V našem prvním článku o příkazu grep jsme se zabývali několika funkcemi, které nástroj nabízí, včetně toho, jak jej můžete použít k vyhledávání pouze slov, hledání dvou slov, počítání řádků obsahujících odpovídající slovo a dalších. Kromě toho tento nástroj poskytuje některé další snadno srozumitelné a užitečné funkce. V tomto článku budeme diskutovat o několika z nich.
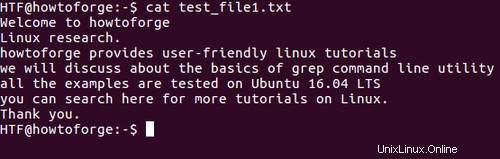
Vezměte prosím na vědomí, že všechny příklady uvedené v tomto tutoriálu byly testovány na Ubuntu 14.04LTS. Také budeme používat následující soubor (test_file1.txt) pro všechny naše příklady související s grep v tomto tutoriálu:
Vyhledávání bez rozlišení malých a velkých písmen pomocí Grep
Ve výchozím nastavení grep rozlišuje velká a malá písmena, což znamená, že například 'ABC' a 'abc' bude zpracovávat odděleně. Pokud však chcete, aby se při vyhledávání nerozlišovala malá a velká písmena, můžete použít -i možnost příkazového řádku.
grep -i [string-to-be-searched] [filename]
Například:
grep -i "linux" test_file1.txt
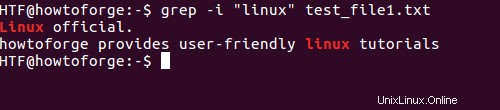
Poznámka :Nejen vzor (například 'linux' ve výše uvedeném příkladu), manuálová stránka grep říká, že volba -i také zajišťuje, že se u vstupních souborů bude ignorovat i rozlišování velkých a malých písmen. Zde je úryvek:
-i, --ignore-case
Ignore case distinctions in both the PATTERN and the input files. (-i is specified by POSIX.)
Chování související se vstupními soubory se nám však na našem konci nepodařilo reprodukovat.
Zobrazit určité neodpovídající řádky s řádkem obsahujícím odpovídající řetězec v Grepu
Pomocí tohoto nástroje můžete také zobrazit zadaný počet řádků za, před nebo kolem řádku obsahujícího odpovídající řetězec.
Použijte -A možnost příkazového řádku pro tisk 'N' řádků po odpovídajícím řádku.
$ grep -A N [string-to-be-searched] [filename]
Například:
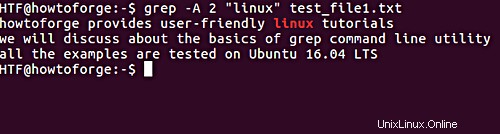
$ grep -A 2 "linux" test_file1.txt
Zde je výstup výše uvedeného příkazu
Podobně se volba -B příkazového řádku používá k zobrazení řádků před odpovídajícím řádkem.
$ grep -B N [string-to-be-searched] [filename]
Například:
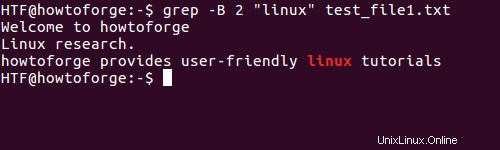
$ grep -B 2 "linux" test_file1.txt
Zde je výstup:
A konečně, chcete-li vytisknout řádky kolem shodného řádku, použijte volbu příkazového řádku -C.
$ grep -C N [string-to-be-searched] [filename]
Například:
$ grep -C 2 "linux" test_file1.txt
Zde je zachycený výstup:
Tisknout pouze odpovídající řetězce v Grepu
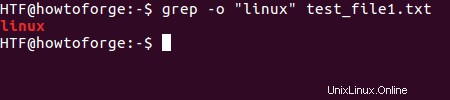
Můžete také vytisknout pouze odpovídající řetězec na standardní výstup (místo celých řádků, které se zobrazují ve výchozím nastavení). K této funkci lze přistupovat pomocí volby příkazového řádku -o.
$ grep -o [string-to-be-searched] [filename]
Pokud je například požadavkem hledat v souboru řetězec „linux“ (ale neměly by se tisknout celé řádky), použijeme následující příkaz.
$ grep -o "linux" [file-name]
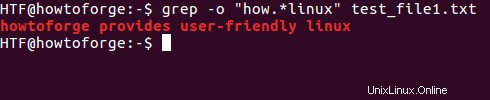
Můžeme také použít zástupné znaky, jako je * a .*, abychom grep více než jeden řetězec. Například, pokud chceme grepovat skupinu slov začínajících „jak“ a končících „linux“, můžeme použít následující příkaz.
$ grep -o “how.*linux” [file-name]
Pozice zobrazení v Grepu
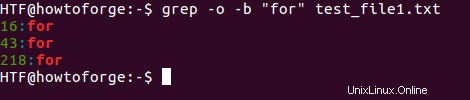
Příkaz grep také umožňuje zobrazit bajtový offset řádku, ve kterém se vyskytuje odpovídající řetězec. K této funkci lze přistupovat pomocí volby příkazového řádku -b. Ale pro lepší využití této možnosti ji můžete použít s volbou -o příkazového řádku, která zobrazí přesnou pozici shodného řetězce.
$ grep -o -b [string-to-be-searched] [filename]
Například:
$ grep -o -b "for" test_file1.txt
Zde je výstup:
Závěr
Možná nepotřebujete všechny tyto možnosti každý den, ale měli byste o nich alespoň vědět, protože nikdy nevíte, kdy se mohou hodit. Grep se stává ještě silnějším, když se používá s regulárním výrazem, ale toto téma necháme na jindy.