Textové soubory obsahují nepřetržitý proud znaků v žádném předem definovaném formátu. Zatímco některé formáty souborů byly vyvinuty nad textovými soubory (např. JSON , YAML ), které očekávají, že textová data budou přítomna v určitém formátu, normálním '.txt' soubory žádné takové konvence nemají. Načítání konkrétního řádku, fráze nebo řetězce z textového souboru je tedy třeba provádět pomocí obecných nástrojů Linuxu.
příkaz grep v Linuxu se používá k nalezení podřetězce nebo textového vzoru v řetězci nebo souboru. Vypíše řádek, kde se nachází podřetězec.
Syntaxe pro použití příkazu grep je následující:
$ grep <substring> <filename/standard input>
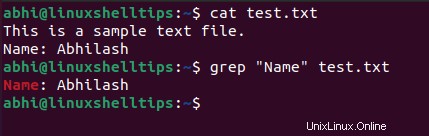
Chcete-li například vyhledat podřetězec „Název ” v souboru ‘test.txt ‘ (jehož obsah je zobrazen na snímku obrazovky), spusťte následující.
$ grep "Name" test.txt
Dnes se podíváme, jak extrahovat E-mail adresy mimo textové soubory pomocí příkazu grep .
Jak víme, e-mailová adresa je přítomna ve formátu:
<user_id>@<domain>.<subdomain>
Zde user_id je jedinečný identifikační řetězec zvolený uživatelem a doména a subdoména představují poskytovatele e-mailových služeb (např. gmail.com ).
Názvy domén a subdomén mohou obsahovat pouze abecedy, zatímco user_id může obsahovat abecedy, číselné znaky i další běžné znaky, jako je tečka (.) a podtržítko (_) .
Protože se jedná o určitý vzor, který se má prohledávat, můžeme použít '-e' příznak grep, který nám umožňuje specifikovat vzory regulárních výrazů namísto podřetězců pro extrakci ze souboru.
Tedy syntaxe grep s '-e' je:
$ grep -e <regular_expression> <filename/standard input>
Na základě výše uvedeného vzoru e-mailové adresy můžeme vytvořit následující regulární výraz:
[a-zA-Z0-9._]\+@[a-zA-Z]\+.[a-zA-Z]\+
Zde 'a-zA-Z' představuje libovolnou abecedu, '0-9' představuje číslice, '._' představují tečku nebo podtržítko. Všimněte si, že znaky '\+' představují, že znaková sada v závorkách by se měla objevit jednou nebo vícekrát.
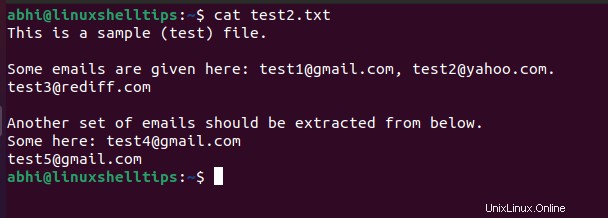
Spustíme tento regulární výraz, abychom extrahovali e-mailové adresy ze souboru ‘test2.txt ‘.
Nejprve si prohlédněte obsah souboru test2.txt jsou:
$ cat test2.txt
Dále spusťte následující příkaz a extrahujte e-mailové adresy ze souboru.
$ grep -e "[a-zA-Z0-9._]\+@[a-zA-Z]\+.[a-zA-Z]\+" test2.txt

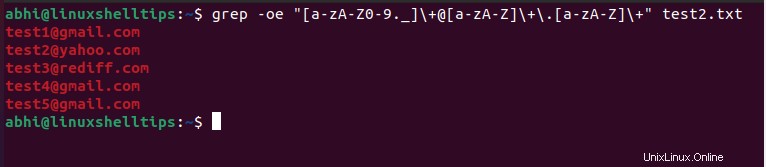
Jak vidíme, e-mailové adresy byly úspěšně identifikovány Grepem. Jsou však zobrazeny spolu s celým řádkem v souboru.
Chcete-li zobrazit pouze nalezená e-mailová ID, použijte '-o' příznak spolu s '-e' jak je uvedeno.
$ grep -oe "[a-zA-Z0-9._]\+@[a-zA-Z]\+.[a-zA-Z]\+" test2.txt
Závěr
V tomto článku jsme viděli, jak extrahovat e-mailové adresy z textového souboru v Linuxu pomocí praktického nástroje příkazového řádku Grep . Tyto e-mailové adresy pak lze také zapsat do souboru pomocí přesměrování.
Pokud máte nějaké dotazy nebo zpětnou vazbu, dejte nám vědět v komentářích níže.