Jakmile vstoupíte do domény operačního systému Linux, bude se vám seznam výpočetních možností prostřednictvím prostředí příkazového řádku Linuxu zdát nekonečný. Je to jednoduše proto, že čím více Linux používáte, tím více se chcete učit a tato touha vás provede nesčetnými příležitostmi k učení.
V tomto tutoriálu se podíváme na počítání a tisk duplicitních řádků v textovém souboru v prostředí operačního systému Linux. Tento výukový modul je součástí správy souborů Linux.
Prostředí příkazového řádku nebo terminálu Linuxu není nové ve zpracování vstupních textových souborů. Je tak zběhlý v takových operacích, že se při zpracování textových souborů ještě nesetká s důstojnou výzvou.
Tento tutoriál vnese trochu světla do identifikace/zpracování duplicitních řádků v náhodných textových souborech v Linuxu.
Prohlášení o problému
Aby byl tento tutoriál jednodušší a zajímavější, vytvoříme vzorový textový soubor, který bude fungovat jako náhodný soubor, u kterého chceme zkontrolovat existenci duplicitních řádků.
$ sudo nano sample_file.txt
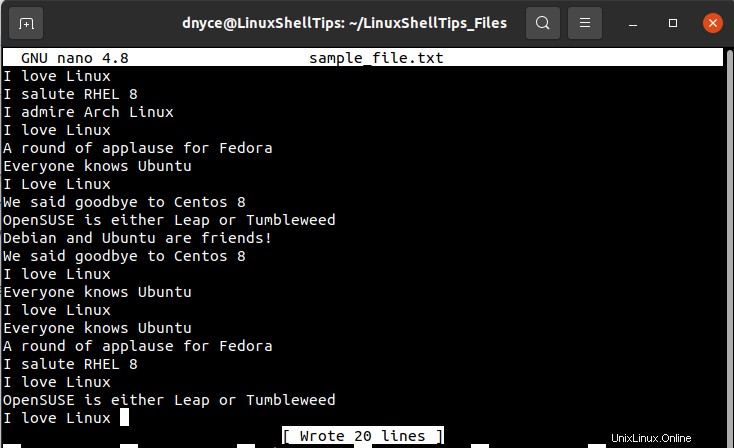
Pouhým prohledáním snímku obrazovky výše uvedeného textového souboru bychom měli být schopni zaznamenat existenci některých duplicitních řádků, ale nemůžeme si být jisti jejich přesným počtem výskytů.
Abychom si byli jisti počtem duplicitních řádků, najdeme naše řešení z následujících přístupů založených na příkazovém řádku/terminálu Linuxu:
Najděte duplicitní řádky v souboru pomocí příkazů sort a uniq
Pohodlí používání uniq příkaz je, že přichází s -c možnost příkazu. Tato možnost příkazu je však platná pouze v případě, že textový soubor, na který cílíte/skenujete, má duplicitní sousední řádky.
Chcete-li se vyhnout této nepříjemnosti při používání uniq příkaz k tisku duplicitních řádků si musíme vypůjčit metodu příkazu řazení seskupování opakovaných/duplikovaných řádků v rámci cíleného textového souboru.
Zkrátka nejprve předáme cílený textový soubor přes třídění příkazu a poté jej pomocí kanálu uniq příkaz, který bude doprovázen -c možnost příkazu, jak je ukázáno níže:
$ sort sample_file.txt | uniq -c
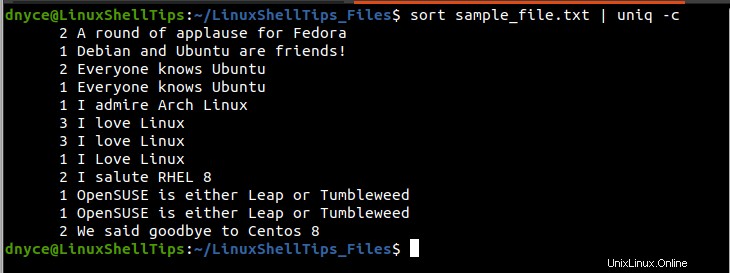
První sloupec (vlevo) výše uvedeného výstupu udává, kolikrát se vytištěné řádky v pravém sloupci objeví v souboru sample_file.txt textový soubor. Například řádek „Miluji Linux“ je duplikován/opakován (3+3+1) krát v rámci textového souboru celkem 7 krát.
Tisk duplicitních řádků v souboru pomocí příkazu Awk
The awk příkaz k vyřešení tohoto „tisku duplicitních řádků v textovém souboru “Problém je jednoduchý jednovrstvý. Abychom pochopili, jak to funguje, musíme to nejprve implementovat, jak je ukázáno níže:
$ awk '{ a[$0]++ } END{ for(x in a) print a[x], x }' sample_file.txt
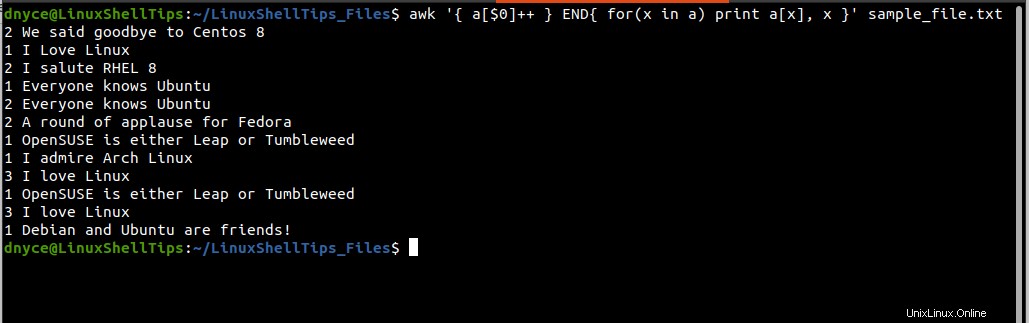
Po provedení výše uvedeného příkazu se zobrazí dva sloupce, první sloupec počítá, kolikrát se v textovém souboru objeví opakovaný/duplikovaný řádek, a druhý sloupec ukazuje na příslušný řádek.
Výstup výše uvedeného příkazu však není tak organizovaný jako ten pod sort a unikátní příkazy.
Úspěšně jsme probrali, jak tisknout duplicitní řádky v textovém souboru v prostředí operačního systému Linux.