Regulární výrazy mohou být jedním z nejmocnějších nástrojů ve vaší sadě nástrojů jako uživatel Linuxu, správce systému nebo dokonce jako programátor. Může to být také jedna z nejnáročnějších věcí, které je třeba se naučit, ale také nemusí! I když existuje nekonečně mnoho způsobů, jak napsat výraz, nemusíte se učit každý jednotlivý přepínač a příznak. V tomto krátkém návodu vám ukážu několik jednoduchých způsobů, jak používat regulární výrazy, díky nimž budete během chvilky spuštěni, a podělím se o některé navazující zdroje, které z vás udělají mistra regulárního výrazu, pokud jím chcete být.
Rychlý přehled
Regulární výrazy, také označované jako vzory „regulárních výrazů“ nebo dokonce „běžné příkazy“, jsou jednoduše „sekvence znaků, které definují vzor vyhledávání“. Myšlenka vznikla v 50. letech 20. století, kdy Stephen Cole Kleene napsal popis myšlenky, kterou nazval „regulárním jazykem“, jejíž část se stala známou jako „Kleeneův teorém“. Na velmi vysoké úrovni říká, že pokud lze definovat prvky jazyka, lze zapsat výraz tak, aby odpovídal vzorům v tomto jazyce.
Další zdroje pro Linux
- Cheat pro příkazy Linuxu
- Cheat sheet pro pokročilé příkazy systému Linux
- Bezplatný online kurz:Technický přehled RHEL
- Síťový cheat pro Linux
- Cheat sheet SELinux
- Cheat pro běžné příkazy pro Linux
- Co jsou kontejnery systému Linux?
- Naše nejnovější články o Linuxu
Od té doby byly regulární výrazy součástí i těch nejstarších unixových programů, včetně vi, sed, awk, grep a dalších. Slovo grep je ve skutečnosti odvozeno od příkazu, který byl použit v nejstarším editoru „ed“, konkrétně g/re/p , což v podstatě znamená "globálně vyhledat tento regulární výraz a vytisknout řádky." Skvělé!
Proč potřebujeme regulární výrazy
Jak bylo zmíněno výše, regulární výrazy se používají k definování vzoru, který nám pomáhá najít nebo najít objekty, které tomuto vzoru odpovídají. Tyto objekty mohou být soubory v souborovém systému při použití find například příkaz nebo blok textu v souboru, který bychom mohli prohledávat například pomocí grep, awk, vi nebo sed.
Začněte se základy
Začněme úplně od začátku; je to velmi dobré místo, kde začít.
Zdá se, že první regulární výraz, který se každý naučí, je pravděpodobně ten, který již znáte a neuvědomili jste si, co to bylo. Chtěli jste někdy vytisknout seznam souborů v adresáři, ale byl příliš dlouhý? Možná jste viděli někoho psát \*.gif k zobrazení seznamu obrázků GIF v adresáři, například:
$ ls *.gif
To je regulární výraz!
Při psaní regulárních výrazů mají určité znaky zvláštní význam, který nám umožňuje přejít od přiřazování pouze znaků k přiřazování celých sad znaků. V tomto případě * znak, také nazývaný "hvězda" nebo "splat", nahrazuje názvy souborů a umožňuje vám porovnat všechny soubory končící na .gif .
Vyhledat vzory v souboru
Dalším krokem ve vašem školení regulárních výrazů je hledání vzorů v souboru, zejména použití vzoru nahrazení k provádění rychlých změn.
Dva běžné způsoby, jak toho dosáhnout, jsou:
- K otevření souboru, vyhledání vzoru a provedení změny použijte vi (i automaticky pomocí nahradit).
- K programovému vyhledávání v souboru a provedení změny použijte „editor streamu“, neboli sed.
Začněme tím, že se naučíme nějaký regulární výraz pomocí vi k úpravě následujícího souboru:
Rychlá hnědá liška přeskočila líného psa.
Jednoduchý test
Tvrdší test
Extrémní testovací případ
ABC 123 abc 567
Pes je línýNyní, když je tento soubor otevřený ve vi, podívejme se na několik příkladů regulárních výrazů, které nám pomohou najít nějaké odpovídající řetězce uvnitř a dokonce je automaticky nahradit.
Abychom to usnadnili, nastavme vi tak, aby ignorovala malá a velká písmena. Zadejte
set icpovolit vyhledávání bez rozlišení velkých a malých písmen.Nyní, chcete-li začít hledat ve vi, zadejte
/znak následovaný vaším vyhledávacím vzorem.Hledejte věci na začátku nebo na konci řádku
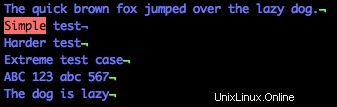
Chcete-li najít řádek, který začíná „Simple“, použijte tento vzor regulárního výrazu:
/^JednoduchéVšimněte si na obrázku níže, že je zvýrazněn pouze řádek začínající „Simple“. Symbol karátů (
^) je ekvivalentem regulárního výrazu pro "začíná na."
Dále použijeme
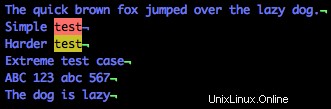
$symbol, který je v regulárním výrazu "končí na."/test$
Vidíte, jak zvýrazní oba řádky, které končí „testem“? Všimněte si také, že čtvrtý řádek obsahuje slovo test, ale ne na konci, takže tento řádek není zvýrazněn.
To je síla regulárních výrazů, která vám dává možnost rychle prohlížet velké množství shod s lehkostí, ale konkrétně se vrtat pouze u přesných shod.
Test frekvence výskytu
Chcete-li dále rozšířit své dovednosti v regulárních výrazech, pojďme se podívat na některé běžnější speciální znaky, které nám umožňují hledat nejen odpovídající text, ale také vzory shod.
Znaky podle frekvence:
| Postava | Význam | Příklad |
|---|---|---|
* | Nula nebo více | ab* – písmeno a následuje nula nebo více b 's |
+ | Jedna nebo více | ab+ – písmeno a následuje jedno nebo více b 's |
? | Nula nebo jedna | ab? – nula nebo pouze jedno b |
{n} | Máte-li číslo, najděte přesně toto číslo | ab{2} – písmeno a následují přesně dvě b 's |
{n,} | Máte-li číslo, najděte alespoň toto číslo | ab{2,} – písmeno a následují alespoň dvě b 's |
{n,y} | Za předpokladu dvou čísel najděte rozsah tohoto čísla | ab{1,3} – písmeno a následuje mezi jedním a třemi b 's |
Najít třídy znaků
Dalším krokem v trénování regulárních výrazů je použití tříd znaků v našem porovnávání vzorů. Zde je důležité poznamenat, že tyto třídy lze kombinovat buď jako seznam, například [a,d,x,z] nebo jako rozsah, například [a-z] a že znaky obvykle rozlišují velká a malá písmena.
Abychom tuto práci viděli ve vi, budeme muset vypnout ignorování velikosti písmen, které jsme nastavili dříve. Napište:set noic znovu vypnout ignorování velkých a malých písmen.
Některé běžné třídy znaků, které se používají jako rozsahy, jsou:
- a-z – všechna malá písmena
- A–Z – všechny znaky VELKÉ
- 0-9 – čísla
Nyní zkusme hledání podobné tomu, které jsme spustili dříve:
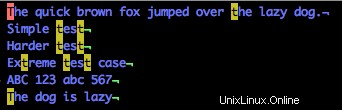
/tT
Všimli jste si, že nic nenachází? Je to proto, že předchozí regulární výraz hledá přesně „tT“. Pokud toto nahradíme:
/[tT]
Uvidíme, že malá i VELKÁ T jsou v dokumentu shodná.
Nyní spojme dohromady několik rozsahů tříd a uvidíme, co dostaneme. Zkuste:
/[A-Z1-3]
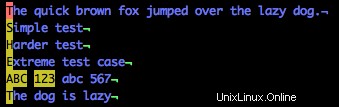
Všimněte si, že jsou zvýrazněna velká písmena a 123, nikoli však malá písmena (včetně konce pátého řádku).
Příznaky
Posledním krokem vašeho počátečního školení regulárních výrazů je porozumět příznakům, které existují, abyste mohli hledat speciální typy znaků, aniž byste je museli uvádět v rozsahu.
.– jakýkoli znak\s– mezera\w– slovo\d– číslice (číslo)
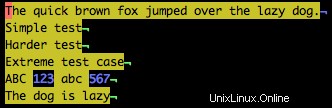
Chcete-li například najít všechny číslice v ukázkovém textu, použijte:
/\d
Všimněte si v příkladu níže, že všechna čísla jsou zvýrazněna.
Chcete-li shodovat s opakem, obvykle používáte stejný příznak, ale VELKÝMI PÍSMENY. Například:
\S– není prostor\W– ani slovo\D– ne číslice
Všimněte si v níže uvedeném příkladu pomocí \D , všechny znaky KROMĚ čísel jsou zvýrazněny.
Vyhledávání pomocí sed
Rychlá poznámka k sed:Je to editor streamů, což znamená, že neinteragujete s uživatelským rozhraním. Vezme proud přicházející na jednu stranu a zapíše jej na druhou stranu.
Použití sed je velmi podobné jako vi, až na to, že mu dáte regulární výraz, který se má vyhledat a nahradit, a vrátí výstup. Například:
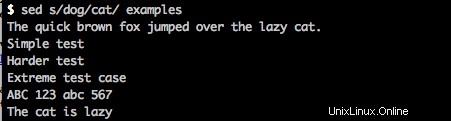
příklady s/pes/kočka/
vrátí na obrazovku následující:
Pokud chcete tento soubor uložit, je to jen o něco složitější. Budete muset zřetězit několik příkazů dohromady, abyste a) zapsali tento soubor ab) jej zkopírovali přes první soubor.
Chcete-li to provést, zkuste:
sed s/pes/cat/ příklady> temp.out; mv temp.out příklady
Nyní, když se podíváte na své examples soubor, uvidíte, že slovo "pes" bylo nahrazeno.
Rychlá hnědá liška přeskočila línou kočku.
Jednoduchý test
Tvrdší test
Extrémní testovací případ
ABC 123 abc 567
Kočka je línáDalší informace
Doufám, že to byl užitečný přehled regulárních výrazů. Toto je samozřejmě jen špička ledovce a doufám, že se o tomto mocném nástroji budete i nadále učit, když si projdete další zdroje níže.
Kde získat pomoc
- Mým oblíbeným zdrojem je PERL Pocket Reference
- Pro pokročilé zvládnutí regulárních výrazů si přečtěte článek Ovládání regulárních výrazů od Jeffa Friedla
Další příklady naleznete v části
- Jak najít soubory v Linuxu
- Ověření dat v Perlu pomocí Regexp::Common
- 7 důvodů, proč milovat Vim