Pokud si přečtete můj první článek o použití Keepalived pro správu jednoduchého převzetí služeb při selhání v clusterech, pak si vzpomenete, že VRRP používá koncept priority při určování, který server bude aktivním hlavním serverem. Server s nejvyšší prioritou „vyhraje“ a bude se chovat jako hlavní, drží VIP a obsluhuje požadavky. Keepalived poskytuje několik užitečných metod pro úpravu priority na základě stavu vašeho systému. V tomto článku prozkoumáte několik těchto mechanismů spolu s Keepalived schopnost spouštět skripty při změně stavu serveru.
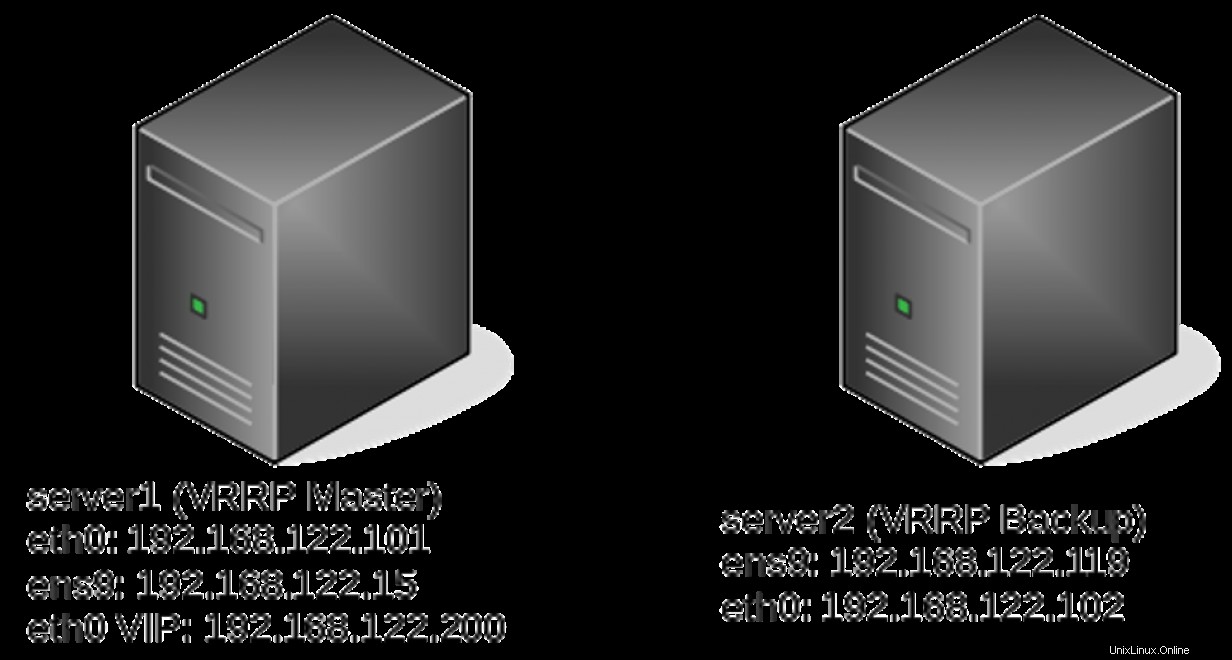
Pro tyto příklady ukážu pouze konfiguraci na serveru1. V tomto okamžiku vám pravděpodobně vyhovuje konfigurace potřebná na serveru2, pokud jste četli celou sérii. Pokud ne, věnujte chvíli kontrole prvního a druhého článku této série, než budete pokračovat.
- Použití Keepalived pro správu jednoduchého převzetí služeb při selhání v clusterech
- Nastavení clusteru Linux s Keepalived:Základní konfigurace
Symboly sítě v diagramech dostupné prostřednictvím VRT Network Equipment Extension, CC BY-SA 3.0.
Keepalived dělá skvělou práci při spouštění převzetí služeb při selhání, když nejsou přijímány reklamy, například když aktivní hlavní server úplně zemře nebo je nedostupný z nějakého jiného důvodu. Často však zjistíte, že je potřeba jemnozrnnějších spouštěcích mechanismů. Vaše aplikace může například spouštět vlastní kontroly stavu, aby zjistila schopnost aplikace obsluhovat požadavky klientů. Nechtěli byste, aby nezdravý aplikační server zůstal aktivním hlavním serverem jen proto, že byl živý a posílal VRRP reklamy.
Poznámka:Zjistil jsem, že verze Keepalived dostupné prostřednictvím standardních repozitářů balíčků obsahovaly chyby, které bránily správnému fungování některých níže uvedených příkladů. Pokud narazíte na problémy, možná budete chtít nainstalovat Keepalived ze zdroje, jak je popsáno v předchozím článku.
Sledování procesů
Jeden z nejběžnějších Keepalived setup zahrnuje sledování procesu na serveru za účelem zjištění stavu hostitele. Můžete například nastavit pár vysoce dostupných webových serverů a spustit převzetí služeb při selhání, pokud na jednom z nich přestane běžet Apache.
Keepalived to usnadňuje pomocí track_process konfigurační směrnice. V příkladu níže jsem nastavil Keepalived pro sledování httpd proces s váhou 10. Tak dlouho jako httpd běží, inzerovaná priorita bude 254 (244 + 10 =254). Pokud httpd přestane běžet, pak priorita klesne na 244 a spustí se převzetí služeb při selhání (za předpokladu, že podobná konfigurace existuje na serveru2).
server1# cat keepalived.conf
vrrp_track_process track_apache {
process httpd
weight 10
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 244
advert_int 1
authentication {
auth_type PASS
auth_pass 12345
}
virtual_ipaddress {
192.168.122.200/24
}
track_process {
track_apache
}
} S touto konfigurací (a Apache nainstalovaný a spuštěný na obou serverech) můžete vyzkoušet scénář převzetí služeb při selhání zastavením Apache a sledováním přesunu VIP ze serveru1 na server2:
server1# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.101/24 192.168.122.200/24 fe80::5054:ff:fe82:d66e/64
server1# systemctl stop httpd
server1# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.101/24 fe80::5054:ff:fe82:d66e/64
server2# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.102/24 192.168.122.200/24 fe80::5054:ff:fe04:2c5d/64 Sledování souborů
Keepalived má také schopnost činit prioritní rozhodnutí na základě obsahu souboru, což může být užitečné, pokud spouštíte aplikaci, která může zapisovat hodnoty do tohoto souboru. Můžete například mít ve své aplikaci proces na pozadí, který pravidelně provádí kontrolu stavu a zapisuje hodnotu do souboru na základě celkového stavu aplikace.
Keepalived manuálová stránka vysvětluje, že sledování souborů je založeno na nakonfigurované váze souboru:
“hodnota bude přečtena jako číslo v textu ze souboru. Pokud je váha nakonfigurovaná pro soubor track_file 0, nenulová hodnota v souboru bude považována za stav selhání a nulová hodnota bude považována za stav OK, jinak bude hodnota vynásobena hmotností nakonfigurovanou v příkaz track_file. Pokud je výsledek menší než -253, přejde jakákoli instance VRRP nebo skupina synchronizace monitorující skript do chybového stavu (váha může být 254, aby bylo možné ze souboru načíst zápornou hodnotu).“
V tomto příkladu budu mít věci jednoduché a pro soubor trasy použiji váhu 1. Tato konfigurace bude mít číselnou hodnotu v souboru /var/run/my_app/vrrp_track_file a vynásobte to 1.
server1# cat keepalived.conf
vrrp_track_file track_app_file {
file /var/run/my_app/vrrp_track_file
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 244
advert_int 1
authentication {
auth_type PASS
auth_pass 12345
}
virtual_ipaddress {
192.168.122.200/24
}
track_file {
track_app_file weight 1
}
}
Nyní můžete vytvořit soubor s počáteční hodnotou a restartovat Keepalived . Prioritu lze vidět v tcpdump výstup, jak je popsáno ve druhém článku této série.
server1# mkdir /var/run/my_app
server1# echo 5 > /var/run/my_app/vrrp_track_file
server1# systemctl restart keepalived
server1# tcpdump proto 112
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
16:19:32.191562 IP server1 > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 249, authtype simple, intvl 1s, length 20 Vidíte, že inzerovaná priorita je 249, což je hodnota v souboru (5) vynásobená váhou (1) a přičtená k základní prioritě (244). Podobně nastavení priority na 6 zvýší prioritu:
server1# echo 6 > /var/run/my_app/vrrp_track_file
server1# tcpdump proto 112
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
16:20:43.214940 IP server1 > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 250, authtype simple, intvl 1s, length 20 Rozhraní sledování
U serverů s více rozhraními může být užitečné upravit prioritu Keepalived instance na základě stavu rozhraní. Například nástroj pro vyrovnávání zatížení s frontendovým VIP a backendovým připojením k interní síti může chtít spustit Keepalived převzetí služeb při selhání, pokud selže připojení k backendové síti. Toho lze dosáhnout pomocí konfigurace track_interface:
server1# cat keepalived.conf
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 244
advert_int 1
authentication {
auth_type PASS
auth_pass 12345
}
virtual_ipaddress {
192.168.122.200/24
}
track_interface {
ens9 weight 5
}
} Výše uvedená konfigurace přiřadí stavu rozhraní ens9 váhu 5. To způsobí, že server1 převezme prioritu 249 (244 + 5 =249), dokud bude ens9 aktivní. Pokud ens9 klesne, priorita klesne na 244 (a spustí převzetí služeb při selhání, za předpokladu, že server2 je nakonfigurován stejným způsobem). Můžete to vyzkoušet na serveru s více rozhraními vypnutím rozhraní a sledováním pohybu VIP mezi hostiteli:
server1# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.101/24 192.168.122.200/24 fe80::5054:ff:fe82:d66e/64
ens9 UP 192.168.122.15/24 fe80::7444:5ec4:8015:722f/64
server1# ip link set ens9 down
server1# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.101/24 fe80::5054:ff:fe82:d66e/64
ens9 DOWN
server2# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
ens9 UP 192.168.122.119/24 fe80::fc9f:8999:b93e:d491/64
eth0 UP 192.168.122.102/24 192.168.122.200/24 fe80::5054:ff:fe04:2c5d/64 Sledovat skript
Viděli jste, že Keepalived nabízí spoustu užitečných vestavěných kontrolních metod pro určení zdraví a následné VRRP priorita hostitele. Někdy však složitější prostředí vyžadují použití vlastních nástrojů, jako jsou skripty kontroly stavu, aby vyhovovaly jejich potřebám. Naštěstí Keepalived má také schopnost spustit libovolný skript k určení zdraví hostitele. Váhu skriptu můžete upravit, ale v tomto příkladu vše zjednoduším:skript, který vrátí 0, bude znamenat úspěch, zatímco skript, který vrátí cokoli jiného, bude znamenat, že Keepalived instance by měla přejít do poruchového stavu.
Skript je jednoduchý ping na oblíbené 8.8.8.8 Server DNS Google, jak je vidět níže. Ve svém prostředí budete pravděpodobně používat složitější skript k provádění všech potřebných kontrol stavu.
server1# cat /usr/local/bin/keepalived_check.sh
#!/bin/bash
/usr/bin/ping -c 1 -W 1 8.8.8.8 > /dev/null 2>&1
Všimněte si, že jsem pro ping použil časový limit 1 sekundy (-W 1). Při psaní Keepalived zkontrolujte skripty, je dobré je udržovat lehké a rychlé. Nechcete, aby rozbitý server zůstal nadřízeným po dlouhou dobu, protože váš skript je pomalý.
Keepalived konfigurace pro kontrolní skript je uvedena níže:
server1# cat keepalived.conf
vrrp_script keepalived_check {
script "/usr/local/bin/keepalived_check.sh"
interval 1
timeout 5
rise 3
fall 3
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 244
advert_int 1
authentication {
auth_type PASS
auth_pass 12345
}
virtual_ipaddress {
192.168.122.200/24
}
track_script {
keepalived_check
}
}
Toto vypadá hodně jako konfigurace, se kterou jste pracovali, ale vrrp_script blok má několik jedinečných direktiv:
interval:Jak často by se měl skript spouštět (1 sekunda).timeout:Jak dlouho čekat na návrat skriptu (5 sekund).rise:Kolikrát se musí skript úspěšně vrátit, aby byl hostitel považován za „zdravého“. V tomto příkladu se musí skript úspěšně vrátit třikrát. To pomáhá předcházet „přepadávání“, kdy jediné selhání (nebo úspěch) způsobíKeepalivedstavu pro rychlé překlopení tam a zpět.fall:Kolikrát se musí skript neúspěšně vrátit (nebo vypršel časový limit), aby byl hostitel považován za „nezdravého“. Toto funguje jako opak směrnice o vzestupu.
Tuto konfiguraci můžete otestovat vynucením selhání skriptu. V níže uvedeném příkladu jsem přidal iptables pravidlo, které brání komunikaci s 8.8.8.8 . To způsobilo selhání kontroly stavu a po několika sekundách zmizel VIP. Poté mohu pravidlo odstranit a sledovat, jak se VIP znovu objeví.
server1# iptables -I OUTPUT -d 8.8.8.8 -j DROP
server1# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.101/24 fe80::5054:ff:fe82:d66e/64
server1# iptables -D OUTPUT -d 8.8.8.8 -j DROP
server1# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.101/24 192.168.122.200/24 fe80::5054:ff:fe82:d66e/64
Rychlý tip o skriptech v Keepalived :Mohou být spuštěny jako jiný uživatel než root. I když jsem to v těchto příkladech neukázal, podívejte se na manuálovou stránku a ujistěte se, že používáte nejméně privilegovaného uživatele, abyste se vyhnuli jakýmkoli negativním bezpečnostním dopadům z vašeho kontrolního skriptu.
Upozorňovat skripty
Probíral jsem způsoby, jak spustit Keepalived reakce na základě vnějších podmínek. Pravděpodobně však také budete chtít spouštět akce při Keepalived přechody z jednoho stavu do druhého. Můžete například chtít zastavit službu při Keepalived přejde do stavu zálohování, nebo možná budete chtít odeslat e-mail správci. Keepalived vám to umožňuje pomocí oznamovacích skriptů.
Keepalived poskytuje několik notifikačních direktiv pouze pro volání skriptů v určitých stavech (notify_master , notify_backup , atd.), ale zaměřím se na samotné notify směrnice, protože je nejflexibilnější. Když skript v notify je zavolána direktiva, obdrží čtyři další argumenty (po všech argumentech, které jsou předány samotnému skriptu).
Jsou uvedeny v pořadí:
- Skupina nebo instance:Označení, zda je oznámení spuštěno
VRRPskupina (v této sérii není diskutována) nebo konkrétníVRRPinstance. - Název skupiny nebo instance
- Uveďte, že skupina nebo instance přechází do
- Priorita
Když se podíváme na příklad, je to jasnější. Skript a Keepalived konfigurace vypadá takto:
server1# cat /usr/local/bin/keepalived_notify.sh
#!/bin/bash
echo "$1 $2 has transitioned to the $3 state with a priority of $4" > /var/run/keepalived_status
server1# cat keepalived.conf
vrrp_script keepalived_check {
script "/usr/local/bin/keepalived_check.sh"
interval 1
timeout 5
rise 3
fall 3
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 244
advert_int 1
authentication {
auth_type PASS
auth_pass 12345
}
virtual_ipaddress {
192.168.122.200/24
}
track_script {
keepalived_check
}
notify "/usr/local/bin/keepalived_notify.sh"
}
Výše uvedená konfigurace bude volat /usr/local/bin/keepalived_notify.sh skript pokaždé, když je Keepalived dojde k přechodu stavu. Protože je na místě stejný kontrolní skript, můžete snadno zkontrolovat počáteční stav a poté spustit přechod:
server1# cat /var/run/keepalived_status
INSTANCE VI_1 has transitioned to the MASTER state with a priority of 244
server1# iptables -A OUTPUT -d 8.8.8.8 -j DROP
server1# cat /var/run/keepalived_status
INSTANCE VI_1 has transitioned to the FAULT state with a priority of 244
server1# iptables -D OUTPUT -d 8.8.8.8 -j DROP
server1# cat /var/run/keepalived_status
INSTANCE VI_1 has transitioned to the MASTER state with a priority of 244
Můžete vidět, že argumenty příkazového řádku odpovídají těm, které jsem popsal na začátku této části. Toto je samozřejmě jednoduchý příklad, ale notifikační skripty mohou provádět spoustu složitých akcí, jako je úprava pravidel směrování nebo spouštění jiných skriptů. Představují užitečný způsob, jak provádět externí akce na základě Keepalived změny stavu.
Koneckonců
Tento článek uzavřel základní Keepalived série s některými pokročilými koncepty. Naučili jste se spouštět Keepalived změny priorit a stavu na základě externích událostí, jako je stav procesu, změny rozhraní a dokonce i výsledky externích skriptů. Také jste se naučili, jak spouštět oznamovací skripty v reakci na Keepalived změny stavu. Můžete zkombinovat dva nebo více těchto přístupů a vytvořit vysoce dostupnou dvojici linuxových serverů, které reagují na různé vnější podněty a zajistí, že provoz vždy dosáhne zdravé IP adresy, která může obsluhovat požadavky klientů.
[ Chcete se dozvědět více o správě systému? Absolvujte bezplatný online kurz:Technický přehled Red Hat Enterprise Linux. ]