Awk je skriptovací jazyk, který se používá ke zpracování nebo analýze textových souborů. Nebo můžeme říci, že příkaz awk se používá hlavně pro seskupování dat na základě buď sloupce nebo pole , nebo sady sloupců. Používá se hlavně pro užitečné vykazování dat. Ke zpracování dat také využívá počáteční a koncový blok.
AWK Zkratka pro „Aho, Weinberger a Kernighan“
V tomto tutoriálu se naučíme příkaz awk s praktickými příklady.
Syntaxe awk
# awk ‘vzor {action}’ vstupní-soubor> výstupní-soubor
Vezměme vstupní soubor s následujícími daty
$ cat awk_file Name,Marks,Max Marks Ram,200,1000 Shyam,500,1000 Ghyansham,1000 Abharam,800,1000 Hari,600,1000 Ram,400,1000
Nyní se pojďme hlouběji ponořit do praktických příkladů příkazu awk.
1) Vytiskněte všechny řádky ze souboru
Ve výchozím nastavení awk tiskne všechny řádky souboru, takže pro tisk každého řádku výše vytvořeného souboru použijte příkaz níže:
$ awk '{print;}' awk_file
Name,Marks,Max Marks
Ram,200,1000
Shyam,500,1000
Ghyansham,1000
Abharam,800,1000
Hari,600,1000
Ram,400,10001000 Poznámka: V příkazu awk ‚{print;}‘ se používá tisk všech polí spolu s jejich hodnotami.
2) Vytiskněte pouze konkrétní pole, jako je 2. a 3.
V příkazu awk používáme pro tisk hodnot polí symbol $ (dolar) následovaný číslem pole. V níže uvedeném příkladu tiskneme pole 2 (tj. známky) a pole 3 (tj. maximální počet známek)
$ awk -F "," '{print $2, $3;}' awk_file
Marks Max Marks
200 1000
500 1000
1000
800 1000
600 1000
400 1000 Ve výše uvedeném příkazu jsme použili možnost -F “,” která určuje, že čárka (,) je oddělovač polí v souboru.
3) Vytiskněte čáry, které odpovídají vzoru
Chci vytisknout řádky, které obsahují slovo „Hari &Ram“, spusťte
$ awk '/Hari|Ram/' awk_file Ram,200,1000 Hari,600,1000 Ram,400,1000
4) Jak najdeme jedinečné hodnoty v prvním sloupci názvu
Chcete-li vytisknout jedinečné hodnoty z prvního sloupce, spusťte níže příkaz awk
$ awk -F, '{a[$1];}END{for (i in a)print i;}' awk_file
Abharam
Hari
Name
Ghyansham
Ram
Shyam 5) Jak najít součet zadaných dat v konkrétním sloupci
V příkazu awk je také možné provést některé aritmetické operace založené na vyhledávání, syntaxe je uvedena níže
$ awk -F, ‘$1==”Item1″{x+=$2;}END{print x}’ awk_file
V níže uvedeném příkladu hledáme Ram a poté přidáme hodnoty 2. pole pro Ram word.
$ awk -F, '$1=="Ram"{x+=$2;}END{print x}' awk_file
600 6) Jak najít součet všech čísel ve sloupci
V příkazu awk můžeme také vypočítat součet všech čísel ve sloupci souboru. V níže uvedeném příkladu počítáme součet všech čísel 2. a 3. sloupce.
$ awk -F"," '{x+=$2}END{print x}' awk_file
3500
$ awk -F"," '{x+=$3}END{print x}' awk_file
5000 7) Jak zjistit součet záznamů jednotlivých skupin
Pokud například vezmeme v úvahu první sloupec, můžeme provést součet pro první sloupec na základě položek
$ awk -F, '{a[$1]+=$2;}END{for(i in a)print i", "a[i];}' awk_file
Abharam, 800
Hari, 600
Name, 0
Ghyansham, 1000
Ram, 600
Shyam, 500 8) Najděte součet všech položek konkrétních sloupců a připojte jej na konec souboru
Jak jsme již diskutovali o tom, že příkaz awk dokáže součet všech čísel sloupce, takže chcete-li přidat součet sloupce 2 a sloupce 3 na konec souboru, spusťte
$ awk -F"," '{x+=$2;y+=$3;print}END{print "Total,"x,y}' awk_file
Name,Marks,Max Marks
Ram,200,1000
Shyam,500,1000
Ghyansham,1000
Abharam,800,1000
Hari,600,1000
Ram,400,1000
Total,3500 5000 9) Jak zjistit počet záznamů v každém sloupci na základě prvního sloupce
$ awk -F, '{a[$1]++;}END{for (i in a)print i, a[i];}' awk_file
Abharam 1
Hari 1
Name 1
Ghyansham 1
Ram 2
Shyam 1 10) Jak vytisknout pouze první záznam každé skupiny
Chcete-li vytisknout pouze první z každé skupiny, spusťte níže příkaz awk
$ awk -F, '!a[$1]++' awk_file Name,Marks,Max Marks Ram,200,1000 Shyam,500,1000 Ghyansham,1000 Abharam,800,1000 Hari,600,1000
Začátek bloku AWK
Syntaxe bloku BEGIN je
$ awk ‘BEGIN{awk inicializační kód}{aktuální kód AWK}’ Název souboru
Vytvořme datový soubor s níže uvedeným obsahem
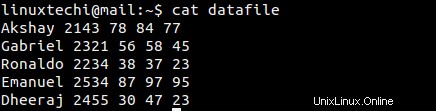
11) Jak vyplnit názvy jednotlivých sloupců spolu s jejich odpovídajícími daty
$ awk 'BEGIN{print "Names\ttotal\tPPT\tDoc\txls"}{printf "%-s\t%d\t%d\t%d\t%d\n", $1,$2,$3,$4,$5}' datafile

12) Jak změnit oddělovač pole
Jak vidíme, mezera je oddělovač polí v datovém souboru, v níže uvedeném příkladu změníme oddělovač polí z mezery na „|“
$ awk 'BEGIN{OFS="|"}{print $1,$2,$3,$4,$5}' datafile

To je z tohoto tutoriálu vše, doufám, že jste našli informace. Sdílejte prosím své názory a dotazy v sekci komentářů níže.