
V tomto tutoriálu vám ukážeme, jak nainstalovat Apache Spark na server CentOS 7. Pro ty z vás, kteří nevěděli, Apache Spark je rychlý a univerzální clusterový výpočetní systém . Poskytuje API na vysoké úrovni v Javě, Scale a Pythonu a také optimalizovaný engine, který podporuje celkové grafy provádění. Podporuje také bohatou sadu nástrojů vyšší úrovně včetně Spark SQL pro SQL a zpracování strukturovaných informací, MLlib pro stroj učení, GraphX pro zpracování grafů a Spark Streaming.
Tento článek předpokládá, že máte alespoň základní znalosti Linuxu, víte, jak používat shell, a co je nejdůležitější, hostujete svůj web na vlastním VPS. Instalace je poměrně jednoduchá a předpokládá, že běží v účtu root, pokud ne, možná budete muset přidat 'sudo ‘ k příkazům pro získání oprávnění root. Ukážu vám krok za krokem instalaci Apache Spark na server CentOS 7.
Nainstalujte Apache Spark na CentOS 7
Krok 1. Nejprve začněme tím, že zajistíme, aby byl váš systém aktuální.
yum clean all yum -y install epel-release yum -y update
Krok 2. Instalace Java.
Instalace java pro požadavek install apache-spark:
yum install java -y
Po instalaci zkontrolujte verzi Java:
java -version
Krok 3. Instalace Scala.
Spark nainstaluje Scala během instalačního procesu, takže se musíme ujistit, že jsou přítomny Java a Python:
wget http://www.scala-lang.org/files/archive/scala-2.10.1.tgz tar xvf scala-2.10.1.tgz sudo mv scala-2.10.1 /usr/lib sudo ln -s /usr/lib/scala-2.10.1 /usr/lib/scala export PATH=$PATH:/usr/lib/scala/bin
Po instalaci zkontrolujte verzi scala:
scala -version
Krok 4. Instalace Apache Spark.
Nainstalujte Apache Spark pomocí následujícího příkazu:
wget http://www-eu.apache.org/dist/spark/spark-2.2.1/spark-2.2.1-bin-hadoop2.7.tgz tar -xzf spark-2.2.1-bin-hadoop2.7.tgz export SPARK_HOME=$HOME/spark-2.2.1-bin-hadoop2.7 export PATH=$PATH:$SPARK_HOME/bin
Před spuštěním jiskry nastavte některé proměnné prostředí:
echo 'export PATH=$PATH:/usr/lib/scala/bin' >> .bash_profile echo 'export SPARK_HOME=$HOME/spark-2.2.1-bin-hadoop2.6' >> .bash_profile echo 'export PATH=$PATH:$SPARK_HOME/bin' >> .bash_profile
Samostatný cluster Spark lze spustit ručně, tj. spuštěním spouštěcího skriptu na každém uzlu, nebo jednoduše pomocí dostupných spouštěcích skriptů. Pro testování můžeme spustit hlavní a podřízené démony na stejném počítači:
./sbin/start-master.sh
Krok 5. Nakonfigurujte bránu firewall pro Apache Spark.
firewall-cmd --permanent --zone=public --add-port=6066/tcp firewall-cmd --permanent --zone=public --add-port=7077/tcp firewall-cmd --permanent --zone=public --add-port=8080-8081/tcp firewall-cmd --reload
Krok 6. Přístup k Apache Spark.
Apache Spark bude ve výchozím nastavení k dispozici na portu HTTP 7077. Otevřete svůj oblíbený prohlížeč a přejděte na http://yourdomain.com:7077 nebo http://your-server-ip:7077 a dokončete požadované kroky k dokončení instalace.
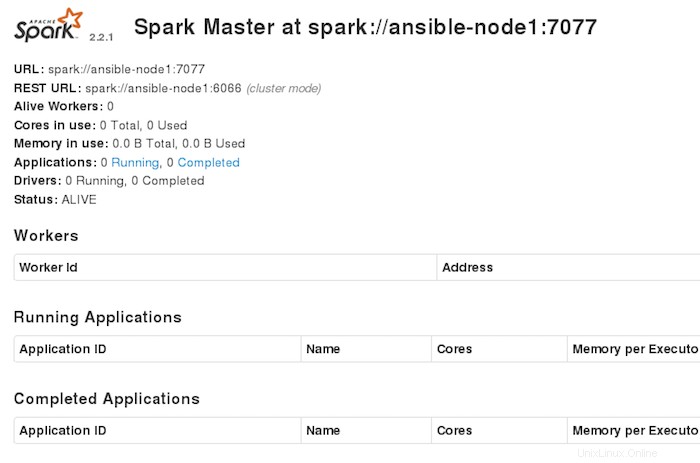
Blahopřejeme! Úspěšně jste nainstalovali Apache Spark na CentOS 7. Děkujeme, že jste použili tento návod k instalaci Apache Spark na systémy CentOS 7. Pro další nápovědu nebo užitečné informace vám doporučujeme zkontrolovat oficiální Apache Web Spark.