Některé společnosti nemohou dovolit, aby jejich služby přestaly fungovat. V případě výpadku serveru může mobilní operátor zaznamenat výpadek fakturačního systému, který způsobí ztrátu spojení pro všechny jeho klienty. Připuštění potenciálního dopadu takových situací vede k myšlence mít vždy plán B.
V tomto článku vrhneme světlo na různé způsoby ochrany proti selhání serveru a také na architektury používané pro nasazení VMmanager Cloud, ovládacího panelu pro vytváření clusteru s vysokou dostupností.

Předmluva
Terminologie v oblasti klastrové tolerance se web od webu liší. Abychom se vyhnuli míchání různých pojmů a definic, nastínime ty, které budou v daném článku použity:
- Fault Tolerance (FT) je schopnost systému pokračovat v provozu po selhání jedné z jeho součástí.
- Cluster je skupina serverů (uzlů clusteru) propojených komunikačními kanály.
- Fault Tolerant Cluster (FTC) je cluster, kde selhání jednoho serveru nezpůsobí úplnou nedostupnost celého clusteru. Funkce uzlu, který selhal, jsou automaticky přeřazeny mezi zbývající uzly.
- Nepřetržitá dostupnost (CA) znamená, že uživatel může službu využívat, aniž by došlo k jakémukoli časovému limitu. Nezáleží na tom, jak dlouho to bylo od selhání uzlu.
- High Availability (HA) znamená, že uživatel může zaznamenat časový limit služby v případě, že jeden z uzlů selže; systém však bude obnoven automaticky s minimálními prostoji.
- Cluster CA je cluster s nepřetržitou dostupností.
- Cluster HA je cluster s vysokou dostupností.
Nechť je vyžadováno nasazení clusteru sestávajícího z 10 uzlů s virtuálními stroji běžícími na každém uzlu. Cílem je chránit virtuální stroje po selhání serveru. Servery se dvěma CPU se používají k maximalizaci hustoty výpočtu racků.
Na první pohled nejatraktivnější možností pro společnost je nasazení clusteru Continuous Availability, když je služba stále zajišťována poté, co zařízení selhalo. Nepřetržitá dostupnost je skutečně nutností, pokud potřebujete udržovat provoz fakturačního systému nebo automatizovat nepřetržitý výrobní proces. Tento přístup má však také své pasti a úskalí, která jsou popsána níže.
Nepřetržitá dostupnost
Kontinuita služby je možná pouze v případě, že je vytvořena přesná kopie fyzického nebo virtuálního stroje s touto službou, která je kdykoli k dispozici. Takový model redundance se nazývá 2N. Vytvoření kopie serveru poté, co zařízení selhalo, by nějakou dobu trvalo, což by způsobilo časový limit služby. V tomto případě by navíc nebylo možné načíst výpis paměti RAM ze selhalého serveru, což znamená, že všechny informace v něm obsažené by byly pryč.
Pro poskytování CA se používají dva způsoby:na hardwarové a softwarové vrstvě. Zaměřme se na každou z nich podrobněji.
Metoda hardwaru představuje dvojitý server, kde jsou všechny komponenty duplikovány a výpočty jsou prováděny současně a nezávisle. Synchronizace je dosaženo použitím vyhrazeného uzlu, který kontroluje výsledky pocházející z obou částí. Pokud uzel zjistí jakoukoli nesrovnalost, pokusí se definovat problém a opravit chyby. Pokud nelze chybu opravit, systém vypne vadný modul.
Stratus, výrobce CA serverů, garantuje, že celkový výpadek systému nepřesáhne 32 sekund za rok. Těchto výsledků lze dosáhnout pomocí speciálního vybavení. Podle zástupců Stratusu se cena jednoho CA serveru se dvěma CPU pro každý synchronizovaný modul pohybuje kolem 160 000 USD v závislosti na specifikacích. Rozšířená cena za celý cluster CA by v tomto případě byla 1 600 000 $.
Softwarová metoda
Nejoblíbenějším softwarovým nástrojem pro nasazení clusteru Continuous Availability v době článku je VMware vSphere. Technologie nepřetržité dostupnosti tohoto produktu se nazývá Fault Tolerance.
Na rozdíl od hardwarové metody má tato technologie určité požadavky, například následující:
- CPU na fyzickém hostiteli:
- Intel s architekturou Sandy Bridge (nebo novější). Avoton není podporován.
- buldozer AMD (nebo novější).
- Stroje s odolností proti chybám mají být připojeny k jedné 10Gb síti s nízkou latencí. Společnost VMware důrazně doporučuje používat vyhrazenou síť.
- Ne více než 4 virtuální CPU na virtuální počítač.
- Ne více než 8 virtuálních CPU na fyzického hostitele.
- Ne více než 4 virtuální počítače na fyzického hostitele.
- Snímky virtuálního počítače nejsou k dispozici.
- Úložiště vMotion není k dispozici.
Úplný seznam omezení a nekompatibility lze nalézt v oficiální dokumentaci.
Licencování vSphere je založeno na fyzických CPU. Cena začíná na 1750 USD za licenci + 550 USD za roční předplatné a podporu. Automatizace správy klastrů také vyžaduje VMware vCenter Server, který stojí více než 8 000 USD. Model 2N slouží k zajištění nepřetržité dostupnosti, proto je potřeba zakoupit 10 replikovaných serverů s licencí pro každý z nich, aby bylo možné postavit cluster s 10 uzly s virtuálními stroji.
Celkové náklady na software by byly 2[Počet CPU na server]*(10[Počet uzlů s virtuálními stroji]+10[Počet replikovaných uzlů])*(1750+550)[Náklady na licenci na každý CPU]+8000 [Cena serveru VMware vCenter]=100 000 USD. Všechny ceny jsou zaokrouhleny.
Konkrétní konfigurace uzlů nejsou v tomto článku popsány, protože součásti serveru se vždy liší v závislosti na účelu clusteru. Síťové vybavení také není popsáno, protože by mělo být v každém případě totožné. Tento článek se zaměřuje na ty součásti, které by se rozhodně lišily, což jsou náklady na licenci.
Je také důležité zmínit produkty, které již nejsou vyvíjeny a podporovány.
Produkt s názvem Remus je založen na virtualizaci Xen. Jedná se o bezplatné open source řešení, které využívá technologii micro snapshot. Bohužel jeho dokumentace nebyla dlouho aktualizována:Instalační příručka poskytuje pokyny pro Ubuntu 12.10, jehož konec životnosti byl oznámen v roce 2014. Ani vyhledávání Google nenašlo žádnou společnost, která by Remus používala pro své operace.
Byly učiněny pokusy upravit QEMU tak, aby na této technologii byly vytvořeny clustery s nepřetržitou dostupností. Existují dva projekty, které oznámily svou práci v tomto směru.
Prvním z nich je Kemari, open source produkt vedený Yoshiaki Tamura. Tento projekt měl za cíl používat živou migraci QEMU. Poslední závazek byl učiněn v únoru 2011, což naznačuje, že vývoj uvízl na mrtvém bodě a nebude pokračovat.
Druhým produktem je Micro Checkpointing, open source projekt založený Michaelem Hinesem. V jeho changelogu nebyla za poslední rok nalezena žádná aktivita, která připomíná projekt Kemari.
Tato fakta nám umožňují učinit závěr, že k dnešnímu dni jednoduše neexistuje možnost nepřetržité dostupnosti na virtualizaci KVM.
Přes všechny výhody systémů nepřetržité dostupnosti existuje mnoho překážek na cestě k nasazení a provozu takových řešení. Nicméně v některých případech může být vyžadována odolnost proti poruchám, ale bez nutnosti být nepřetržitě k dispozici. Takové scénáře umožňují použití clusterů s vysokou dostupností.
Vysoká dostupnost
Cluster High Availability poskytuje odolnost proti chybám tím, že automaticky detekuje, zda je hardware mimo provoz, a následně spustí službu na dostupném uzlu.
Vysoká dostupnost nepodporuje synchronizaci CPU spuštěných na uzlech a neumožňuje vždy synchronizovat místní disky. S ohledem na tuto skutečnost se doporučuje umístit jednotky používané uzly do samostatného nezávislého úložiště, jako je síťové úložiště.
Důvod je jasný:Uzel po jeho selhání není dostupný a informace z jeho úložného zařízení nelze získat. Systém ukládání dat by také měl být odolný proti chybám, jinak neexistuje možnost vysoké dostupnosti. Výsledkem je, že klastr High Availability se skládá ze dvou dílčích klastrů:
- Výpočetní cluster sestávající z uzlů s virtuálními stroji
- Cluster úložiště s disky, které používají výpočetní uzly.
V současné době se k implementaci clusterů s vysokou dostupností s virtuálními stroji v uzlech clusteru používají následující řešení:
- Tlukot srdce, verze 1.? s DRBD;
- Pacemaker;
- VMware vSphere;
- Proxmox VE;
- XenServer;
- OpenStack;
- oVirt;
- Red Hat Enterprise Virtualization;
- Windows Server Failover Clustering s rolí serveru Hyper-V;
- VMmanager Cloud.
Pojďme se blíže podívat na VMmanager Cloud.
VMmanager Cloud
VMmanager Cloud je produkt, který umožňuje nasazení clusterů s vysokou dostupností a využívá virtualizaci QEMU-KVM. Tato technologie byla vybrána, protože je aktivně vyvíjena a podporována a umožňuje nainstalovat jakýkoli operační systém na virtuální počítač. Produkt používá Corosync ke zjištění dostupnosti clusteru. Pokud je jeden ze serverů mimo provoz, VMmanager distribuuje své virtuální stroje mezi zbývající uzly jeden po druhém.
Ve zjednodušené podobě tento mechanismus funguje následovně:
- Systém identifikuje uzel clusteru s nejnižším počtem virtuálních počítačů.
- Zkontroluje, zda je dostatek paměti RAM k vyhledání počítače.
- Pokud je na uzlu dostatek paměti pro příslušný počítač, VMmanager na tomto uzlu vytvoří nový virtuální počítač.
- Pokud není dostatek paměti, systém zkontroluje ostatní uzly s více virtuálními stroji.
Testováním několika hardwarových konfigurací a dotazem mnoha současných uživatelů cloudu VMmanager bylo zjištěno, že distribuce a obnovení provozu všech virtuálních počítačů ze selhání uzlu obvykle trvá 45–90 sekund, v závislosti na výkonu zařízení.
Doporučuje se vyhradit jeden nebo několik uzlů jako ochranu před nouzovými situacemi a nenasazovat virtuální počítače na tyto uzly během rutinního provozu. Minimalizuje šance na nedostatek prostředků na živých uzlech clusteru pro přidávání virtuálních počítačů z uzlu, který selhal. V případě, že je použit pouze jeden záložní uzel, tento bezpečnostní model se nazývá N+1.
VMmanager Cloud podporuje následující typy úložiště:souborový systém, LVM, Network LVM, iSCSI a Ceph [zejména RBD (RADOS Block Device), jedna z implementací Ceph]. Poslední tři se používají pro vysokou dostupnost.
Jedna doživotní licence pro deset provozních uzlů a jeden záložní uzel stojí 3 520 EUR, nebo 3 865 USD k dnešnímu dni (jedna licence stojí 320 EUR na uzel bez ohledu na číslo CPU). Licence zahrnuje jeden rok bezplatných aktualizací; počínaje druhým rokem jsou aktualizace poskytovány na model předplatného za cenu 880 EUR ročně za celý cluster.
Podívejme se, jak již byl VMmanager Cloud použit pro nasazení clusterů s vysokou dostupností.
FirstByte
FirstByte začal poskytovat cloudový hosting v únoru 2016. Původně byl jejich cluster postaven na OpenStack; nedostatek specialistů na tento systém z hlediska dostupnosti i ceny je však přiměl hledat alternativní řešení. Nový systém pro budování clusteru s vysokou dostupností měl splňovat následující požadavky:
- Možnost nasazení virtuálních strojů KVM.
- Integrace s Ceph.
- Integrace s fakturačním systémem pro nabízení stávajících služeb.
- Dostupná cena licence.
- Podpora od vývojáře softwaru.
VMmanager Cloud splňuje všechny požadavky.
Charakteristické rysy clusteru FirstByte:
- Přenos dat je založen na technologii Ethernet a zařízení Cisco.
- Směrování se provádí pomocí Cisco ASR9001. Cluster používá přibližně 50 000 adres IPv6.
- Rychlost propojení mezi výpočetními uzly a přepínači je 10 Gb/s.
- Rychlost přenosu dat mezi přepínači a uzly úložiště je 20 Gb/s, se dvěma kombinovanými kanály, každý o rychlosti 10 Gb/s.
- Mezi stojany s úložnými uzly se pro replikaci používá samostatné propojení 20 Gb/s.
- Disky SAS v kombinaci s SSD jsou nainstalovány na všech storage nodech.
- Typ úložiště je RBD.
Rozvržení systému je uvedeno níže:
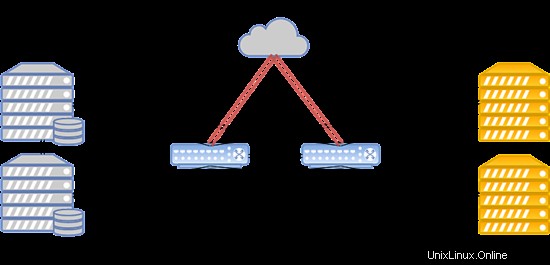
Taková konfigurace funguje pro hostování oblíbených webových stránek, herních serverů a databází s nadprůměrnou zátěží.
FirstVDS
FirstVDS poskytuje služby clusteru odolného proti chybám, který byl spuštěn v září 2015.
VMmanager Cloud byl pro tento cluster vybrán kvůli následujícím faktorům:
- Snadné zkušenosti s používáním ovládacích panelů systému ISP.
- Výchozí integrace s BILLmanagerem.
- Vysoká kvalita technické podpory.
- Integrace s Ceph.
Jejich cluster má následující vlastnosti:
- Přenos dat je založen na síti Infiniband s rychlostí připojení 56 Gbps;
- Síť Infiniband je postavena na zařízení Mellanox;
- Uzel úložišť má jednotky SSD;
- Typ úložiště je RBD.
Systém může být uspořádán následujícím způsobem:
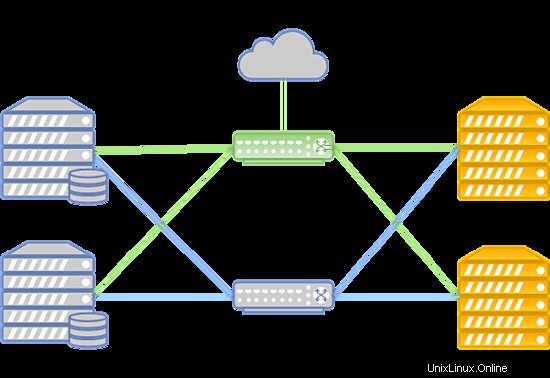
V případě selhání sítě Infiniband je spojení mezi diskovým úložištěm VM a výpočetními servery navázáno prostřednictvím sítě Ethernet nasazené na zařízení Juniper. Nové připojení se nastaví automaticky.
Díky vysoké rychlosti komunikace s úložištěm tento cluster perfektně funguje pro hostování webů s ultravysokým provozem, streamování videa a obsahu, stejně jako velká data.
Závěr
Pojďme si shrnout hlavní zjištění článku.
Cluster Continuous Availability je nutností, když každá sekunda výpadku přináší značné ztráty. Pokud je povoleno 5 minut výpadku během nasazování virtuálních počítačů na záložní uzel, může být cluster High Availability dobrou volbou pro snížení nákladů na hardware a software.
Je také důležité připomenout, že jediný způsob, jak dosáhnout odolnosti vůči chybám, je nadměrnost. Ujistěte se, že replikujete své servery, zařízení pro datovou komunikaci a odkazy, kanály pro přístup k internetu a napájení. Replikujte vše, co můžete. Taková opatření umožňují eliminovat úzká hrdla a potenciální místa selhání, která mohou způsobit prostoje celého systému. Provedením výše uvedených opatření si můžete být jisti, že máte cluster odolný vůči poruchám.
Pokud si myslíte, že model High Availability vyhovuje vašim požadavkům a VMmanager Cloud je dobrým nástrojem k jeho realizaci, přečtěte si prosím instalační příručku a dokumentaci, kde se dozvíte více o systému. jám přejeme vám bezporuchový a nepřetržitý provoz!