Přátelé pokračují s pokročilým know-how a řešením problémů na glusterfs. V tomto článku máme 3 node cluster běžící na glusterfs3.4. Níže jsou uvedeny kroky, které se používají při odstraňování problémů s glusterfs.
Krok 1 :Zkontrolujte stav a informace o objemu Gluster.

[root@gluster1 ~]# gluster volume info
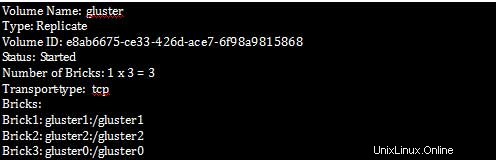
Krok 2 :Pro ověření všech podrobností replikace v Bricks.
Níže uvedené příkazy zobrazí úplnou statistiku toho, jaká data byla replikována a kolik se má replikovat, a to kontrolou velikosti celkového volného místa na disku.
[root@gluster1 ~]# gluster volume status all detail
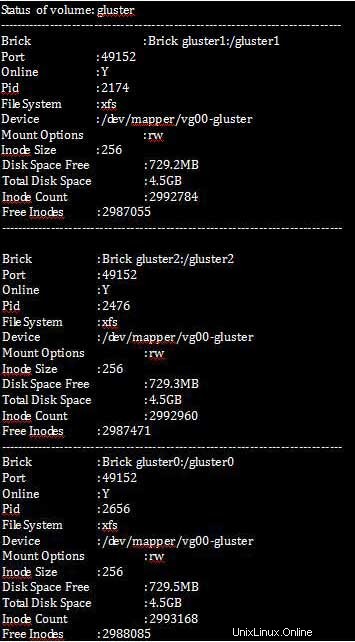
Krok 3 :Nyní potřebujeme mít určitou konfiguraci, abychom zlepšili výkon a léčebné vlastnosti glusterfů.
# gluster volume set gluster cluster.min-free-disk 5% # gluster volume set cluster.rebalance-stats on # gluster volume set cluster.readdir-optimize on # gluster volume set cluster.background-self-heal-count 20 # gluster volume set cluster.metadata-self-heal on # gluster volume set cluster.data-self-heal on # gluster volume set cluster.entry-self-heal: on # gluster volume set cluster.self-heal-daemon on # gluster volume set cluster.heal-timeout 500 # gluster volume set cluster.self-heal-window-size 2 # gluster volume set cluster.data-self-heal-algorithm diff # gluster volume set cluster.eager-lock on # gluster volume set cluster.quorum-type auto # gluster volume set cluster.self-heal-readdir-size 2KB # gluster volume set network.ping-timeout 5
Poté spusťte:
# service glusterd restart
Poté, co jsme nastavili vlastnosti clusteru, můžeme zkontrolovat informace o svazku, jak je uvedeno níže:
[root@gluster1 ~]# gluster volume info
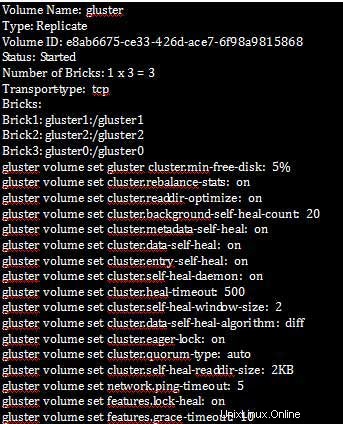
[root@gluster1 ~]# gluster volume status
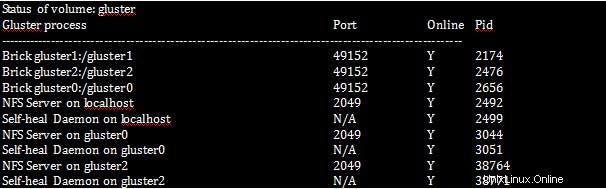
Vezměte prosím na vědomí, že démon Self-heal by měl běžet na každém systému v clusteru, protože je zodpovědný za léčení v případě, že některý uzel bude nějakou dobu mimo provoz z clusteru.
Krok 4 :Nyní odeberte stroj gluster0 z clusteru.
Odpojte svazek namontovaný na počítači gluster0:
[root@gluster0 ~]# umount /mnt [root@gluster1 ~]# gluster volume remove-brick gluster replica 2 gluster0:/gluster0 commit
informace o objemu clusteru (pro ověření):
[root@gluster1 ~]# gluster volume info
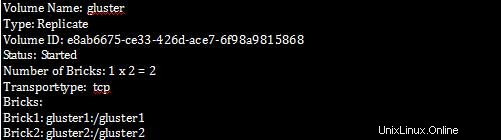
Na gluster1 spusťte následující příkaz:
# gluster peer detach gluster0
cihla serveru gluster0 je odstraněna z clusteru.