Představte si, že máte soubor (nebo hromadu souborů) a chcete v těchto souborech vyhledat konkrétní řetězec nebo nastavení konfigurace. Otevřít každý soubor jednotlivě a pokusit se najít konkrétní řetězec by bylo únavné a pravděpodobně to není správný přístup. Co tedy můžeme použít?
Existuje mnoho nástrojů, které můžeme použít v systémech založených na *nixu k nalezení a manipulaci s textem. V tomto článku se budeme zabývat grep příkaz k vyhledání vzorů, ať už nalezených v souborech nebo pocházejících ze streamu (soubor nebo vstup z kanálu nebo | ). V připravovaném článku také uvidíme, jak používat sed (Editor streamu) pro manipulaci se streamem.
Nejlepší způsob, jak pochopit fungování programu nebo nástroje, je podívat se na jeho manuálovou stránku. Mnoho (pokud ne všechny) unixové nástroje poskytuje během instalace manuálové stránky. Na systémech založených na Red Hat Enterprise Linux můžeme spustit následující pro výpis grep soubory dokumentace:
$ rpm -qd grep
/usr/share/doc/grep/AUTHORS
/usr/share/doc/grep/NEWS
/usr/share/doc/grep/README
/usr/share/doc/grep/THANKS
/usr/share/doc/grep/TODO
/usr/share/info/grep.info.gz
/usr/share/man/man1/egrep.1.gz
/usr/share/man/man1/fgrep.1.gz
S manuálovými stránkami, které máme k dispozici, můžeme nyní používat grep a prozkoumejte jeho možnosti.
grep základy
V této části článku používáme words soubor, který najdete na následujícím umístění:
$ ls -l /usr/share/dict/words
lrwxrwxrwx. 1 root root 11 Feb 3 2019 /usr/share/dict/words -> linux.words
Tento soubor obsahuje 479 826 slov a je poskytován pomocí words balík. V mém systému Fedora je tento balíček words-3.0-33.fc30.noarch . Když vypíšeme obsah words soubor, vidíme následující výstup:
$ cat /usr/share/dict/words
1080
10-point
10th
11-point
[……]
[……]
zyzzyva
zyzzyvas
ZZ
Zz
zZt
ZZZ
Dobře, takže jsme řekli words soubor obsahoval 479 826 řádků, ale jak to víme? Pamatujte, že jsme mluvili o manuálových stránkách dříve. Podívejme se, zda grep nabízí možnost počítat řádky v daném souboru.
Je ironií, že budeme používat grep grep pro volbu takto:

Takže samozřejmě potřebujeme -c , nebo dlouhá možnost --count , abyste spočítali počet řádků v daném souboru. Počítání řádků v /usr/share/dict/words výnosy:
$ grep -c '.' /usr/share/dict/words
479826
'.' znamená, že budeme počítat všechny řádky obsahující alespoň jeden znak, mezeru, mezeru, tabulátor atd.
Základní grep regulární výrazy
grep příkaz se stává silnějším, když používáme regulární výrazy (regexy). Zatímco se tedy zaměříme na grep samotný příkaz, dotkneme se také základní syntaxe regulárního výrazu.
Předpokládejme, že nás zajímají pouze slova začínající Z . V této situaci se regexy hodí. Používáme karát (^ ) pro vyhledání vzorů začínajících určitým znakem označujícím začátek řetězce:
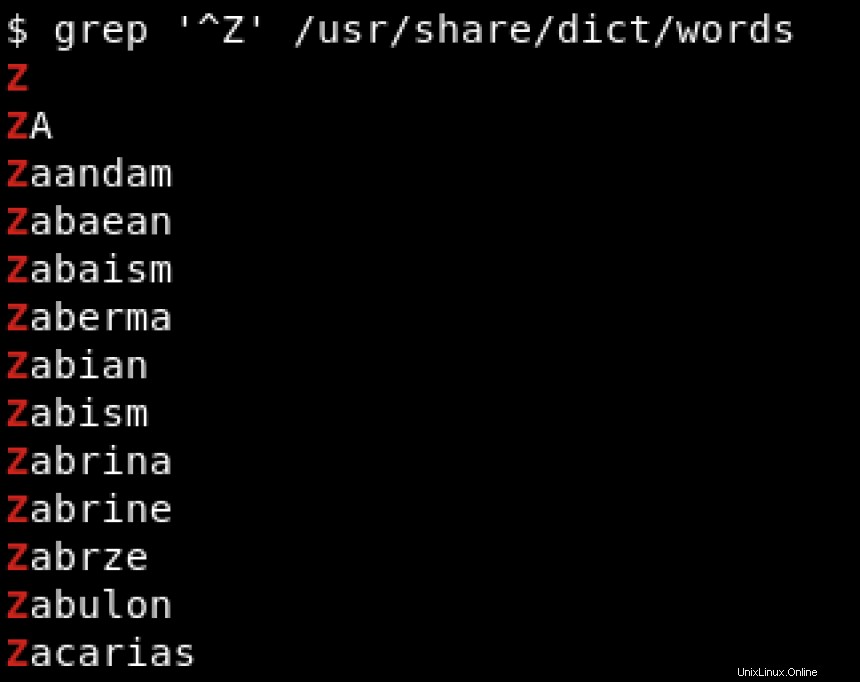
K vyhledání vzorů končících konkrétním znakem používáme znak dolaru ($ ) pro označení konce řetězce. Podívejte se na níže uvedený příklad, kde hledáme řetězce končící na hat :
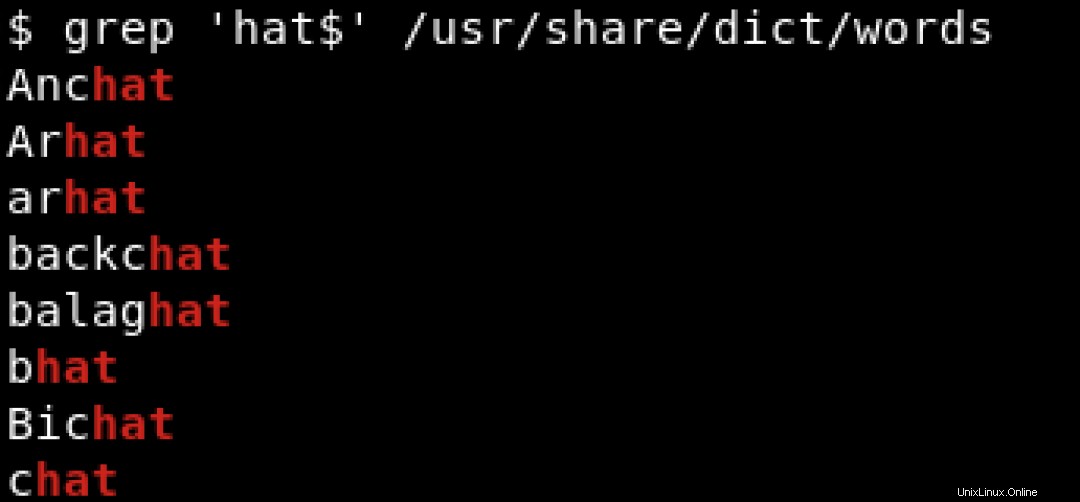
Chcete-li vytisknout všechny řádky, které obsahují hat bez ohledu na jeho polohu, ať už na začátku řádku nebo na konci řádku, použijeme něco jako:
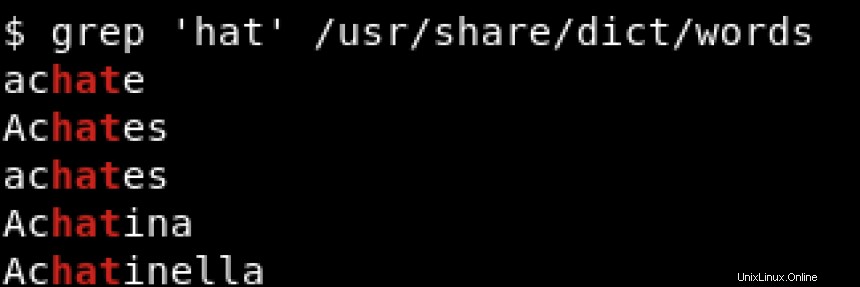
^ a $ se nazývají metaznaky a měly by být ukončeny zpětným lomítkem (\ ), když chceme tyto znaky doslova srovnat. Pokud se chcete dozvědět více o metaznakech, navštivte https://www.regular-expressions.info/characters.html.
Příklad:Odebrání komentářů
Nyní, když jsme poškrábali povrch grep , pojďme pracovat na některých scénářích ze skutečného světa. Mnoho konfiguračních souborů v *nix obsahuje komentáře, které popisují různá nastavení v konfiguračním souboru. Soubor /etc/fstab , soubor má například:
$ cat /etc/fstab
#
# /etc/fstab
# Created by anaconda on Thu Oct 27 05:06:06 2016
#
# Accessible filesystems, by reference, are maintained under '/dev/disk'
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
#
/dev/mapper/VGCRYPTO-ROOT / ext4 defaults,x-systemd.device-timeout=0 1 1
UUID=e9de0f73-ddddd-4d45-a9ba-1ffffa /boot ext4 defaults 1 2
LABEL=SSD_SWAP swap swap defaults 0 0
#/dev/mapper/VGCRYPTO-SWAP swap swap defaults,x-systemd.device-timeout=0 0 0
Komentáře jsou označeny křížkem (# ), a při tisku je chceme ignorovat. Jednou z možností je cat příkaz:
$ cat /etc/fstab | grep -v '^#'
Nepotřebujete však cat zde (vyhněte se zbytečnému použití Cat). grep příkaz je dokonale schopen číst soubory, takže místo toho můžete použít něco takového k ignorování řádků, které obsahují komentáře:
$ grep -v '^#' /etc/fstab
Pokud chcete místo toho odeslat výstup (bez komentářů) do jiného souboru, použijte:
$ grep -v '^#' /etc/fstab > ~/fstab_without_comment
Zatímco grep může formátovat výstup na obrazovce, tento příkaz není schopen upravit soubor na místě. K tomu bychom potřebovali souborový editor jako ed . V dalším článku budeme používat sed abychom dosáhli toho, co jsme udělali zde s grep .
Příklad:Odstraňte komentáře a prázdné řádky
Když jsme stále u grep , podívejme se na /etc/sudoers soubor. Tento soubor obsahuje mnoho komentářů, ale nás zajímají pouze řádky, které nemají žádné komentáře, a také se chceme zbavit prázdných řádků.
Nejprve tedy odstraníme řádky obsahující komentáře. Vytvoří se následující výstup:
# grep -v '^#' /etc/sudoers
Defaults !visiblepw
Defaults env_reset
Defaults env_keep = "COLORS DISPLAY HOSTNAME HISTSIZE KDEDIR LS_COLORS"
Defaults env_keep += "MAIL PS1 PS2 QTDIR USERNAME LANG LC_ADDRESS LC_CTYPE"
Defaults env_keep += "LC_COLLATE LC_IDENTIFICATION LC_MEASUREMENT LC_MESSAGES"
Defaults env_keep += "LC_MONETARY LC_NAME LC_NUMERIC LC_PAPER LC_TELEPHONE"
Defaults env_keep += "LC_TIME LC_ALL LANGUAGE LINGUAS _XKB_CHARSET XAUTHORITY"
Defaults secure_path = /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
root ALL=(ALL) ALL
%wheel ALL=(ALL) ALL
Nyní se chceme zbavit prázdných (prázdných) řádků. No, to je snadné, stačí spustit další grep příkaz:
# grep -v '^#' /etc/sudoers | grep -v '^$'
Defaults !visiblepw
Defaults env_reset
Defaults env_keep = "COLORS DISPLAY HOSTNAME HISTSIZE KDEDIR LS_COLORS"
Defaults env_keep += "MAIL PS1 PS2 QTDIR USERNAME LANG LC_ADDRESS LC_CTYPE"
Defaults env_keep += "LC_COLLATE LC_IDENTIFICATION LC_MEASUREMENT LC_MESSAGES"
Defaults env_keep += "LC_MONETARY LC_NAME LC_NUMERIC LC_PAPER LC_TELEPHONE"
Defaults env_keep += "LC_TIME LC_ALL LANGUAGE LINGUAS _XKB_CHARSET XAUTHORITY"
Defaults secure_path = /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
root ALL=(ALL) ALL
%wheel ALL=(ALL) ALL
valentin.local ALL=NOPASSWD: /usr/bin/updatedb
Mohli bychom to udělat lépe? Mohli bychom spustit náš grep příkaz, aby byl šetrnější ke zdrojům a neforkoval grep dvakrát? Určitě můžeme:
# grep -Ev '^#|^$' /etc/sudoers
Defaults !visiblepw
Defaults env_reset
Defaults env_keep = "COLORS DISPLAY HOSTNAME HISTSIZE KDEDIR LS_COLORS"
Defaults env_keep += "MAIL PS1 PS2 QTDIR USERNAME LANG LC_ADDRESS LC_CTYPE"
Defaults env_keep += "LC_COLLATE LC_IDENTIFICATION LC_MEASUREMENT LC_MESSAGES"
Defaults env_keep += "LC_MONETARY LC_NAME LC_NUMERIC LC_PAPER LC_TELEPHONE"
Defaults env_keep += "LC_TIME LC_ALL LANGUAGE LINGUAS _XKB_CHARSET XAUTHORITY"
Defaults secure_path = /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
root ALL=(ALL) ALL
%wheel ALL=(ALL) ALL
valentin.local ALL=NOPASSWD: /usr/bin/updatedb
Zde jsme představili další grep možnost, -E (nebo --extended-regexp ) <PATTERN> je rozšířený regulární výraz.
Příklad:Pouze tisk /etc/passwd uživatelé
Je zřejmé, že grep je výkonný při použití s regulárními výrazy. Tento článek pokrývá pouze malou část toho, co grep je opravdu schopen. Demonstrovat schopnosti grep a použití regulárních výrazů, analyzujeme /etc/passwd soubor a tiskněte pouze uživatelská jména.
Formát souboru /etc/passwd soubor je následující:
$ head /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
Výše uvedená pole mají následující význam:
<name>:<password>:<UID>:<GID>:<GECOS>:<directory>:<shell>
Viz man 5 passwd pro více informací o /etc/passwd soubor. Chcete-li vytisknout pouze uživatelská jména, mohli bychom použít něco jako následující:
$ grep -Eo '^[a-zA-Z_-]+' /etc/passwd
root
bin
daemon
adm
lp
sync
shutdown
halt
mail
operator
Ve výše uvedeném grep zavedli jsme další možnost:-o (nebo --only-matching ), aby se zobrazila pouze část řádku odpovídající <PATTERN> . Potom jsme spojili -Eo abyste dosáhli požadovaného výsledku.
Nyní rozebereme výše uvedený příkaz, abychom lépe porozuměli tomu, co se skutečně děje. Zleva doprava:
^zápasy na začátku řady.[a-zA-Z_-]se nazývá třída znaků a odpovídá jedinému znaku odpovídajícímu zahrnutému seznamu.+je kvantifikátor, který se shoduje mezi jednou a neomezeným počtem časů.
Výše uvedený regulární výraz se bude opakovat, dokud nedosáhne znaku, kterému neodpovídá. První řádek souboru je:
root:x:0:0:root:/root:/bin/bash
Zpracovává se následovně:
- První znak je
r, takže odpovídá[a-z]. - Znaménko
+přesune na další znak. - Druhý znak je
oa tomu odpovídá[a-z]. - Znaménko
+přesune na další znak.
Tato sekvence se opakuje, dokud nenarazíme na dvojtečku (: ). Třída znaků [a-zA-Z_-] neodpovídá : symbol, tedy grep přesune na další řádek.
Protože uživatelská jména v passwd soubor jsou všechna malá písmena, mohli bychom také zjednodušit naši třídu znaků následovně, a přesto získat požadovaný výsledek:
$ grep -Eo '^[a-z_-]+' /etc/passwd
Příklad:Najít proces
Při použití ps k hledání procesu často používáme něco jako:
$ ps aux | grep ‘thunderbird’
Ale ps nejen vypíše thunderbird proces. Také uvádí grep příkaz jsme právě spustili také, protože grep běží také za potrubím a je zobrazen v seznamu procesů:
$ ps aux | grep thunderbird
val+ 2196 0.7 2.1 52 33 tty2 Sl+ 16:47 1:55 /usr/lib64/thunderbird/thunderbird
val+ 14064 0.0 0.0 57 82 pts/2 S+ 21:12 0:00 grep --color=auto thunderbird
Můžeme to zvládnout přidáním grep -v grep vyloučit grep z výstupu:
$ ps aux | grep thunderbird | grep -v grep
val+ 2196 0.7 2.1 52 33 tty2 Sl+ 16:47 1:55 /usr/lib64/thunderbird/thunderbird
Při použití grep -v grep udělá to, co jsme chtěli, existují lepší způsoby, jak dosáhnout stejného výsledku bez rozvětvení nového grep proces:
$ ps aux | grep [t]hunderbird
val+ 2196 0.7 2.1 52 33 tty2 Sl+ 16:47 1:55 /usr/lib64/thunderbird/thunderbird
[t]hunderbird zde odpovídá doslovnému t a rozlišují se malá a velká písmena. Neodpovídá grep , a proto nyní vidíme pouze thunderbird ve výstupu.
Tento příklad je pouze ukázkou toho, jak flexibilní grep je, nepomůže vám s odstraňováním problémů se stromem procesů. Existují lepší nástroje vhodné pro tento účel, jako je pgrep .
Shrnutí
Použijte grep když chcete hledat vzor, buď v souboru nebo ve více adresářích rekurzivně. Pokuste se pochopit, jak fungují regulární výrazy, když grep , protože regulární výrazy mohou být mocné.
[Chcete vyzkoušet Red Hat Enterprise Linux? Stáhněte si jej nyní zdarma.]