Než se pustíme do hloubkové prohlídky tohoto průvodce článkem, musíme nejprve pochopit, co se článek snaží odhalit. Musíme pochopit nebo odpovědět na otázku „proč je důležité počítat soubory v Linuxu '. Je ambicí každého administrátora Linuxu, aby byl obeznámen s prvky architektury svého operačního systému.
Proto je stejně důležité znát umístění a počet adresářových souborů, které musíte spravovat/spravovat. V tomto případě můžete mít tisíce ručně nebo automaticky generovaných souborů systémovými uživateli nebo programy a chcete mít přehled o jejich rostoucím nebo konečném počtu.
Existuje několik vestavěných příkazů založených na Linuxu, které vám za takových okolností mohou snadno pomoci. Pokud však hledáme nejrychlejší způsob, jak dosáhnout cíle tohoto článku, musíme být vybíraví a ohleduplní k dalším schůdným možnostem.
Rychlý způsob rekurzivního počítání souborů v Linuxu
Jen málo linuxových příkazů vyniká z hlediska rekurzivního a rychlého počítání souborů. Porovnejme dva nejoblíbenější.
Linuxový příkaz Najít versus příkaz najít
Pro demonstrační účely se zaměříme na počet souborů v /home/user adresář operačního systému Linux.
Abychom získali rozdíl v rychlosti mezi příkazem find a příkazem locate, spojíme jejich provedení s časem vestavěným v Linuxu příkaz, abychom mohli zjistit, který přístup rekurzivního počítání souborů je rychlejší.
Od příkazu najít je již ve vašem systému Linux předinstalovaný, potřebujeme pouze nainstalovat locate než zahájíme porovnání rychlosti jejich provádění.
$ sudo apt-get install mlocate [On Debian, Ubuntu and Mint] $ sudo yum install mlocate [On RHEL/CentOS/Fedora and Rocky Linux/AlmaLinux] $ sudo emerge -a sys-apps/mlocate [On Gentoo Linux] $ sudo pacman -S mlocate [On Arch Linux] $ sudo zypper install mlocate [On OpenSUSE]
V odkazu na tento článek průvodce, hlavní místo příkaz [OPTION] nás zajímá -c , -count protože jsme po standardním výstupu, který odráží počet dotazovaných souborů.
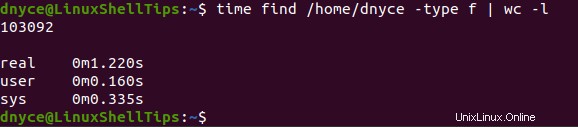
Nejprve použijeme příkaz najít spočítat počet souborů v /home/user adresář. Váš příkaz by měl vypadat podobně jako následující:
$ time find /home/dnyce -type f | wc -l
Za druhé, podívejme se, co vede k lokaci příkaz poskytne počítání souborů ve stejném /home/user adresář. Jeho implementace příkazu je následující:
$ time locate -c /home/dnyce
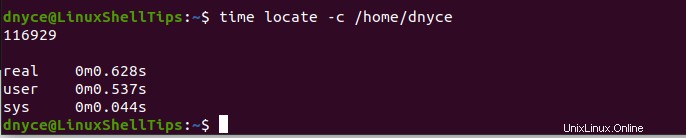
S časem příkaz sledující dobu provádění těchto dvou příkazů (najít a najít ), můžeme si všimnout, že lokat příkaz rekurzivně kopal hlouběji, aby produkoval více souborů za kratší dobu.
Chcete-li použít Linux najděte příkazu, musíte dodržovat následující pravidlo syntaxe:
$ locate [OPTION]… [PATTERN]…
Zaškrtnutím umístění příkazová manuálová stránka ($ man locate) , také si uvědomíte, že tento příkaz lze také použít pro další životaschopné funkce související se soubory.
Také, i když přineseme další oblíbený příkaz (příkaz ls) pro počítání souborů v cílovém adresáři, nebude to rekurzivně hlubší a rychlejší na úroveň locate příkaz.
$ time ls /home/dnyce | wc -l
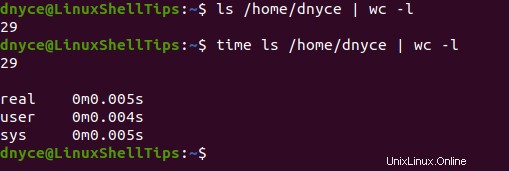
místo příkaz je rychlejší než najít příkaz, protože jeho algoritmus počítání souborů je orientován na databázi a ne na souborový systém jako jeho protějšek.
Výchozí funkční chování lokace příkaz je ignorovat existenci dotazovaného souboru(ů) mimo dosah jeho databáze. Po poslední úspěšné aktualizaci databáze existujících souborů také locate příkaz okamžitě nehlásí vytvoření nových souborů.