Pracuji na částečný úvazek jako datový auditor. Představte si mě jako korektora, který pracuje spíše s tabulkami dat než se stránkami prózy. Tabulky jsou exportovány z relačních databází a mají obvykle poměrně skromnou velikost:100 000 až 1 000 000 záznamů a 50 až 200 polí.
Nikdy jsem neviděl tabulku dat bez chyb. Nepořádek se neomezuje, jak si možná myslíte, na duplikování záznamů, pravopisné a formátovací chyby a datové položky umístěné ve špatném poli. Také nacházím:
- nefunkční záznamy rozložené na několik řádků, protože datové položky měly vložené zalomení řádků
- datové položky v jednom poli nesouhlasí s datovými položkami v jiném poli ve stejném záznamu
- záznamy se zkrácenými datovými položkami, často proto, že velmi dlouhé řetězce byly nařezány do polí s limitem 50 nebo 100 znaků
- Chyby kódování znaků produkující bláboly známé jako mojibake
- neviditelné řídicí znaky, z nichž některé mohou způsobit chyby při zpracování dat
- náhradní znaky a záhadné otazníky vložené posledním programem, který nerozuměl kódování znaků dat
Odstranění těchto problémů není těžké, ale existují netechnické překážky, které jim brání. První je přirozená neochota každého řešit chyby v datech. Než uvidím tabulku, vlastníci nebo správci dat možná prošli všemi pěti fázemi Data Grief:
- V našich datech nejsou žádné chyby.
- No, možná je tam pár chyb, ale nejsou tak důležité.
- OK, je tam hodně chyb; přimějeme naše interní lidi, aby se s nimi vypořádali.
- Začali jsme opravovat několik chyb, ale je to časově náročné. uděláme to při migraci na nový databázový software.
- Neměli jsme čas vyčistit data při přesunu do nové databáze; mohla by se nám hodit pomoc.
Druhým přístupem blokujícím pokrok je přesvědčení, že čištění dat vyžaduje specializované aplikace – buď drahé proprietární programy, nebo vynikající open source program OpenRefine. Aby se vypořádali s problémy, které specializované aplikace nedokážou vyřešit, mohou správci dat požádat o pomoc programátora – někoho, kdo umí Python nebo R.
Ale audit a čištění dat obecně nevyžadují specializované aplikace. Datové tabulky ve formátu prostého textu existují již mnoho desetiletí, stejně jako nástroje pro zpracování textu. Otevřete prostředí Bash a máte sadu nástrojů nabitou výkonnými textovými procesory, jako je grep , cut , paste , sort , uniq , tr a awk . Jsou rychlé, spolehlivé a snadno se používají.
Veškerý audit dat provádím na příkazovém řádku a mnoho svých triků pro audit dat jsem umístil na web „kuchařky“. Operace, které pravidelně ukládám jako funkce a skripty shellu (viz příklad níže).
Ano, přístup z příkazového řádku vyžaduje, aby data, která mají být auditována, byla exportována z databáze. A ano, výsledky auditu je třeba později v databázi upravit, nebo (pokud to databáze dovolí) je třeba importovat vyčištěné datové položky jako náhradu za ty chaotické.
Ale výhody jsou pozoruhodné. awk zpracuje několik milionů záznamů během několika sekund na spotřebitelském stolním počítači nebo notebooku. Nekomplikované regulární výrazy najdou všechny chyby v datech, jaké si dokážete představit. A to vše se bude dít bezpečně venku struktura databáze:Audit z příkazového řádku nemůže ovlivnit databázi, protože pracuje s daty uvolněnými z jejího databázového vězení.
Čtenáři, kteří trénovali na Unixu, se v tuto chvíli budou samolibě usmívat. Pamatují si, jak před mnoha lety manipulovali s daty na příkazovém řádku právě těmito způsoby. Od té doby se stalo to, že výkon procesoru a RAM se ohromně zvýšily a standardní nástroje příkazového řádku byly podstatně efektivnější. Audit dat nebyl nikdy rychlejší ani jednodušší. A nyní, když Microsoft Windows 10 může spouštět programy Bash a GNU/Linux, uživatelé Windows mohou ocenit motto Unixu a Linuxu pro zacházení s chaotickými daty:Zachovejte klid a otevřete terminál.

Příklad
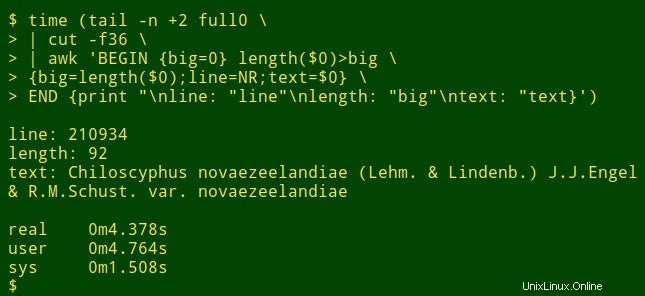
Předpokládejme, že chci najít nejdelší datovou položku v určitém poli velkého stolu. Ve skutečnosti to není úkol auditu dat, ale ukáže, jak fungují nástroje shellu. Pro demonstrační účely použiji tabulku full0 oddělenou tabulátory , který má 1 122 023 záznamů (plus řádek záhlaví) a 49 polí, a já se podívám do pole číslo 36. (Čísla polí získám s funkcí vysvětlenou na webu mé kuchařky.)
Příkaz začíná pomocí tail pro odstranění řádku záhlaví z full0 . Výsledek je přenesen do cut , který extrahuje dekapitované pole 36. Další v pořadí je awk . Zde proměnná big je inicializováno na hodnotu 0; pak awk testuje délku datové položky v prvním záznamu. Pokud je délka větší než 0, awk resetuje big na novou délku a uloží číslo řádku (NR) do proměnné line a celou datovou položku v proměnné text . awk poté zpracuje postupně každý ze zbývajících 1 122 022 záznamů a resetuje tři proměnné, když najde delší datovou položku. Nakonec vytiskne přehledně oddělený seznam čísel řádků, délku datové položky a plný text nejdelší datové položky. (V následujícím kódu byly příkazy pro přehlednost rozděleny na několik řádků.)
<code>tail -n +2 full0 \
> | cut -f36 \
> | awk 'BEGIN {big=0} length($0)>big \
> {big=length($0);line=NR;text=$0} \
> END {print "\nline: "line"\nlength: "big"\ntext: "text}' </code>
Jak dlouho to trvá? Asi 4 sekundy na mé ploše (core i5, 8 GB RAM):
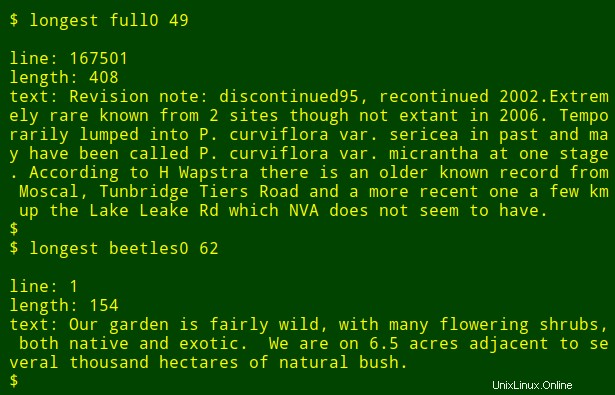
Nyní k té úhledné části:Ten dlouhý příkaz mohu vložit do funkce shellu, longest , jehož argumentem je název souboru ($1) a číslo pole ($2) :

Poté mohu znovu spustit příkaz jako funkci a najít nejdelší datové položky v jiných polích a v jiných souborech, aniž bych si musel pamatovat, jak je příkaz napsán:
Jako poslední vylepšení mohu do výstupu přidat název očíslovaného pole, které hledám. K tomu používám head Chcete-li extrahovat řádek záhlaví tabulky, přesuňte tento řádek do tr převést tabulátory na nové řádky a výsledný seznam převést na tail a head vytisknout $2th název pole v seznamu, kde $2 je argument čísla pole. Název pole je uložen v proměnné shellu field a předán awk pro tisk jako interní awk proměnná fld .
<code>longest() { field=$(head -n 1 "$1" | tr '\t' '\n' | tail -n +"$2" | head -n 1); \
tail -n +2 "$1" \
| cut -f"$2" | \
awk -v fld="$field" 'BEGIN {big=0} length($0)>big \
{big=length($0);line=NR;text=$0}
END {print "\nfield: "fld"\nline: "line"\nlength: "big"\ntext: "text}'; }</code> 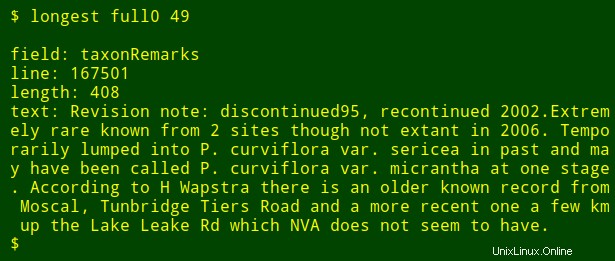
Všimněte si, že pokud hledám nejdelší datovou položku v několika různých polích, stačí stisknout šipku nahoru a získat poslední longest příkaz, potom backspace číslo pole a zadejte nové.