Nástroje jako sed (editor streamu) a grep (globální tisk regulárních výrazů) jsou účinnými způsoby, jak ušetřit čas a zrychlit práci. Než se ponořím hluboko do případů použití, rád bych stručně vysvětlil regulární výrazy (regexy), které jsou nezbytné pro manipulaci s textem, kterou uděláme později.
Co jsou regulární výrazy? Když se zabýváme log soubory, textovými soubory nebo částí kódu, my
musíte pochopit, že všechny tyto sestávají ze znaků. Když je délka souboru velká, stává se nutností odfiltrovat určité vzory, aby bylo ladění jednodušší. V těchto případech použití naleznete příklady regulárních výrazů.
Skupina 1:Data serveru
Řekněme, že máte soubor s výskytem řetězce:
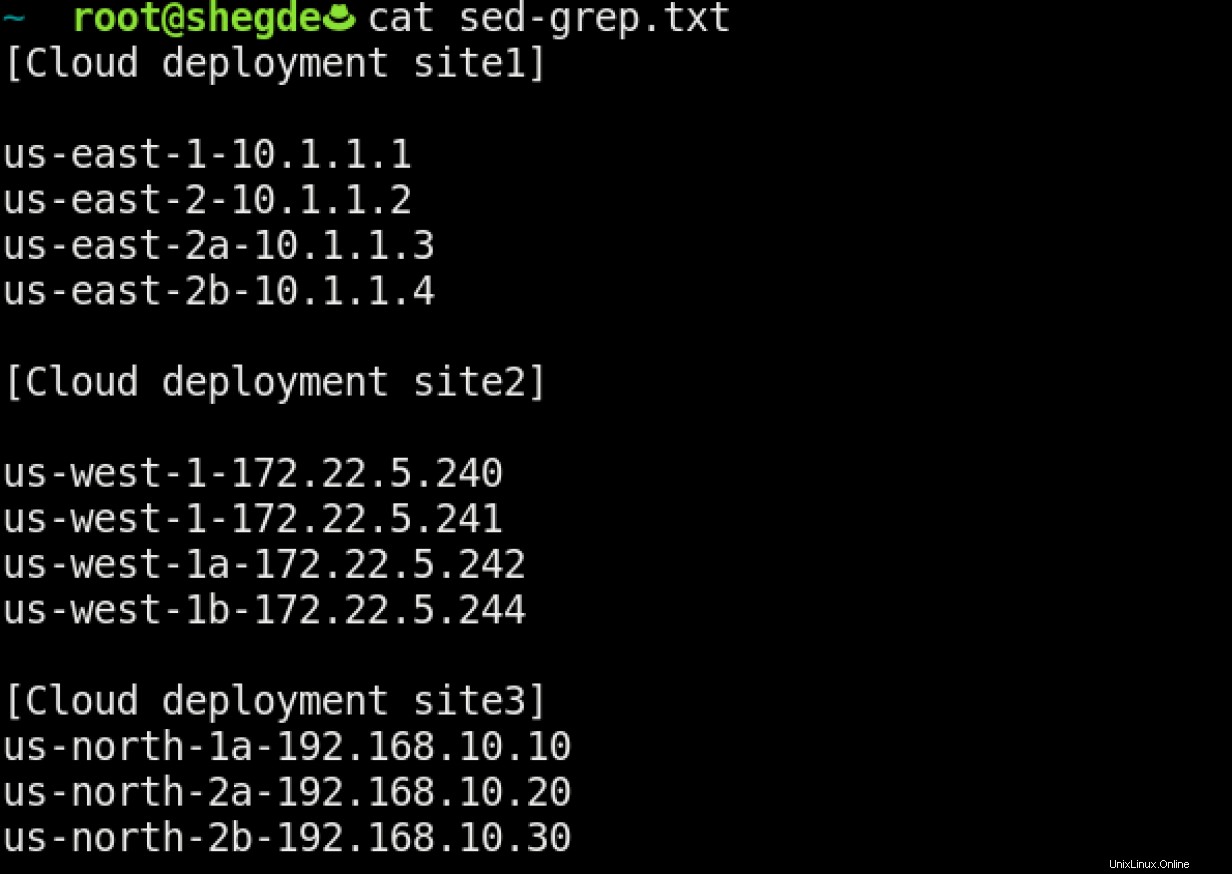
Nyní, jak odfiltrujete site1 podrobnosti (výše uvedený soubor je jednoduchý příklad), abyste mohli získat pouze nezbytné informace a manipulovat se záznamy?
Jasně vidíme, že v celém souboru existuje společný vzor („nasazení cloudu“). Nyní tedy můžeme použít techniky filtrování k získání informací ze souboru pomocí grep . Pamatuji si to jako "získat regulární výraz n tisk."
Případ použití 1
Pokud chci servery z různých regionů, mohu použít grep následovně:
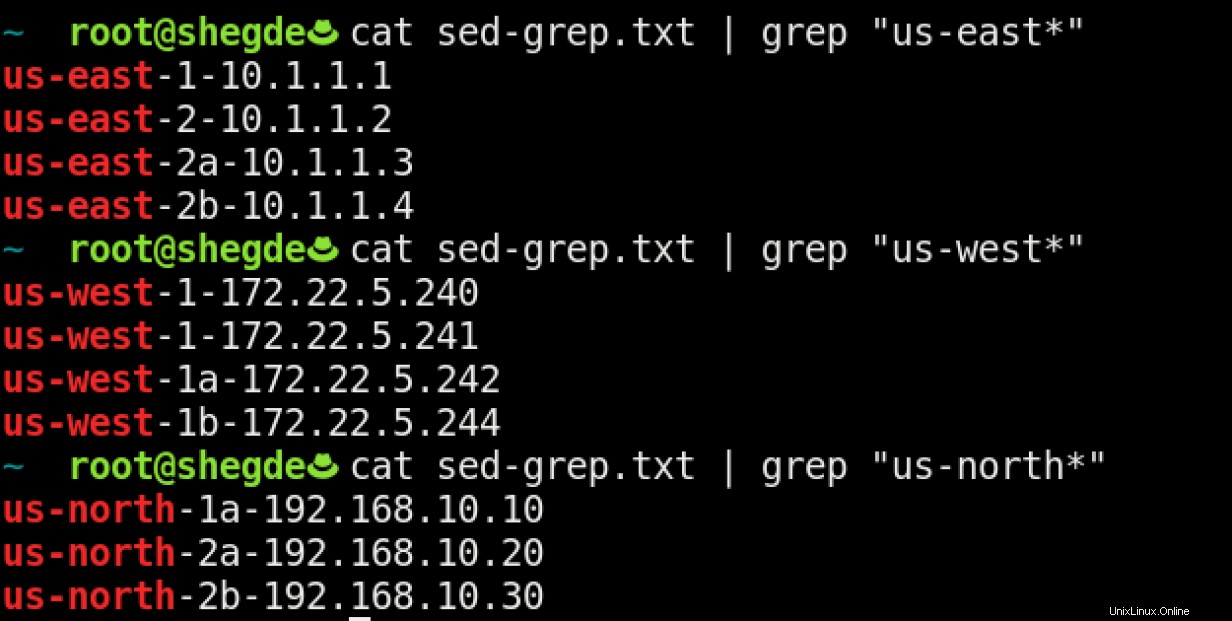
Případ použití 2
Nyní řekněte, že víte, že chcete odfiltrovat servery na základě IP. Totéž můžete provést pomocí:
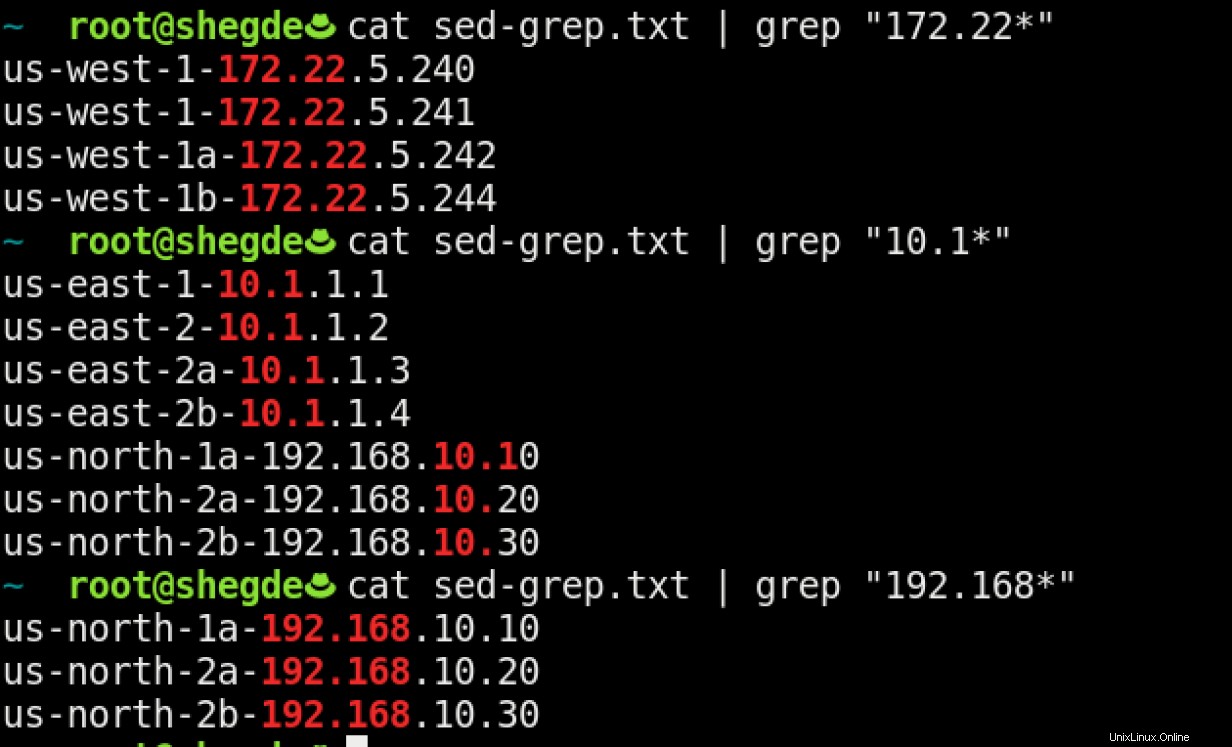
Případ použití 3
Nyní se podívejte na první grep příkazový obrázek. Přestože jste znali rozsah podsítě vašeho systému, příkaz vypsal v celém souboru výskyt 10.1.
Jak můžete vyřešit tento typ případu použití? Tento problém můžeme vyřešit pomocí pokročilého filtrování založeného na regulárních výrazech, jako je toto:
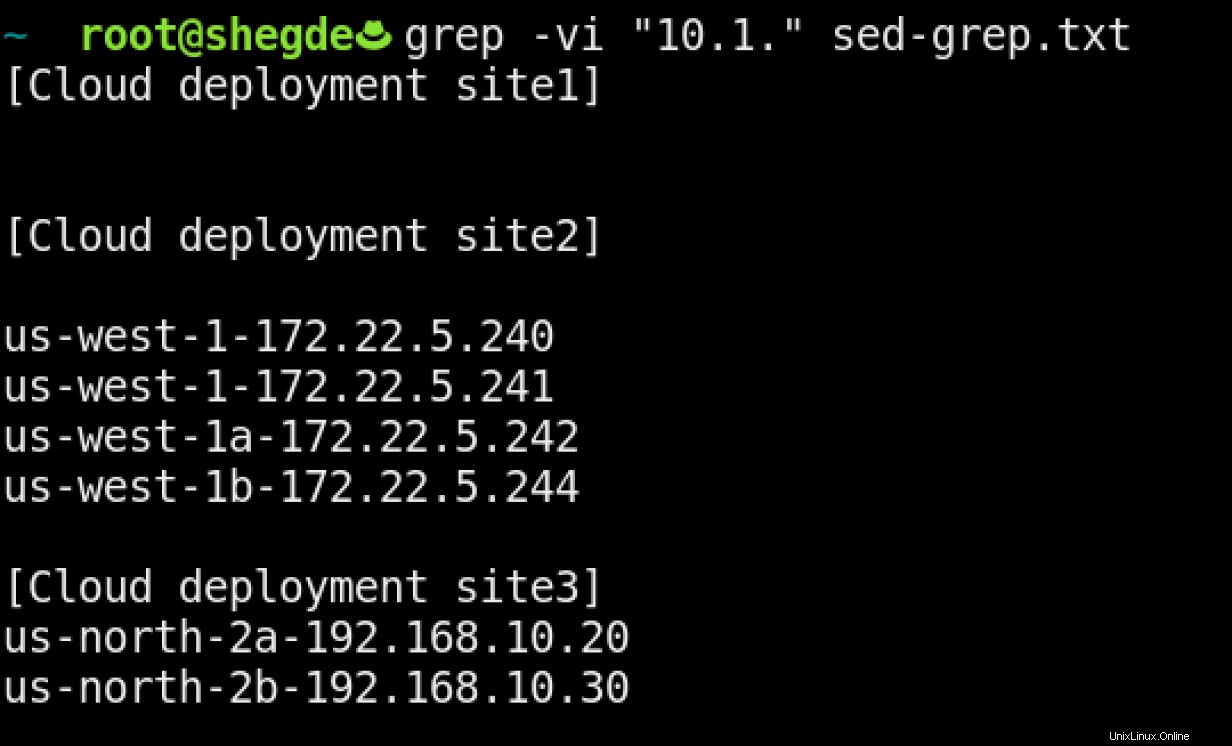
Tento příklad je pouze možným použitím grep . Opět, protože se jedná o relativně malý soubor, můžete získat to, co chcete, pomocí toho, co je uvedeno výše. -v přepínač obrátí vyhledávací kritéria, což znamená, že grep prohledá soubor sed-grep.txt a vytiskne všechny podrobnosti kromě <search-pattern> (v tomto případě 10.1).
Případ použití 4
Řekněme, že chcete nahradit adresy IP a přesunout všechny servery v těchto oblastech do jiné podsítě. Můžete použít sed pro tento případ použití.
Z manuálové stránky sed používá formát:
sed [options] commands [file-to-edit]
Náš příkaz pro tento případ použití může vypadat takto:
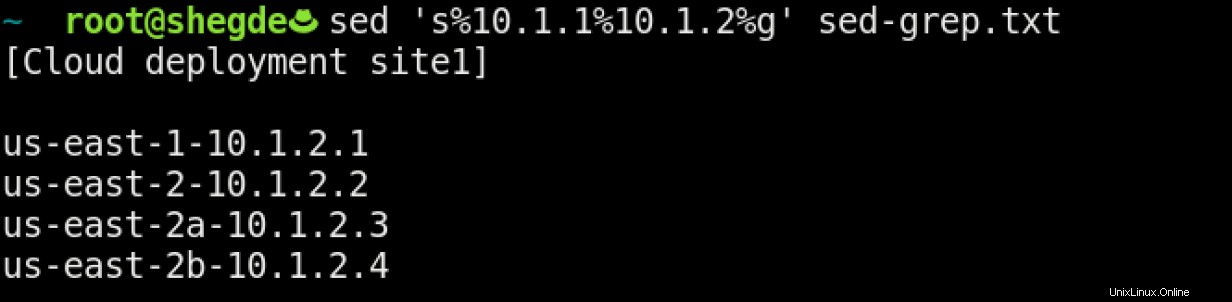
Tento příkaz se dělí následovně:
- Znaky
sznamená náhražku. %je oddělovač (zde můžeme použít libovolné znaky).<search pattern>objeví se za prvním%.<replace pattern>se objeví za druhým%.gznamená globální nahrazení (což znamená v celém souboru).
Nebo:
s%<search-pattern>%<replace-pattern>%g
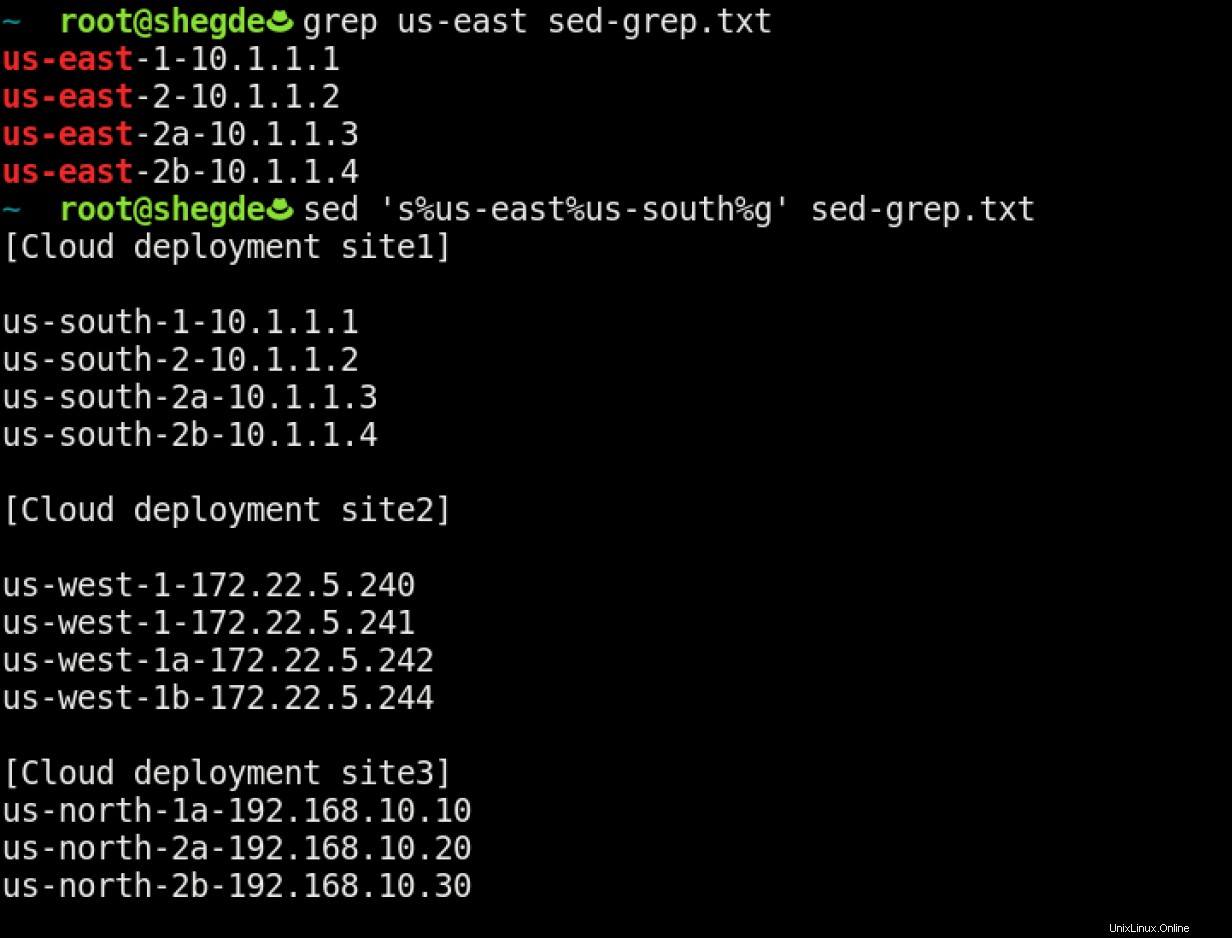
Případ použití 5
Můžete dokonce změnit regiony serverů v souboru:
Případ použití 6
Tento případ použití je pokročilejší. Odebereme pouze komentáře (# ) ze souboru pomocí sed :
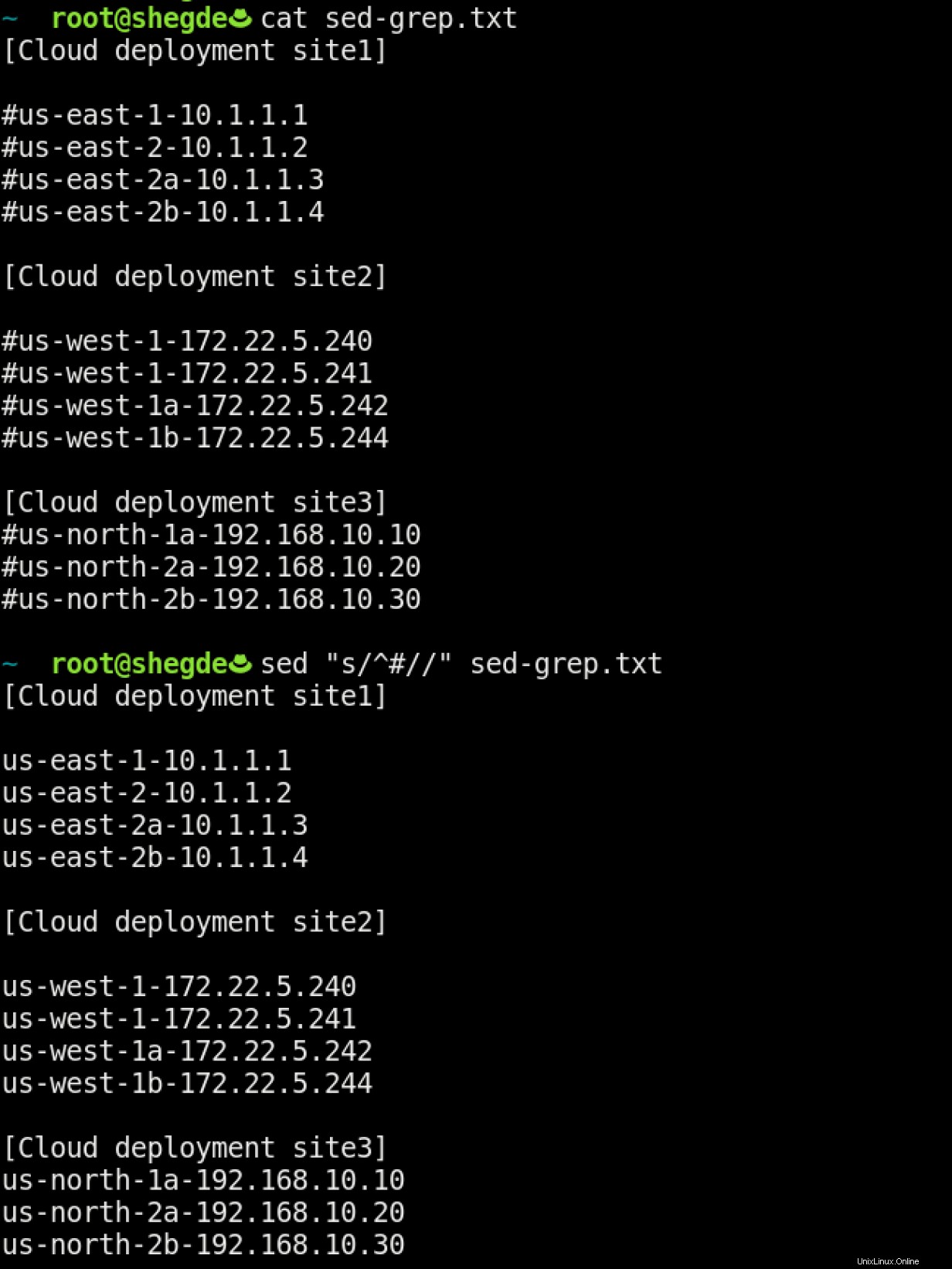
Tento příkaz říká, že if # se objeví jako první znak řádku, aby byl tento řádek nahrazen mezerou. Výsledkem je, že tento příkaz odstraní komentáře ze souboru.
Skupina 2:/etc/passwd
Podívejme se na další případy použití, tentokrát zahrnující /etc/passwd .
Případ použití 1
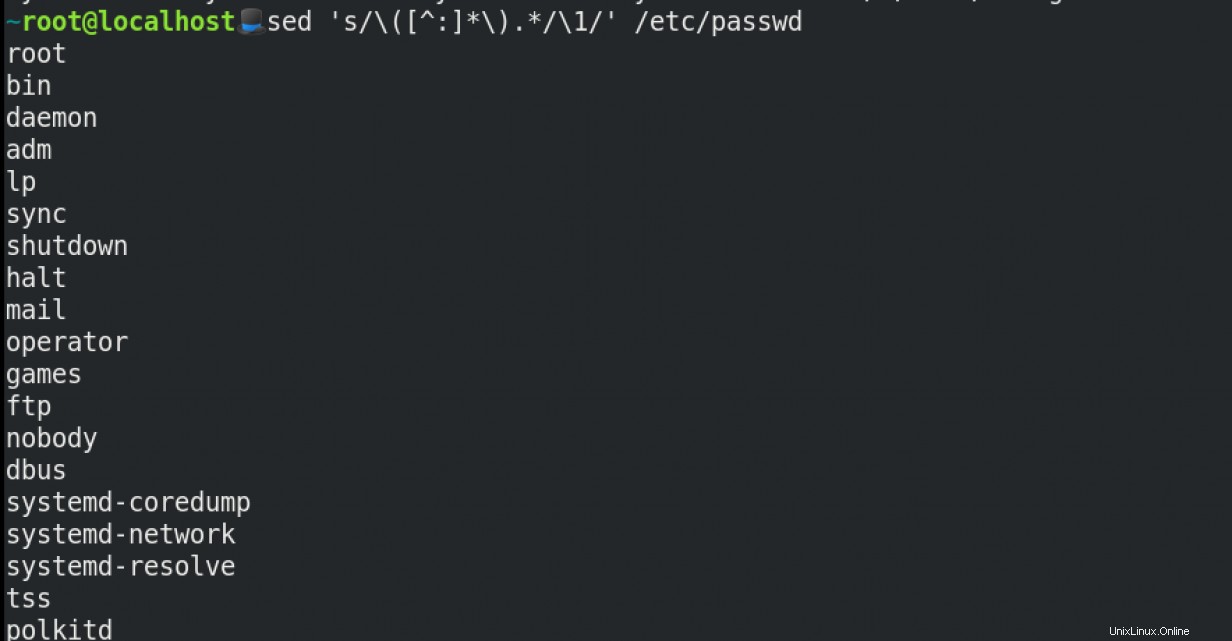
Předpokládejme, že chcete získat uživatele ze souboru /etc/passwd soubor. Můžete použít sed takto:
Případ použití 2
Co když chcete získat pouze prvních 10 uživatelů z /etc/passwd ? Můžete použít sed a awk pro tento účel (prosím mějte strpení):
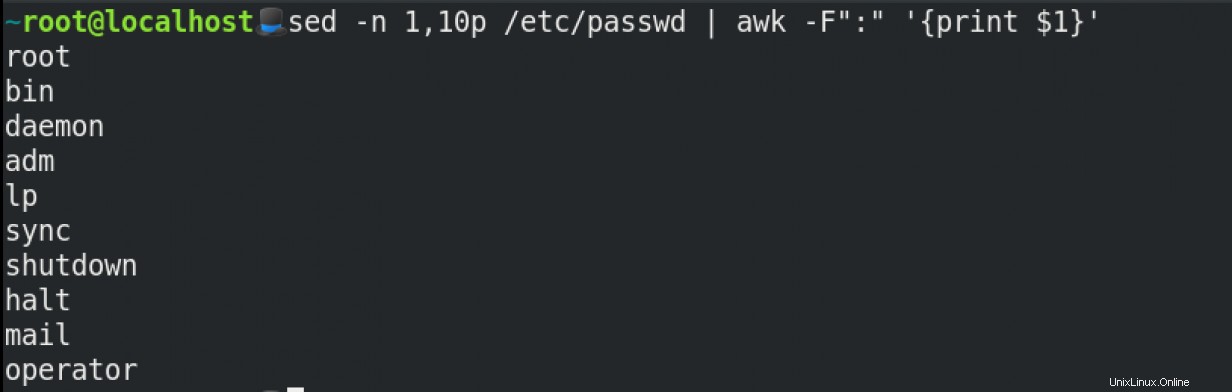
Tento příkaz se dělí takto:
sed -nznamená netisknout vše.pvytiskne řádky od 1 do 10.awkzde používá:jako oddělovač polí a vytiskne první sloupec.
Případ použití 3
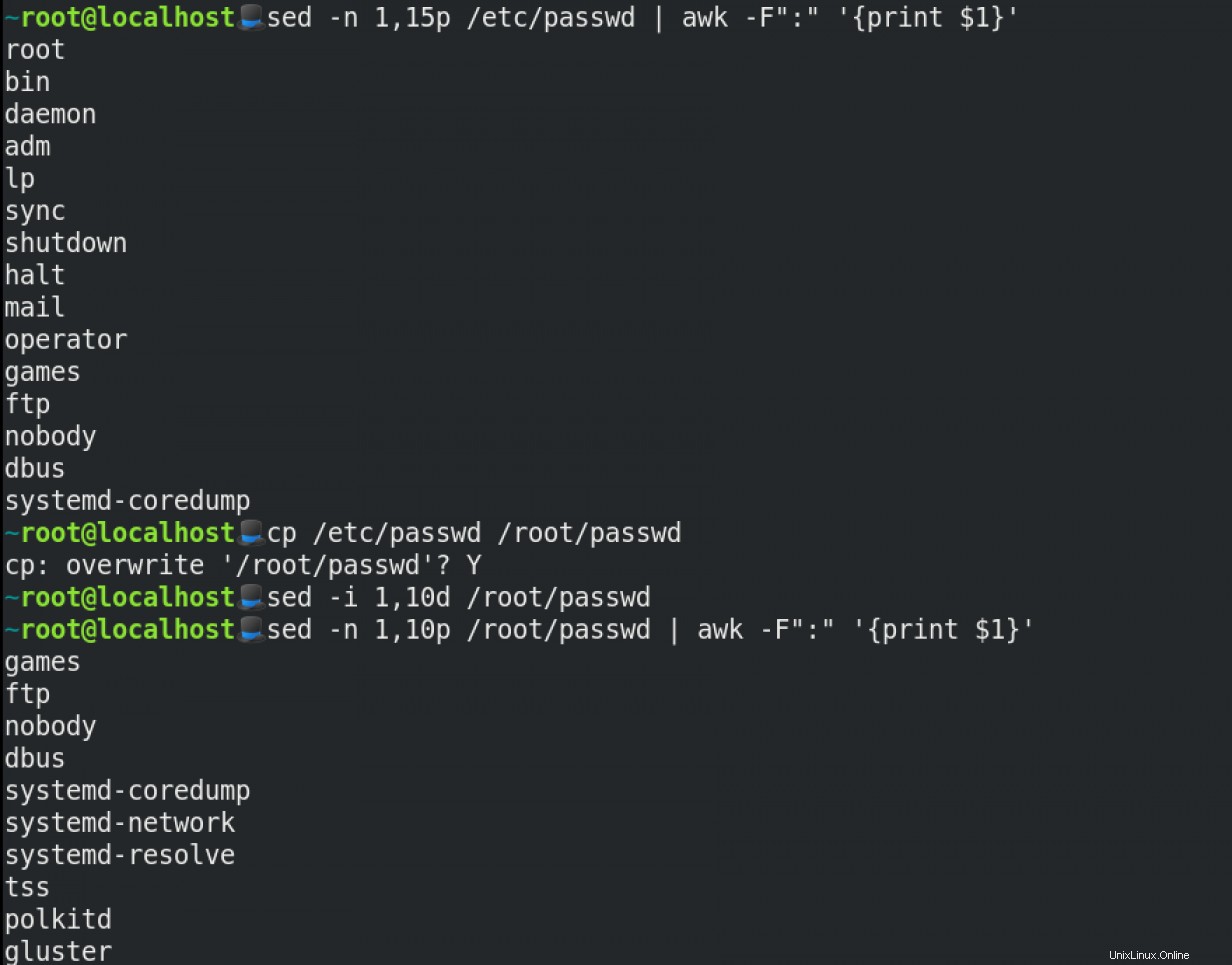
Smažte určitý rozsah řádků v textových souborech pomocí sed :
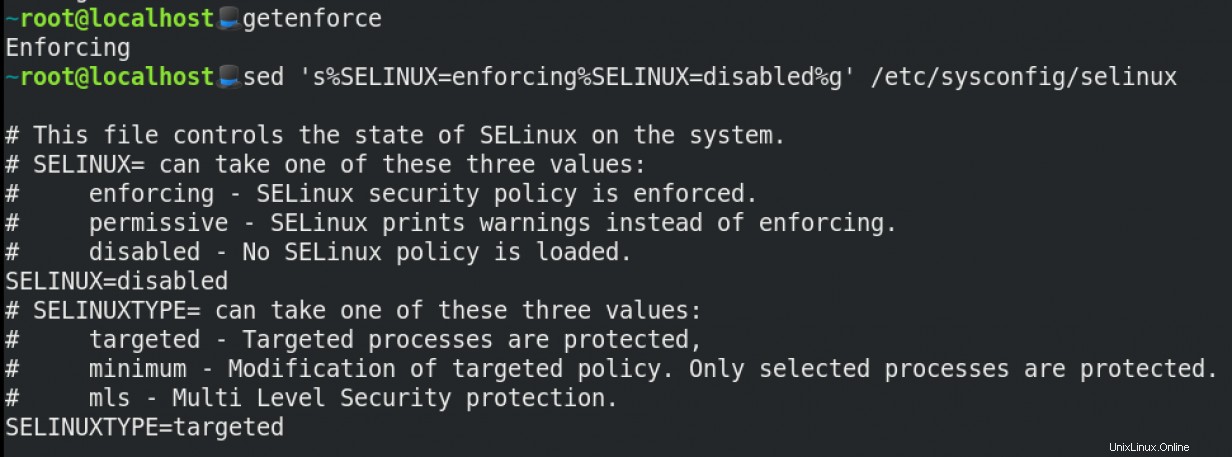
Případ použití SELinux
Zde je příklad sed příkaz pro manipulaci se SELinux:
Závěr
Toto je můj pokus poskytnout vám čtenářům jen malý náhled na možnosti použití sed a grep . Pomocí těchto příkazů můžete provádět mnoho textových manipulací. Chcete-li se dozvědět více, podívejte se na různé možnosti pomocí manuálové stránky.
[Chcete vyzkoušet Red Hat Enterprise Linux? Stáhněte si jej nyní zdarma.]