Primárním úkolem webového robota je procházet nebo skenovat webové stránky a stránky pro získání informací; neúnavně pracují na sběru dat pro vyhledávače a další aplikace. Pro některé existuje dobrý důvod, proč držet stránky dál od vyhledávačů. Ať už chcete vyladit přístup ke svému webu nebo chcete pracovat na vývojářském webu, aniž byste se zobrazovali ve výsledcích Google, jakmile bude soubor robots.txt implementován, umožní webovým prohledávačům a robotům vědět, jaké informace mohou shromažďovat.
Co je soubor Robots.txt?
Robots.txt je prostý textový soubor webové stránky v kořenovém adresáři vašeho webu, který se řídí standardem pro vyloučení robotů. Například www.yourdomain.com bude mít soubor robots.txt na adrese www.yourdomain.com/robots.txt. Soubor se skládá z jednoho nebo více pravidel, která povolují nebo blokují přístup prohledávačům a omezují je na zadanou cestu k souboru na webu. Ve výchozím nastavení je procházení všech souborů zcela povoleno, pokud není uvedeno jinak.
Soubor robots.txt je jedním z prvních aspektů analyzovaných prohledávači. Je důležité si uvědomit, že váš web může mít pouze jeden soubor robots.txt. Soubor se implementuje na jednu nebo několik stránek nebo celý web, aby odradil vyhledávače od zobrazování podrobností o vašem webu.
Tento článek obsahuje pět kroků k vytvoření souboru robots.txt a syntaxi potřebnou k udržení robotů na uzdě.
Jak nastavit soubor Robots.txt
1. Vytvořte soubor Robots.txt
Musíte mít přístup ke kořenovému adresáři vaší domény. Váš poskytovatel webhostingu vám může pomoci, zda máte nebo nemáte odpovídající přístup.
Nejdůležitější částí souboru je jeho vytvoření a umístění. Pomocí libovolného textového editoru vytvořte soubor robots.txt a najdete jej na adrese:
- Kořenový adresář vaší domény:www.yourdomain.com/robots.txt.
- Vaše subdomény:page.yourdomain.com/robots.txt.
- Nestandardní porty:www.yourdomain.com:881/robots.txt.
Nakonec se budete muset ujistit, že váš soubor robots.txt je textový soubor s kódováním UTF-8. Google a další oblíbené vyhledávače a prohledávače mohou ignorovat znaky mimo rozsah UTF-8, což může způsobit, že vaše pravidla v souboru robots.txt budou neplatná.
2. Nastavte svůj robots.txt User-agent
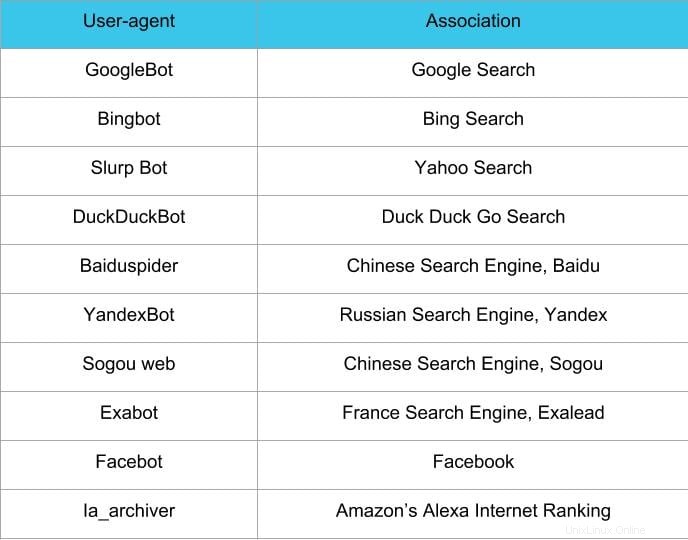
Dalším krokem při vytváření souborů robots.txt je nastavení user-agent . user-agent se týká webových prohledávačů nebo vyhledávačů, které chcete povolit nebo blokovat. uživatelským agentem může být několik entit . Níže uvádíme několik prohledávačů a také jejich přidružení.
Existují tři různé způsoby, jak vytvořit user-agent ve vašem souboru robots.txt.
Vytvoření jednoho uživatelského agenta
Syntaxe, kterou používáte k nastavení uživatelského agenta, je User-agent:NameOfBot . Níže je DuckDuckBot jediným uživatelským agentem založeno.
# Example of how to set user-agent
User-agent: DuckDuckBotVytvoření více než jednoho uživatelského agenta
Pokud musíme přidat více než jeden, postupujte stejným způsobem jako u DuckDuckBot user-agent na následujícím řádku zadáním názvu dalšího user-agenta . V tomto příkladu jsme použili Facebot.
#Example of how to set more than one user-agent
User-agent: DuckDuckBot
User-agent: FacebotNastavení všech prohledávačů jako uživatelského agenta
Chcete-li zablokovat všechny roboty nebo prohledávače, nahraďte jméno robota hvězdičkou (*).
#Example of how to set all crawlers as user-agent
User-agent: *3. Nastavte pravidla na soubor Robots.txt
Soubor robots.txt se čte ve skupinách. Skupina určí, kdo je user-agent je a má jedno pravidlo nebo direktivu pro označení souborů nebo adresářů user-agent může nebo nemůže přistupovat.
Zde jsou použité direktivy:
- Zakázat :Direktiva odkazující na stránku nebo adresář související s vaší kořenovou doménou, kterou nechcete mít pojmenovanou user-agent plazit se. Bude začínat lomítkem (/) následovaným celou adresou URL stránky. Ukončíte jej lomítkem pouze v případě, že odkazuje na adresář a ne na celou stránku. Můžete použít jeden nebo více disallow nastavení podle pravidla.
- Povolit :Direktiva odkazuje na stránku nebo adresář související s vaší kořenovou doménou, kterou chcete pojmenovat user-agent plazit se. Například byste použili allow direktiva k přepsání disallow pravidlo. Bude také začínat lomítkem (/) následovaným celou adresou URL stránky. Ukončíte jej lomítkem pouze v případě, že odkazuje na adresář a ne na celou stránku. Můžete použít jedno nebo více povolit nastavení podle pravidla.
- Soubor Sitemap :Direktiva sitemap je volitelná a udává umístění mapy webu pro web. Jedinou podmínkou je, že se musí jednat o plně kvalifikovanou adresu URL. Můžete použít nulu nebo více, podle toho, co je potřeba.
Webové prohledávače zpracovávají skupiny shora dolů. Jak již bylo zmíněno, přistupují na jakoukoli stránku nebo adresář, které nejsou explicitně nastaveny na disallow . Proto přidejte Disallow:/ pod user-agent informace v každé skupině, abyste těmto konkrétním uživatelským agentům zablokovali procházení vašeho webu.
# Example of how to block DuckDuckBot
User-agent: DuckDuckBot
Disallow: /
#Example of how to block more than one user-agent
User-agent: DuckDuckBot
User-agent: Facebot
Disallow: /
#Example of how to block all crawlers
User-agent: *
Disallow: /Chcete-li zablokovat konkrétní subdoménu před všemi prohledávači, přidejte do svého pravidla zákazu lomítko a úplnou adresu URL subdomény.
# Example
User-agent: *
Disallow: /https://page.yourdomain.com/robots.txtChcete-li zablokovat adresář, postupujte stejným způsobem přidáním lomítka a názvu vašeho adresáře, ale pak skončete dalším lomítkem.
# Example
User-agent: *
Disallow: /images/A konečně, pokud chcete, aby všechny vyhledávače shromažďovaly informace na všech stránkách vašeho webu, můžete vytvořit buď povolit nebo zakázat pravidlo, ale nezapomeňte přidat lomítko při použití allow pravidlo. Příklady obou pravidel jsou uvedeny níže.
# Allow example to allow all crawlers
User-agent: *
Allow: /
# Disallow example to allow all crawlers
User-agent: *
Disallow:4. Nahrajte svůj soubor Robots.txt
Webové stránky nepřicházejí automaticky se souborem robots.txt, protože to není vyžadováno. Jakmile se rozhodnete jej vytvořit, nahrajte soubor do kořenového adresáře vašeho webu. Nahrávání závisí na struktuře souborů vašeho webu a prostředí vašeho webhostingu. Požádejte svého poskytovatele hostingu o pomoc s nahráním souboru robots.txt.
5. Ověřte, zda váš soubor Robots.txt správně funguje
Existuje několik způsobů, jak otestovat a ujistit se, že váš soubor robots.txt funguje správně. U kteréhokoli z nich můžete vidět chyby v syntaxi nebo logice. Zde je několik z nich:
- Nástroj na testování souborů robots.txt společnosti Google ve službě Search Console.
- Validátor a testovací nástroj robots.txt od společnosti Merkle, Inc.
- Testovací nástroj robots.txt společnosti Ryte.
Bonus:Použití Robots.txt ve WordPress
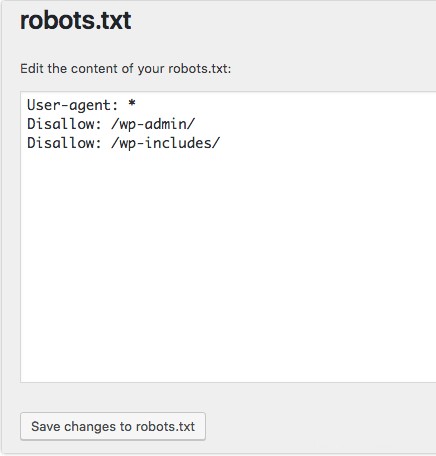
Pokud používáte WordPress plugin Yoast SEO, v okně administrátora se zobrazí sekce pro vytvoření souboru robots.txt.
Přihlaste se do backendu svého webu WordPress a získejte přístup k Nástrojům pod SEO a poté klikněte na Editor souborů .
Při vytváření uživatelských agentů a pravidel postupujte ve stejném pořadí jako dříve. Níže jsme zablokovali webové prohledávače z adresářů wp-admin a wp-includes WordPress, přičemž uživatelům a robotům stále umožňujeme vidět další stránky webu. Po dokončení klikněte na Uložit změny do souboru robots.txt pro aktivaci souboru robots.txt.