Kubernetes je open source platforma pro správu kontejnerových úloh a služeb, která usnadňuje deklarativní konfiguraci a automatizaci. Jméno Kubernetes pochází z řečtiny a znamená kormidelník nebo pilot. Je přenosný i rozšiřitelný a má rychle rostoucí ekosystém. Služby a nástroje Kubernetes jsou široce dostupné.
V tomto článku projdeme 10 000 stop dlouhým pohledem na hlavní komponenty Kubernetes, od toho, z čeho se každý kontejner skládá, až po to, jak je kontejner v podu nasazen a naplánován u každého z pracovníků. Aby bylo možné nasadit a navrhnout řešení založené na Kubernetes jako orchestrátoru pro kontejnerizované aplikace, je zásadní porozumět úplným detailům clusteru Kubernetes.
Zde je stručný popis věcí, kterým se budeme věnovat v tomto článku:
- Součásti ovládacího panelu
- Komponenty pracovníka Kubernetes
- Pody jako základní stavební kameny
- Služby Kubernetes, nástroje pro vyrovnávání zatížení a řadiče Ingress
- Nasazení Kubernetes a sady démonů
- Trvalé úložiště v Kubernetes
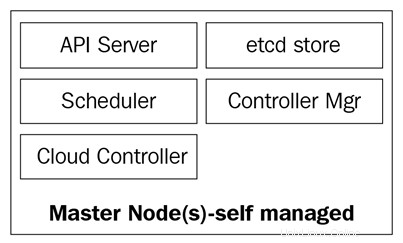
Řídicí rovina Kubernetes
Hlavní uzly Kubernetes jsou místem, kde žijí služby základní řídicí roviny; ne všechny služby musí být umístěny na stejném uzlu; z důvodu centralizace a praktičnosti se však často nasazují tímto způsobem. To zjevně vyvolává otázky týkající se dostupnosti služeb; lze je však snadno překonat tím, že budete mít několik uzlů a budete poskytovat požadavky na vyrovnávání zátěže, abyste dosáhli vysoce dostupné sady hlavních uzlů .
Hlavní uzly se skládají ze čtyř základních služeb:
- Kube-apiserver
- Plánovač kube
- Kube-controller-manager
- databáze etcd
Hlavní uzly mohou běžet na holých serverech, virtuálních počítačích nebo v privátním či veřejném cloudu, ale nedoporučuje se na nich spouštět kontejnerové úlohy. Více o tom uvidíme později.
Následující diagram ukazuje komponenty hlavního uzlu Kubernetes:
Kube-apiserver
Server API je to, co vše spojuje. Je to frontendové REST API klastru, které přijímá manifesty k vytváření, aktualizaci a odstraňování objektů API, jako jsou služby, pody, Ingress a další.
kube-apiserver je jediná služba, se kterou bychom měli mluvit; je to také jediný, který zapisuje a komunikuje s databází etcd za účelem registrace stavu clusteru. Pomocí příkazu kubectl budeme odesílat příkazy pro interakci s ním. Toto bude náš švýcarský armádní nůž, pokud jde o Kubernetes.
Kube-controller-manager
Démon kube-controller-manager je ve zkratce sada nekonečných řídicích smyček, které jsou pro jednoduchost dodávány v jedné binární podobě. Hlídá definovaný požadovaný stav shluku a dbá na to, aby byl splněn a uspokojen pohybem všech částí nezbytných k jeho dosažení. kube-controller-manager není jen jeden ovladač; obsahuje několik různých smyček, které sledují různé komponenty v clusteru. Některé z nich jsou správce služby, správce jmenného prostoru, správce servisního účtu a mnoho dalších. Každý řadič a jeho definici najdete v úložišti Kubernetes GitHub:https://github.com/kubernetes/kubernetes/tree/master/pkg/controller.
Plánovač kube
Plánovač kube naplánuje vaše nově vytvořené pody do uzlů s dostatečným prostorem pro uspokojení zdrojů podů. V zásadě poslouchá kube-apiserver a kube-controller-manager pro nově vytvořené pody, které jsou zařazeny do fronty a poté plánovačem naplánovány do dostupného uzlu. Definici kube-scheduler naleznete zde:https://github.com/kubernetes/kubernetes/blob/master/pkg/scheduler.
Kromě výpočetních zdrojů čte plánovač kube také pravidla afinity a antiafinity uzlů, aby zjistil, zda uzel může nebo nemůže spustit daný modul.
Databáze etcd
Databáze etcd je velmi spolehlivé konzistentní úložiště párů klíč–hodnota, které se používá k ukládání stavu clusteru Kubernetes. Obsahuje aktuální stav modulů, na kterých uzel běží, kolik uzlů má cluster aktuálně, jaký je stav těchto uzlů, kolik běží replik nasazení, názvy služeb a další.
Jak jsme již zmínili, s databází etcd komunikuje pouze kube-apiserver. Pokud kube-controller-manager potřebuje zkontrolovat stav clusteru, projde serverem API, aby získal stav z databáze etcd, místo aby se dotazoval přímo na obchod etcd. Totéž se stane s plánovačem kube, pokud plánovač potřebuje oznámit, že modul byl zastaven nebo přidělen jinému uzlu; bude informovat server API a server API uloží aktuální stav do databáze etcd.
S etcd jsme pokryli všechny hlavní komponenty pro naše hlavní uzly Kubernetes, takže jsme připraveni spravovat náš cluster. Ale cluster se neskládá pouze z mistrů; stále potřebujeme uzly, které budou vykonávat náročnou práci při spouštění našich aplikací.
Kubernetes Worker Nodes
Pracovní uzly, které provádějí tento úkol v Kubernetes, se jednoduše nazývají uzly. Dříve, kolem roku 2014, se jim říkalo přisluhovači, ale tento termín byl později nahrazen pouze uzly, protože název byl matoucí s terminologií Salt a lidé si mysleli, že Salt hraje hlavní roli v Kubernetes.
Tyto uzly jsou jediným místem, kde budete spouštět úlohy, protože se nedoporučuje mít kontejnery nebo zatížení na hlavních uzlech, protože musí být k dispozici pro správu celého clusteru. Uzly jsou z hlediska komponent velmi jednoduché; ke splnění svého úkolu potřebují pouze tři služby:
- Kubelet
- Kube-proxy
- Doba běhu kontejneru
Pojďme prozkoumat tyto tři komponenty trochu hlouběji.
Kubelet
Kubelet je nízkoúrovňová komponenta Kubernetes a jedna z nejdůležitějších po kube-apiserveru; obě tyto komponenty jsou nezbytné pro poskytování podů/kontejnerů v clusteru. Kubelet je služba, která běží na uzlech Kubernetes a naslouchá serveru API pro vytváření podů. Kubelet má na starosti pouze spouštění/zastavování a zajišťuje, že nádoby v luscích jsou zdravé; kubelet nebude schopen spravovat žádné kontejnery, které nebyly vytvořeny.
Kubelet dosahuje cílů tím, že komunikuje s kontejnerem runtime prostřednictvím rozhraní pro běh kontejneru (CRI) . CRI poskytuje připojitelnost ke kubeletu prostřednictvím klienta gRPC, který je schopen komunikovat s různými běhovými prostředími kontejnerů. Jak jsme zmínili dříve, Kubernetes podporuje více kontejnerových běhových prostředí pro nasazení kontejnerů, a tak dosahuje tak různorodé podpory pro různé motory.
Zdrojový kód kubelet můžete zkontrolovat na https://github.com/kubernetes/kubernetes/tree/master/pkg/kubelet.
Proxy kube
kube-proxy je služba, která se nachází na každém uzlu clusteru a je to služba, která umožňuje komunikaci mezi pody, kontejnery a uzly. Tato služba sleduje změny definovaných služeb na kube-apiserver (služba je v Kubernetes jakýmsi logickým nástrojem pro vyrovnávání zátěže; do služeb se ponoříme hlouběji později v tomto článku) a udržuje síť aktuální pomocí pravidel iptables, která přesměrovávají provoz na správné koncové body. Kube-proxy také nastavuje pravidla v iptables, která provádějí náhodné vyvažování zátěže napříč pody za službou.
Zde je příklad pravidla iptables, které vytvořil kube-proxy:
-A KUBE-SERVICES -d 10.0.162.61/32 -p tcp -m komentář --komentář "výchozí/příklad:nemá žádné koncové body" -m tcp --dport 80 -j REJECT --reject-with icmp-port-unreachable
Všimněte si, že toto je služba bez koncových bodů (bez podů za nimi).
Běh kontejneru
Aby bylo možné kontejnery roztočit, potřebujeme kontejnerový běh . Toto je základní modul, který vytvoří kontejnery v jádře uzlů pro spuštění našich podů. Kubelet bude mluvit s tímto runtime a na požádání roztočí nebo zastaví naše kontejnery.
V současné době Kubernetes podporuje jakékoli běhové prostředí kontejneru kompatibilní s OCI, jako je Docker, rkt, runc, runsc a tak dále.
Můžete se podívat na tuto https://github.com/opencontainers/runtime-spec, kde se dozvíte více o všech specifikacích ze stránky OCI Git-Hub.
Nyní, když jsme prozkoumali všechny základní komponenty, které tvoří cluster, se nyní podíváme na to, co s nimi lze dělat a jak nám Kubernetes pomůže organizovat a spravovat naše kontejnerové aplikace.
Objekty Kubernetes
Objekty Kubernetes jsou přesně takové:jsou to logické trvalé objekty nebo abstrakce, které budou reprezentovat stav vašeho clusteru. Vy jste ten, kdo má na starosti sdělit Kubernetes, jaký je požadovaný stav tohoto objektu, aby mohl pracovat na jeho údržbě a ujistit se, že objekt existuje.
K vytvoření objektu jsou potřeba dvě věci, které musí mít:stav a jeho specifikace. Stav poskytuje Kubernetes a je to aktuální stav objektu. Kubernetes bude tento stav spravovat a aktualizovat podle potřeby, aby byl v souladu s vaším požadovaným stavem. Na druhou stranu pole spec je to, co poskytujete Kubernetes, a je to, co mu říkáte, aby popsalo požadovaný objekt. Například obrázek, který chcete, aby kontejner běžel, počet kontejnerů tohoto obrázku, které chcete spustit, a tak dále.
Každý objekt má specifická pole specifikací pro typ úlohy, kterou provádí, a tyto specifikace poskytnete v souboru YAML, který se odešle na server kube-apiser s kubectl, který jej převede na JSON a odešle jako požadavek API. . Ke každému objektu a jeho polím specifikací se ponoříme hlouběji v tomto článku.
Zde je příklad YAML, který byl odeslán do kubectl:
kočka <
Základní pole definice objektu jsou úplně první a tato pole se nebudou lišit objekt od objektu a jsou velmi samovysvětlující. Pojďme se na ně rychle podívat:
Nyní jsme si tedy prošli nejpoužívanější pole a jejich obsah; můžete se dozvědět více o konvencích Kuberntes API na https://github.com/kubernetes/community/blob/master/contributors/devel/api-conventions.md
Některá pole objektu lze později po vytvoření objektu upravit, ale to bude záviset na objektu a poli, které chcete upravit.
Následuje krátký seznam různých objektů Kubernetes, které můžete vytvořit:
A existuje mnoho dalších.
Podívejme se blíže na každou z těchto položek.
Pody jsou nejzákladnější objekty v Kubernetes a také ty nejdůležitější. Všechno se točí kolem nich; můžeme říci, že Kubernetes je pro lusky! Všechny ostatní předměty jsou zde, aby jim sloužily, a všechny jejich úkoly spočívají v tom, aby moduly dosáhly požadovaného stavu.
Co je tedy pod a proč jsou pody tak důležité?
Pod je logický objekt, který společně provozuje jeden nebo více kontejnerů ve stejném síťovém jmenném prostoru, stejné meziprocesové komunikaci (IPC) a někdy, v závislosti na verzi Kubernetes, stejné ID procesu (PID) jmenný prostor. Je to proto, že právě oni budou provozovat naše kontejnery, a proto budou středem pozornosti. Celým smyslem Kubernetes je být kontejnerovým orchestrátorem a pomocí podů umožňujeme orchestraci.
Jak jsme již zmínili, kontejnery na stejném podu žijí v „bublině“, kde spolu mohou mluvit prostřednictvím localhost, protože jsou pro sebe místní. Jeden kontejner v podu má stejnou IP adresu jako druhý kontejner, protože sdílejí síťový jmenný prostor, ale ve většině případů budete spouštět na bázi jeden na jednoho, to znamená jeden kontejner na pod. . Více kontejnerů na pod se používá pouze ve velmi specifických scénářích, jako když aplikace vyžaduje pomocníka, jako je například data pusher nebo proxy, který potřebuje komunikovat rychlým a odolným způsobem s primární aplikací.
Způsob, jakým definujete pod, je stejný, jako byste to udělali pro jakýkoli jiný objekt Kubernetes:prostřednictvím YAML, který obsahuje všechny specifikace a definice pod:
druh:PodapiVersion:v1metadata:name:hello-podlabels: hello:podspec: kontejnery: - name:hello-container image:alpine args: - echo - "Ahoj světe"
Pojďme si projít základní definice podu potřebné v poli spec k vytvoření našeho podu:
Toto jsou nejzákladnější specifikace, které se chystáte deklarovat na modulu; další specifikace budou vyžadovat, abyste měli trochu více znalostí o tom, jak je používat a jak interagují s různými jinými objekty Kubernetes. Vrátíme se k nim později v tomto článku; některé z nich jsou následující:
Chcete-li zobrazit pody, které aktuálně běží ve vašem clusteru, můžete spustit kubectl get pody:
[email protected]:~$ kubectl get podsNAME READY STATUS RESTARTUJE AGEbusybox 1/1 Běží 120 5d
Případně můžete spustit kubectl description pody, aniž byste zadali jakýkoli pod. Tím se vytiskne popis každého modulu spuštěného v clusteru. V tomto případě to bude pouze busybox pod, protože je to jediný, který je aktuálně spuštěný:
[chráněno e-mailem]:~ $ kubectl Popište podsname:BusyboxNamespace:DefaultPriority:0PriorityClassName:
Lusky jsou smrtelné. Jakmile zemře nebo je smazána, nelze je obnovit. Jeho IP a kontejnery, které na něm běžely, budou pryč; jsou zcela pomíjivé. Data na modulech, která jsou připojena jako svazek, mohou nebo nemusí přežít, v závislosti na tom, jak je nastavíte. Pokud naše moduly zemřou a my je ztratíme, jak zajistíme, aby všechny naše mikroslužby fungovaly? Řešením jsou nasazení.
Pody samy o sobě nejsou příliš užitečné, protože není příliš efektivní mít více než jednu instanci naší aplikace spuštěnou v jednom podu. Poskytování stovek kopií naší aplikace na různých modulech, aniž byste měli metodu, jak je všechny hledat, se vám opravdu rychle vymkne z rukou.
Zde přichází na řadu nasazení. Díky nasazení můžeme své pody spravovat pomocí ovladače. To nám umožňuje nejen rozhodnout, kolik jich chceme spustit, ale můžeme také spravovat aktualizace změnou verze obrázku nebo samotného obrázku, který naše kontejnery spouštějí. Nasazení jsou to, s čím budete většinu času pracovat. S nasazeními, stejně jako moduly a dalšími objekty, které jsme zmínili dříve, mají v souboru YAML svou vlastní definici:
apiVersion:apps/v1kind:Deploymentmetadata:name:nginx-deployment labels: deployment:nginxspec:replicas:3 selector: matchLabels: app:nginx template: metadata: štítky: štítky: štítky: název aplikace: v názvech: : v název aplikace: : 1.7.9 porty: – containerPort:80
Začněme zkoumat jejich definici.
Na začátku YAML máme obecnější pole, jako jsou apiVersion, kind a metadata. Ale v části spec najdeme konkrétní možnosti pro tento objekt API.
V rámci specifikace můžeme přidat následující pole:
Výběr :S polem Selector bude nasazení vědět, na které moduly má cílit, když se použijí změny. Pod selektorem jsou dvě pole, která budete používat: matchLabels a matchExpressions. U matchLabels použije selektor štítky podů (páry klíč/hodnota). Je důležité si uvědomit, že všechny štítky, které zde uvedete, budou mít A. To znamená, že pod bude vyžadovat, aby měl všechny štítky, které zadáte v části matchLabels.
Repliky :Toto bude uvádět počet podů, které nasazení potřebuje, aby běželo přes řadič replikace; pokud například zadáte tři repliky a jeden z modulů zemře, řadič replikace bude sledovat specifikaci replik jako požadovaný stav a informuje plánovač, aby naplánoval nový modul, protože aktuální stav je nyní 2, protože modul zemřel.
RevisionHistoryLimit :Pokaždé, když provedete změnu v nasazení, tato změna se uloží jako revize nasazení, kterou můžete později buď vrátit do předchozího stavu, nebo si ponechat záznam o tom, co se změnilo. Svou historii si můžete prohlédnout pomocí historie nasazení kubectl/
Strategie :To vám umožní rozhodnout se, jak chcete zpracovat jakoukoli aktualizaci nebo horizontální měřítko pod. Chcete-li přepsat výchozí hodnotu, kterou je rollingUpdate, musíte napsat klíč type, kde si můžete vybrat mezi dvěma hodnotami: recreate nebo rollingUpdate.
I když je opětovné vytvoření rychlým způsobem aktualizace vašeho nasazení, odstraní všechny moduly a nahradí je novými, ale bude to znamenat, že budete muset vzít v úvahu, že u tohoto typu strategie dojde k výpadku systému. RollingUpdate je na druhou stranu plynulejší a pomalejší a je ideální pro stavové aplikace, které mohou znovu vyvážit svá data. RollingUpdate otevírá dveře pro další dvě pole, kterými jsou maxSurge a maxUnailable.
První bude počet modulů nad celkovou částku, kterou chcete při provádění aktualizace; například nasazení se 100 moduly a 20% maxSurge při aktualizaci naroste až na maximálně 120 modulů. Další možnost vám umožní vybrat, kolik lusků v procentech jste ochotni zabít, abyste je nahradili novými ve scénáři 100 lusků. V případech, kdy je nedostupných maximálně 20 %, bude zabito pouze 20 modulů a nahrazeno novými, než bude pokračovat výměna zbytku nasazení.
Šablona :Toto je pouze vnořené pole specifikace podu, kam zahrnete všechny specifikace a metadata podů, které bude nasazení spravovat.
Viděli jsme, že pomocí nasazení spravujeme své moduly a pomáhají nám je udržovat ve stavu, který si přejeme. Všechny tyto moduly jsou stále v něčem, co se nazývá shluk síť , což je uzavřená síť, ve které spolu mohou komunikovat pouze komponenty clusteru Kubernetes, a to i s vlastní sadou rozsahů IP. Jak mluvíme s našimi moduly zvenčí? Jak se dostaneme k naší aplikaci? Zde vstupují do hry služby.
Služby :
Název služby plně nepopisuje, co služby skutečně dělají v Kubernetes. Služby Kubernetes směrují provoz do našich modulů. Můžeme říci, že služby jsou tím, co spojuje lusky.
Představme si, že máme typický frontend/backend typ aplikace, kde naše frontendové moduly komunikují s našimi backendovými prostřednictvím IP adres modulů. Pokud modul v backendu zemře, ztratíme komunikaci s naším backendem. Není to jen proto, že nový modul nebude mít stejnou IP adresu jako modul, který zemřel, ale nyní také musíme překonfigurovat naši aplikaci, aby používala novou IP adresu. Tento problém a podobné problémy se řeší pomocí služeb.
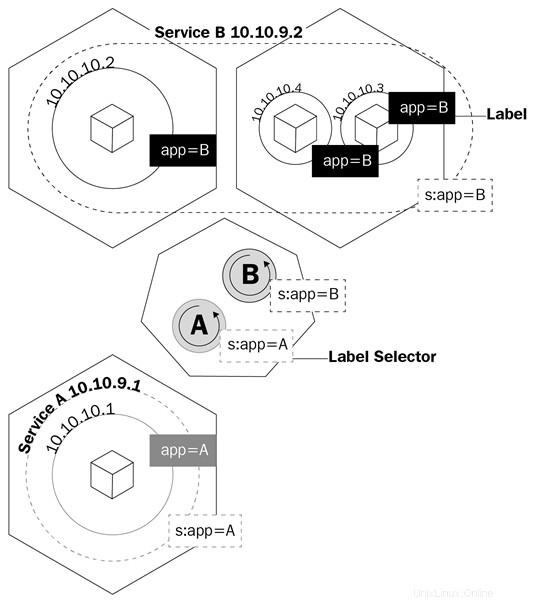
Služba je logický objekt, který říká kube-proxy, aby vytvořila pravidla iptables na základě toho, které pody jsou za službou. Služby konfigurují své koncové body, což je způsob, jakým se pody za službou nazývají, stejně jako nasazení vědí, které pody mají ovládat, pole výběru a štítky podů.
Tento diagram ukazuje, jak služby používají štítky ke správě provozu:
Služby nejen přimějí kube-proxy vytvářet pravidla pro směrování provozu; spustí také něco, co se nazývá kube-dns.
Kube-dns je sada modulů s kontejnery SkyDNS, které běží na clusteru, který poskytuje server DNS a forwarder, který vytvoří záznamy pro služby a někdy i moduly pro snadné použití. Kdykoli vytvoříte službu, bude vytvořen záznam DNS směřující na interní IP adresu clusteru služby ve tvaru název-služby.názvový prostor.svc.cluster.local. Další informace o specifikacích Kubernetes DNS najdete zde: https://github.com/kubernetes/dns/blob/master/docs/specification.md.
Vraťme se k našemu příkladu a nyní budeme muset nakonfigurovat naši aplikaci, aby mohla komunikovat se službou plně kvalifikovaný název domény (FQDN) abychom mohli mluvit s našimi backendovými moduly. Tímto způsobem nebude záležet na tom, jakou IP adresu mají moduly a služby. Pokud modul za službou zemře, služba se o vše postará pomocí záznamu A, protože budeme moci říci našemu frontendu, aby směroval veškerý provoz do my-svc. O vše ostatní se postará logika služby.
Existuje několik typů služeb, které můžete vytvořit, kdykoli deklarujete, že objekt má být vytvořen v Kubernetes. Pojďme si je projít, abychom zjistili, který z nich bude nejvhodnější pro typ práce, kterou potřebujeme:
ClusterIP :Toto je výchozí služba. Kdykoli vytvoříte službu ClusterIP, vytvoří se služba s interní IP adresou clusteru, která bude směrovatelná pouze uvnitř clusteru Kubernetes. Tento typ je ideální pro moduly, které si potřebují pouze povídat, aniž by se dostaly mimo skupinu.
NodePort :Když vytvoříte tento typ služby, bude ve výchozím nastavení přidělen náhodný port od 30000 do 32767 pro předávání provozu do koncových modulů služby. Toto chování můžete přepsat zadáním portu uzlu v poli portů. Jakmile bude toto definováno, budete mít přístup ke svým podům přes
LoadBalancer :Většinu času budete Kubernetes provozovat na cloudovém poskytovateli. Typ LoadBalancer je pro tyto situace ideální, protože budete moci své službě přidělovat veřejné IP adresy prostřednictvím API vašeho cloudového poskytovatele. Toto je ideální služba, když chcete komunikovat se svými moduly mimo váš cluster. S LoadBalancerem budete moci nejen přidělovat veřejnou IP adresu, ale také pomocí Azure přidělovat privátní IP adresu z vaší virtuální privátní sítě. Takže můžete mluvit se svými moduly z internetu nebo interně ve své soukromé podsíti.
Podívejme se na definici služby YAML:
apiVersion:v1kind:Servicemetadata: název:my-servicespec:selector: aplikace:typ rozhraní:NodePort porty: - název:http port:80 targetPort:8080 nodePort:30024 protokol:TCP
YAML služby je velmi jednoduchý a specifikace se budou lišit v závislosti na typu služby, kterou vytváříte. Ale nejdůležitější věc, kterou musíte vzít v úvahu, je definice portů. Pojďme se podívat na tyto:
I když nyní chápeme, jak můžeme komunikovat s pody v našem clusteru, stále musíme rozumět tomu, jak budeme řešit problém ztráty dat při každém ukončení podu. Toto je místo Trvalé Svazky (PV ) se začne používat.
Trvalé úložiště ve světě kontejnerů je vážný problém. Jediným úložištěm, které je trvalé napříč běhy kontejnerů, jsou vrstvy obrazu a jsou pouze pro čtení. Vrstva, ve které kontejner běží, je určena pro čtení/zápis, ale všechna data v této vrstvě jsou odstraněna, jakmile se kontejner zastaví. S lusky je to stejné. Když kontejner zemře, data do něj zapsaná jsou pryč.
Kubernetes má sadu objektů pro zpracování úložiště napříč moduly. První, o které budeme diskutovat, jsou svazky.
Svazky řeší jeden z největších problémů, pokud jde o trvalé úložiště. Za prvé, svazky nejsou ve skutečnosti objekty, ale definice specifikace pod. Když vytváříte pod, můžete definovat svazek pod polem specifikace podu. Kontejnery v tomto pod budou moci připojit svazek ve svém jmenném prostoru připojení a svazek bude k dispozici při restartování nebo selhání kontejneru. Svazky jsou však svázány s moduly, a pokud je modul odstraněn, svazek zmizí také. Údaje o objemu jsou jiný příběh; trvanlivost dat bude záviset na backendu daného svazku.
Kubernetes podporuje několik typů svazků nebo zdrojů svazků a jak se nazývají ve specifikacích API, které sahají od map souborového systému z místního uzlu, virtuálních disků poskytovatelů cloudu a softwarově definovaných svazků zálohovaných úložištěm. Místní připojení souborového systému jsou nejběžnější, která uvidíte, pokud jde o běžné svazky. Je důležité si uvědomit, že nevýhodou použití lokálního souborového systému uzlů je to, že data nebudou dostupná ve všech uzlech clusteru a pouze v tom uzlu, kde byl modul naplánován.
Podívejme se, jak je v YAML definován pod s objemem:
apiVersion:v1kind:Podmetadata:name:test-pdspec:container:- image:k8s.gcr.io/test-webserver name:test-container volumeMounts: - mountPath:/test-pd name:test-volume volumes:- name:test-volume hostPath: cesta:/data typ:Adresář
Všimněte si, že pod specifikací je pole nazvané volumes a poté je zde další pole s názvem volumeMounts.
První pole (objemy) je místo, kde definujete svazek, který chcete pro daný modul vytvořit. Toto pole bude vždy vyžadovat název a poté zdroj svazku. V závislosti na zdroji se budou požadavky lišit. V tomto příkladu by byl zdrojem hostPath, což je místní souborový systém uzlu. hostPath podporuje několik typů mapování, od adresářů, souborů, blokových zařízení a dokonce i soketů Unix.
Pod druhým polem, volumeMounts, máme mountPath, což je místo, kde definujete cestu uvnitř kontejneru, kam chcete svazek připojit. Parametr name je způsob, jakým podu určíte, který objem se má použít. To je důležité, protože pod svazky můžete mít definováno několik typů svazků a jediný způsob, jak modul zjistit, který bude název, bude
Více o různých typech svazků se můžete dozvědět zde https://kubernetes.io/docs/concepts/storage/volumes/#types-of-volumes a v referenčním dokumentu Kubernetes API (https://kubernetes.io/docs /reference/generated/kubernetes-api/v1.11/#volume-v1-core).
Mít objemy zemřít s lusky není ideální. Požadujeme úložiště, které přetrvává, a tak vznikla potřeba PV.
Hlavní rozdíl mezi svazky a PV je v tom, že na rozdíl od svazků jsou PV ve skutečnosti objekty Kubernetes API, takže je můžete spravovat jednotlivě jako samostatné entity, a proto přetrvávají i po odstranění pod.
Možná se divíte, proč má tato podsekce PV, trvalé objem nároky (PVC ) a třídy úložiště jsou všechny smíšené. Je to proto, že všechny na sobě závisí a pro zajištění úložiště pro naše moduly je zásadní pochopit, jak se vzájemně ovlivňují.
Let's begin with PVs and PVCs. Like volumes, PVs have a storage source, so the same mechanism that volumes have applies here. You will either have a software-defined storage cluster providing a logical unit number (LUN ), a cloud provider giving virtual disks, or even a local filesystem to the Kubernetes node, but here, instead of being called volume sources, they are called persistent volume types instead.
PVs are pretty much like LUNs in a storage array:you create them, but without a mapping; they are just a bunch of allocated storage waiting to be used. PVCs are like LUN mappings:they are backed or bound to a PV and also are what you actually define, relate, and make available to the pod that it can then use for its containers.
The way you use PVCs on pods is exactly the same as with normal volumes. You have two fields:one to specify which PVC you want to use, and the other one to tell the pod on which container to use that PVC.
The YAML for a PVC API object definition should have the following code:
apiVersion:v1kind:PersistentVolumeClaimmetadata:name:gluster-pvc spec:accessModes:- ReadWriteMany resources: requests: storage:1Gi
The YAML for pod should have the following code:
kind:PodapiVersion:v1metadata:name:mypodspec:containers: - name:myfrontend image:nginx volumeMounts: - mountPath:"/mnt/gluster" name:volume volumes: - name:volume persistentVolumeClaim: claimName:gluster-pvc
When a Kubernetes administrator creates PVC, there are two ways that this request is satisfied:
Storage classes are like a way of tiering your storage. You can create a class that provisions slow storage volumes, or another one with hyper-fast SSD drives. However, storage classes are a little bit more complex than just tiering. As we mentioned in the two ways of creating PVC, storage classes are what make dynamic provisioning possible. When working on a cloud environment, you don't want to be manually creating every backend disk for every PV. Storage classes will set up something called a provisioner , which invokes the volume plug-in that's necessary to talk to your cloud provider's API. Every provisioner has its own settings so that it can talk to the specified cloud provider or storage provider.
You can provision storage classes in the following way; this is an example of a storage class using Azure-disk as a disk provisioner:
kind:StorageClassapiVersion:storage.k8s.io/v1metadata:name:my-storage-classprovisioner:kubernetes.io/azure-diskparameters:storageaccounttype:Standard_LRS kind:Shared
Each storage class provisioner and PV type will have different requirements and parameters, as well as volumes, and we have already had a general overview of how they work and what we can use them for. Learning about specific storage classes and PV types will depend on your environment; you can learn more about each one of them by clicking on the following links:
In this article, we learned about what Kubernetes is, its components, and what are the advantages of using orchestration are. With this, identifying each of Kubernetes API objects, their purpose and their use cases should be easy. You should now be able to understand how the master nodes control the cluster and the scheduling of the containers in the worker nodes.
If you found this article useful, ‘ Hands-On Linux for Architects ’ should be helpful for you. With this book, you will be covering everything from Linux components and functionalities to hardware and software support, which will help you implementing and tuning effective Linux-based solutions. You will be taken through an overview of Linux design methodology and core concepts of designing a solution. If you’re a Linux system administrator, Linux support engineer, DevOps engineer, Linux consultant or anyone looking to learn or expand their knowledge in architecting, this book is for you.
Pods – základ Kubernetes
Deployments
Kubernetes a trvalé úložiště
Svazky
Trvalé svazky, nároky na trvalé svazky a třídy úložiště