Při stahování souborů není neobvyklé vidět .tar , .zip nebo .gz rozšíření. Víte ale, jaký je rozdíl mezi Tar a Zip a Gz? Proč je používáme a co je efektivnější, tar nebo zip nebo gz?
Rozdíl mezi tar, zip a gz
Pokud spěcháte nebo jen chcete získat něco snadno zapamatovatelného, zde je rozdíl mezi zip a tar a gz:
.tar ==nekomprimovaný archivní soubor
.zip ==(obvykle) komprimovaný archivní soubor
.gz ==soubor (archivovaný nebo ne) komprimovaný pomocí gzip

Něco z historie archivních souborů
Stejně jako mnoho věcí o Unixu a systémech podobných Unixu, příběh začíná už dávno, v ne tak vzdálené galaxii zvané sedmdesátá léta. Jednoho chladného rána ledna 1979 tar nástroj se objevil jako součást nově vydaného Unixu V7.
tar byl navržen jako způsob, jak efektivně zapisovat mnoho souborů na pásky. I když v dnešní době převážná většina jednotlivých uživatelů Linuxu páskové jednotky nezná, tarbally — přezdívka tar archivy — stále se běžně používají k zabalení několika souborů nebo dokonce celého stromu adresářů (nebo dokonce lesů) do jednoho souboru.
Jedna klíčová věc, kterou je třeba si zapamatovat, je obyčejný tar soubor je pouze archiv jejichž data nejsou komprimována. Jinými slovy, pokud tarujete 100 souborů o velikosti 50 kB, skončíte s archivem, jehož velikost bude přibližně 5000 kB. Jediným přínosem, který můžete očekávat při použití samotného tar, by bylo zamezení plýtvání prostorem souborovým systémem, protože většina z nich alokuje prostor s určitou granularitou (například v mém systému používá jeden bajt dlouhý soubor 4 kB místa na disku, 1 000 budou používat 4 MB, ale odpovídající archiv tar „pouze“ 1 MB).
| Zde stojí za zmínku tar rozhodně není jediným standardním unixovým nástrojem pro vytváření archivů. Programátoři pravděpodobně znají ar jak se dnes většinou používá k vytváření statických knihoven, které nejsou ničím víc než archivy kompilovaných soubory. Ale jsem lze použít k vytváření archivů jakéhokoli druhu. Ve skutečnosti .deb soubory balíčků používané na systémech Debian jsou ar archiv! A v systému MacOS X mpkg balíčky jsou (byly?) komprimované pomocí gzip cpio archiv. To bylo řečeno, ani nejsem ani cpio získal stejnou popularitu jako tar mezi uživateli. Možná proto, že příkaz tar byl dostatečně dobrý a jednodušší na použití. |

Vytváření archivů je fajn. Ale jak čas plynul a s příchodem éry osobních počítačů, lidé si uvědomili, že mohou výrazně ušetřit na úložišti pomocí komprese data. Tedy deset let po představení nebo tar , zip vyšel ve světě MS-DOS jako formát archivu podporující kompresi . Nejběžnější schéma komprese pro zip je deflovat který je sám o sobě implementací algoritmu LZ77. Ale je komerčně vyvinut společností PKWARE, zip formát trpěl roky zatěžováním patentů.
Takže souběžně gzip byl vytvořen za účelem implementace algoritmu LZ77 ve svobodném softwaru bez porušení patentu PKWARE.
Klíčovým prvkem filozofie Unixu je „Dělej jednu věc a dělej to dobře“ , gzip byl navržen pouze komprimovat soubory. Chcete-li tedy vytvořit komprimovaný archiv , musíte nejprve vytvořit archiv pomocí tar užitečnost například. A poté budete komprimovat ten archiv. Toto je .tar.gz soubor (někdy zkrácený jako .tgz znovu přidat k tomuto zmatku – a splnit dlouho zapomenutá omezení názvů souborů MS-DOS 8.3).
Jak se počítačová věda vyvíjela, byly pro vyšší kompresní poměr navrženy další kompresní algoritmy. Například algoritmus Burrows–Wheeler implementovaný v bzip2 (vedoucí k .tar.bz2 archiv). Nebo nověji xz což je LZMA implementace algoritmu podobná té, která se používá v 7zip utility.
Dostupnost a omezení
Dnes můžete volně používat jakýkoli formát archivního souboru v Linuxu i ve Windows.
Ale jako zip formát je nativně podporován ve Windows, tento je zvláště přítomen v multiplatformních prostředích. Můžete dokonce najít zip formátu souboru na neočekávaných místech. Například tento formát souboru byl společností Sun zachován pro JAR archivy používané k distribuci zkompilovaných aplikací Java. Nebo pro soubory OpenDocument (.odf , .odp …) používané LibreOffice nebo jinými kancelářskými balíky. Všechny tyto formáty souborů jsou archivy ZIP v přestrojení. Pokud jste zvědaví, neváhejte rozbalit jeden z nich, abyste viděli, co je uvnitř:
sh$ unzip some-file.odt Archive:some-file.odt extracting: mimetype inflating: meta.xml inflating: settings.xml inflating: content.xm [...] inflating: styles.xml inflating: META-INF/manifest.xml
Vše, co bylo řečeno, ve světě podobném Unixu Já by stále preferoval tar typ archivu, protože zip formát souboru nepodporuje spolehlivě všechna metadata souborového systému Unix. Pro některá konkrétní vysvětlení tohoto posledního prohlášení musíte vědět, že formát souboru ZIP definuje pouze malou sadu povinných atributů souboru, které se mají uložit pro každý záznam:název souboru, datum úpravy, oprávnění. Kromě těchto základních atributů může archivátor ukládat další metadata v takzvaném zvláštním poli záhlaví ZIP. Ale protože další pole jsou definována implementací, ani pro vyhovující archivátory neexistují žádné záruky, že ukládají nebo načítají stejnou sadu metadat. Pojďme si to ověřit na ukázkovém archivu:
sh$ ls -lsn data/team total 0 0 -rw-r--r-- 1 1000 2000 0 Jan 30 12:29 team sh$ zip -0r archive.zip data/
sh$ zipinfo -v archive.zip data/team Central directory entry #5: --------------------------- data/team [...] apparent file type: binary Unix file attributes (100644 octal): -rw-r--r-- MS-DOS file attributes (00 hex): none The central-directory extra field contains: - A subfield with ID 0x5455 (universal time) and 5 data bytes. The local extra field has UTC/GMT modification/access times. - A subfield with ID 0x7875 (Unix UID/GID (any size)) and 11 data bytes: 01 04 e8 03 00 00 04 d0 07 00 00.
Jak vidíte, informace o vlastnictví (UID/GID) jsou součástí dodatečného pole – nemusí být zřejmé, pokud neznáte hexadecimální nebo metadata ZIP jsou uloženy little-endian, ale zkráceně „e803“ je „03e8“ s „1000“, což je UID souboru. A „07d0“ je „d007“, což je 2000, GID souboru.
V tomto konkrétním případě zip Info-ZIP nástroj dostupný na mém systému Debian uložil některá užitečná metadata do zvláštního pole. Neexistuje však žádná záruka, že toto pole navíc zapíše každý archivátor. A i když je přítomen, neexistuje žádná záruka, že to nástroj použitý k extrahování archivu pochopí.
Vzhledem k tomu, že nemůžeme odmítnout tradici jako motivaci pro stále používání tarballů , s tímto malým příkladem chápete, proč stále existují některé (rohové?) případy, kdy tar nelze nahradit zip . To platí zejména v případě, že chcete zachovat vše standardní metadata souboru.
Test účinnosti Tar vs Zip vs Gz
Budu zde mluvit o prostorové efektivitě, nikoli o časové efektivitě – ale obecně platí, že potenciálně efektivnější je kompresní algoritmus, vyžaduje více CPU.
A abyste si udělali představu o kompresním poměru získaném pomocí různých algoritmů, shromáždil jsem na svém pevném disku asi 100 MB souborů z oblíbených formátů souborů. Zde jsou výsledky získané na mém systému Debian Stretch (všechny velikosti, jak uvádí du -sh ):
| typ souboru | .jpg | .mp3 | .mp4 | .odt | .png | .txt |
| počet souborů | 2163 | 45 | 279 | 2990 | 2072 | 4397 |
| místo na disku | 98 mil. | 99 milionů | 99 milionů | 98 mil. | 98 mil. | 98 mil. |
| tar | 94 mil. | 99 milionů | 98 mil. | 93 mil. | 92 mil. | 89 mil. |
| zip (bez komprese) | 92 mil. | 99 milionů | 98 mil. | 91 mil. | 91 mil. | 86 mil. |
| zip (deflate) | 87 mil. | 98 mil. | 93 mil. | 85 mil. | 77 mil. | 28 mil. |
| tar + gzip | 86 mil. | 98 mil. | 93 mil. | 82 mil. | 77 mil. | 27 mil. |
| tar + bz2 | 87 mil. | 98 mil. | 93 mil. | 42 mil. | 71 mil. | 22 mil. |
| tar + xz | 70 mil. | 98 mil. | 22 mil. | 348 kB | 51 mil. | 19 milionů |
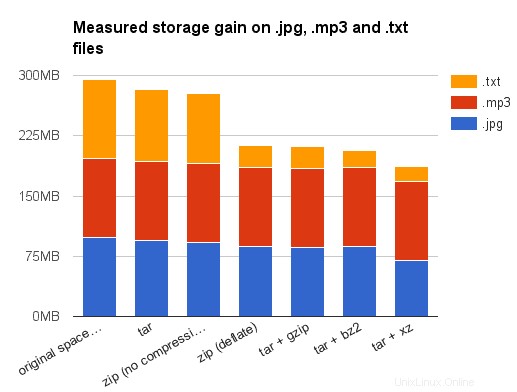 Nejprve vám doporučuji, abyste tyto výsledky brali s velkou rezervou:datové soubory byly ve skutečnosti visící soubory na mém pevném disku a v žádném případě bych je netvrdil, že jsou reprezentativní. Pak se musím přiznat, že jsem tyto typy souborů nevybral náhodně. Už jsem to řekl, .odt soubory jsou již soubory zip. Takže mírný zisk získaný jejich komprimací podruhé není překvapivý (s výjimkou bzip2 nebo xy, ale bych považovat to za statistickou abnormalitu způsobenou nízkou heterogenitou mých datových souborů – obsahujících několik záloh nebo pracovních verzí stejných dokumentů).
Nejprve vám doporučuji, abyste tyto výsledky brali s velkou rezervou:datové soubory byly ve skutečnosti visící soubory na mém pevném disku a v žádném případě bych je netvrdil, že jsou reprezentativní. Pak se musím přiznat, že jsem tyto typy souborů nevybral náhodně. Už jsem to řekl, .odt soubory jsou již soubory zip. Takže mírný zisk získaný jejich komprimací podruhé není překvapivý (s výjimkou bzip2 nebo xy, ale bych považovat to za statistickou abnormalitu způsobenou nízkou heterogenitou mých datových souborů – obsahujících několik záloh nebo pracovních verzí stejných dokumentů).
Ohledně .jpg , .mp3 a .mp4 teď:možná víte, že již jsou komprimovaný datový soubor. Ještě lepší je, že jste možná slyšeli, že používají destruktivní kompresi . To znamená, že nemůžete rekonstruovat přesně původní obrázek po kompresi JPEG. a to je pravda. Co se ale málo ví, je po destruktivní kompresní fázi per se , jsou data komprimována podruhé pomocí nedestruktivního Huffmanova algoritmu proměnné délky slova, aby se odstranila redundance dat.
Ze všech těchto důvodů se očekávalo, že komprimace obrázků ve formátu JPEG nebo souborů MP3/MP4 nezanechá vysoké zisky. Vezměte prosím na vědomí, že typický soubor obsahuje jak vysoce komprimovaná data, tak některá nekomprimovaná metadata, stále tam můžeme něco málo získat. To vysvětluje, proč mám stále znatelný zisk pro obrázky JPEG, protože jsem jich měl mnoho – takže celková velikost metadat nebyla ve srovnání s celkovou velikostí souboru tak zanedbatelná. Opět překvapivé výsledky při komprimaci souborů MP4 pomocí xz pravděpodobně souvisí s vysokou podobností mezi různými soubory MP4 použitými během mých testů. Nebo nejsou?
Abyste nakonec tyto pochybnosti rozptýlili, důrazně vám doporučuji provést vlastní srovnání. A neváhejte se s námi podělit o své postřehy pomocí sekce komentářů níže!