /oopytorage INFO:5had/181:5 /hdfs/namenode byl úspěšně naformátován.19/04/13 11:54:18 INFO namenode.FSImageFormatProtobuf:Ukládání souboru obrázku /home/hadoop/hdfs/namenode/current/fsimage.ckpt_0000000000000000901 pomocí komprese:11 54:18 INFO namenode.FSImageFormatProtobuf:Soubor obrázku /home/hadoop/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 o velikosti 323 bajtů uloženo za 0 sekund.19/04/13 11:54name. anager:Chystáte se zachovat 1 obrázky s txid>=019/04/13 11:54:18 INFO util.ExitUtil:Ukončení se stavem 019/04/13 11:54:18 INFO namenode.NameNode:SHUTDOWN_MSG:/*** ******************************************************* *******SHUTDOWN_MSG:Vypínání NameNode na hadoop.sandbox.com/192.168.1.108****************************** *********************************/Jakmile bude Namenode naformátován, spusťte HDFS pomocí
start-dfs.shskript.$ start-dfs.sh[hadoop@hadoop ~]$ start-dfs.shSpouštění jmenných uzlů na [hadoop.sandbox.com]hadoop.sandbox.com:počáteční jmenný uzel, přihlášení do /home/hadoop/hadoop-2.8.5/logs/hadoop- hadoop-namenode-hadoop.sandbox.com.outhadoop.sandbox.com:spouštění datového uzlu, přihlašování do /home/hadoop/hadoop-2.8.5/logs/hadoop-hadoop-datanode-hadoop.sandbox.com.outSpouštění sekundárních jmenných uzlů [ 0.0.0.0]Autentičnost hostitele „0.0.0.0 (0.0.0.0)“ nelze zjistit. Otisk klíče ECDSA je SHA256:e+NfCeK/kvnignWDHgFvIkHjBWwghIIjJkfjygR7NkI. Opravdu chcete pokračovat v připojování (yyes no/ yes0.0.0.0:Varování:Trvale přidáno '0.0.0.0' (ECDSA) do seznamu známých hesel hosts.hadoop@0.0.0.0:0.0.0.0:počínaje sekundárním jménemnode, přihlašování do /home/hadoop/hadoop- 2.8.5/logs/hadoop-hadoop-secondarynamenode-hadoop.sandbox.com.outChcete-li spustit služby YARN, musíte spustit skript pro zahájení příze, tj.
start-yarn.sh$ start-yarn.sh[hadoop@hadoop ~]$ start-yarn.shstarting yarn daemonsspuštění resourcemanager, přihlášení do /home/hadoop/hadoop-2.8.5/logs/yarn-hadoop-resourcemanager-hadoop.sandbox.com.outhadoop.sandbox. com:spuštění nodemanager, přihlášení do /home/hadoop/hadoop-2.8.5/logs/yarn-hadoop-nodemanager-hadoop.sandbox.com.outChcete-li ověřit, zda jsou všechny služby/démony Hadoop úspěšně spuštěny, můžete použít
jpspříkaz.$ jps2033 NameNode2340 SecondaryNameNode2566 ResourceManager2983 Jps2139 DataNode2671 NodeManagerNyní můžeme zkontrolovat aktuální verzi Hadoop, můžete použít níže uvedený příkaz:
Verze $ hadoopnebo
Verze $ hdfs[hadoop@hadoop ~]$ verze hadoopHadoop 2.8.5Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 0b8464d75227fcee2c6e7f2410377b3d58Compiled3d50ComTcompiled31d50 protoc 2.5.0Ze zdroje s kontrolním součtem 9942ca5c745417c14e318835f420733Tento příkaz byl spuštěn pomocí /home/hadoop/hadoop-2.8.5/share/hadoop/common/hadoop-common-2.8.5.Hadoopsversion~2.8.5.hf5jar[pubhado.version] https://git-wip-us.apache.org/repos/asf/hadoop.git -r 0b8464d75227fcee2c6e7f2410377b3d53d3d5f8Compiled tím jdu na 2018-09-10T03:32ZCompiled s protoc 2.5.0From zdroje s vedením kontrolní součet 9942ca5c745417c14e318835f420733This byla provedena s použitím / home / hadoop/hadoop-2.8.5/share/hadoop/common/hadoop-common-2.8.5.jar[hadoop@hadoop ~]$Rozhraní příkazového řádku HDFS
Pro přístup k HDFS a vytvoření některých adresářů v horní části DFS můžete použít HDFS CLI.
$ hdfs dfs -mkdir /testdata$ hdfs dfs -mkdir /hadoopdata$ hdfs dfs -ls /[hadoop@hadoop ~]$ hdfs dfs -ls /Nalezeno 2 položekdrwxr-xr-x - hadoop supergroup 0 2019-04-13 11:58 /hadoopdatadrwxr-xr-x - hadoop supergroup 0 2019-114-11 :59 /testdataPřístup k Namenode a YARN z prohlížeče
K webovému uživatelskému rozhraní pro NameNode a YARN Resource Manager můžete přistupovat prostřednictvím libovolného z prohlížečů, jako je Google Chrome/Mozilla Firefox.
Webové uživatelské rozhraní Namenode –
http://<hadoop cluster hostname/IP address>:50070Webové uživatelské rozhraní namenode.
Podrobné informace o HDFS.
Procházení adresářů HDFS.
Webové rozhraní YARN Resource Manager (RM) zobrazí všechny běžící úlohy v aktuálním klastru Hadoop.
Webové uživatelské rozhraní Správce prostředků –
http://<hadoop cluster hostname/IP address>:8088Webové uživatelské rozhraní správce zdrojů (YARN).
Závěr
Svět v současnosti mění způsob, jakým funguje, a Big-data hrají v této fázi hlavní roli. Hadoop je framework, který nám usnadňuje život při práci na velkých souborech dat. Zlepšení jsou na všech frontách. Budoucnost je vzrušující.
Jak nainstalovat redmine na RHEL 8 / CentOS 8 Linux Jak nainstalovat a nastavit ukázkovou službu s xinetd na RHEL 8 / CentOS 8 LinuxCent OS