Pro správce systému je velmi běžné provádět přesměrování vstupu nebo výstupu při své každodenní práci.
Přesměrování vstupu a výstupu je velmi výkonný nástroj, který vám umožní propojit více příkazů dohromady a také syntetizovat výstup více příkazů.
Přesměrování vstupu/výstupu je základním konceptem systémů založených na Unixu – a lze jej použít jako způsob, jak zvýšit produktivitu programátorů ohromně.
Přesměrování vstupu a výstupu je však obsáhlé téma a existuje několik základů, kterým musíte porozumět, pokud chcete být produktivní.
S tímto tutoriálem pochopíte vše že je třeba vědět o přesměrování vstupu a výstupu na systémech Linux.
Zamyslíme se nad designem linuxového jádra na souborech a také na tom, jak procesy fungují, abyste měli hluboké a úplné pochopení toho, co je přesměrování vstupu a výstupu.
Během cesty budou poskytnuty některé příklady, aby se zajistilo, že teoretické znalosti budou propojeny s praktickými cvičeními.
Jste připraveni?
Co se naučíte
Pokud dodržíte tento návod až do konce, dozvíte se o následujících konceptech.
- Jaké deskriptory souborů jsou a jak souvisí se standardními vstupy a výstupy;
- Jak zkontrolovatstandardní vstupy a výstupy pro daný proces v Linuxu;
- Jak přesměrovat standardní vstup a výstup v systému Linux;
- Jak používat kanály řetězit vstupy a výstupy pro dlouhé příkazy;
To je docela dlouhý program, bez dalších okolků se pojďme podívat na to, co jsou deskriptory souborů a jak jsou soubory konceptualizovány jádrem Linuxu.
1 – Co jsou procesy Linuxu?
Než pochopíte vstup a výstup v systému Linux, je velmi důležité mít nějaké základy o tom, co jsou procesy Linuxu a jak interagují s vaším hardwarem.
Pokud vás zajímají pouze příkazové řádky pro přesměrování vstupu a výstupu, můžete přejít na další sekce. Tato část je určena pro systémové administrátory, kteří chtějí jít hlouběji do tématu.
a – Jak se vytvářejí procesy Linux?
Pravděpodobně jste to již slyšeli, protože je to docela populární rčení, ale v Linuxu všechno je soubor .
To znamená, že procesy, zařízení, klávesnice, pevné disky jsou reprezentovány jako soubory žijící v souborovém systému.
Linuxové jádro může tyto soubory odlišit tím, že jim přiřadí typ souboru (například soubor, adresář, měkký odkaz nebo soket), ale jádro je ukládá ve stejné datové struktuře.
Jak již pravděpodobně víte, procesy Linuxu jsou vytvářeny jako rozvětvení existujících procesů, což může být proces init nebo proces systemd na novějších distribucích.
Při vytváření nového procesu jádro Linuxu rozvětví nadřazený proces a zduplikuje strukturu, která je následující.
b – Jak se ukládají soubory v systému Linux?
Věřím, že diagram řekne sto slov, takže zde je návod, jak jsou soubory koncepčně uloženy v systému Linux.

Jak můžete vidět, pro každý vytvořený proces je vytvořena nová task_struct je vytvořen na vašem hostiteli Linuxu.
Tato struktura obsahuje dvě reference, jednu pro metadata souborového systému (nazývanou fs ), kde můžete najít informace, jako je například maska souborového systému.
Druhým je struktura pro soubory obsahující to, co nazýváme deskriptory souborů .
Obsahuje také metadata o souborech používaných procesem, ale my se v této kapitole zaměříme na deskriptory souborů.
V informatice jsou deskriptory souborů odkazy na jiné soubory, které v současnosti používá samotné jádro.
Ale co tyto soubory vůbec představují?
c – Jak se v Linuxu používají deskriptory souborů?
Jak už asi víte, jádro funguje jako an rozhraní mezi vašimi hardwarovými zařízeními (obrazovka, myš, CD-ROM nebo klávesnice).
Znamená to, že vaše jádro je schopno pochopit, že chcete přenést nějaké soubory mezi disky, nebo že budete chtít například vytvořit nové video na sekundární jednotce.
V důsledku toho linuxové jádro neustále přesouvá data ze vstupních zařízení (například klávesnice) na výstupní zařízení (například pevný disk).
Pomocí této abstrakce jsou procesy v podstatě způsobem, jak manipulovat se vstupy (jako přečteno operace) k vykreslení různých výstupů (jako zápis operace)
Jak ale procesy vědět, kam mají být data odeslána?
Procesy vědí, kam mají být data odeslána pomocí deskriptorů souborů.
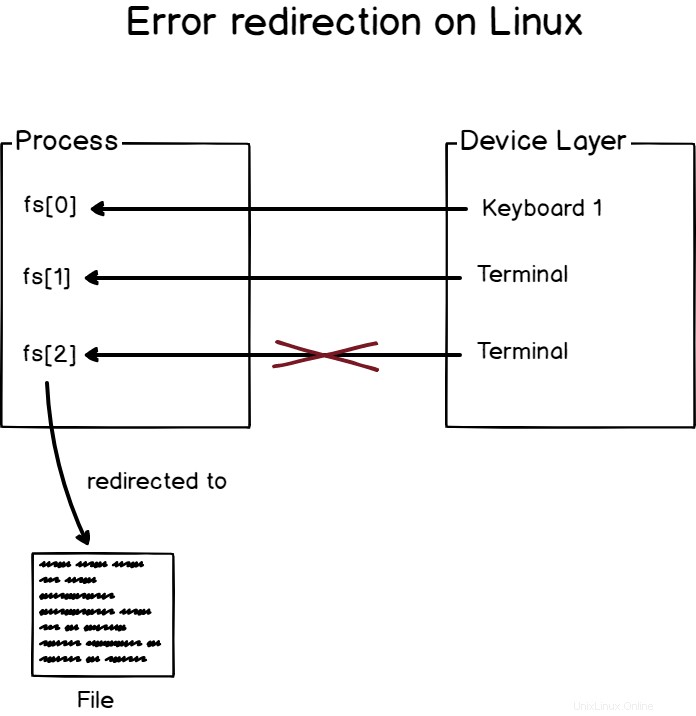
V systému Linux deskriptor souboru 0 (nebo fd[0]) je přiřazeno kstandardnímu vstupu.
Podobnědeskriptor souboru 1 (nebo fd[1]) je přiřazen ke standardnímu výstupu a deskriptor souboru 2 (nebo fd[2]) je přiřazena standardní chybě.
V systému Linux je to konstanta, pro každý proces jsou první tři deskriptory souborů vyhrazeny pro standardní vstupy, výstupy a chyby.
Tyto deskriptory souborů jsou mapovány na zařízení ve vašem systému Linux.
Zařízení registrovaná při vytváření instance jádra, lze je vidět v /dev adresář vašeho hostitele.
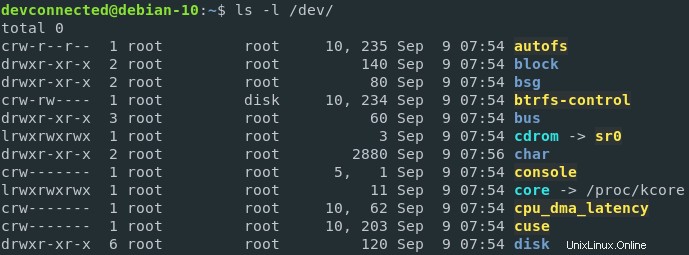
Pokud byste se podívali na deskriptory souborů daného procesu, řekněme například proces bash, uvidíte, že deskriptory souborů jsou v podstatě měkké odkazy na skutečná hardwarová zařízení na vašem hostiteli.
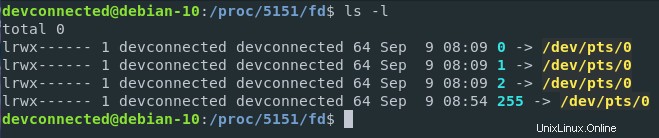
Jak můžete vidět, když izoluji deskriptory souborů mého bash procesu (který má 5151 PID na mém hostiteli), mohu vidět zařízení interagující s mým procesem (nebo soubory otevřené jádrem pro můj proces).
V tomto případě /dev/pts/0 představuje terminál, který je virtuálním zařízením (nebo tty) na mém virtuálním souborovém systému. Jednodušeji řečeno to znamená, že moje instance bash (běžící v terminálovém rozhraní Gnome) čeká na vstupy z mé klávesnice, vytiskne je na obrazovku a na požádání je provede.
Nyní, když lépe rozumíte deskriptorům souborů a tomu, jak je procesy používají, jsme připraveni popsat, jak provést přesměrování vstupu a výstupu v systému Linux .
2 – Co je přesměrování výstupu v systému Linux?
Přesměrování vstupu a výstupu je technika používaná za účelem přesměrování/změny standardní vstupy a výstupy, které v podstatě mění, odkud se data čtou nebo kam se data zapisují.
Pokud například provedu příkaz na svém Linuxovém shellu, výstup se může vytisknout přímo na můj terminál (například příkaz cat).
S přesměrováním výstupu jsem se však mohl rozhodnout uložit výstup mého příkazu cat do souboru pro dlouhodobé uložení.
a – Jak funguje přesměrování výstupu?
Přesměrování výstupu je akt přesměrování výstupu procesu na zvolené místo, jako jsou soubory, databáze, terminály nebo jakákoli zařízení (nebo virtuální zařízení), do kterých lze zapisovat.
Jako příklad se podívejme na příkaz echo.
Ve výchozím nastavení funkce echo vezme parametr řetězce a vytiskne jej na výchozí výstupní zařízení.
V důsledku toho, pokud spustíte funkci echo je terminál, výstup se vytiskne v samotném terminálu.

Nyní řekněme, že chci, aby byl řetězec místo toho vytištěn do souboru pro dlouhodobé uložení.
Chcete-li přesměrovat standardní výstup v systému Linux, musíte použít operátor „>“.
Chcete-li například přesměrovat standardní výstup funkce echo do souboru, měli byste spustit
$ echo devconnected > filePokud soubor neexistuje, bude vytvořen.
Dále se můžete podívat na obsah souboru a zjistit, že do něj byl správně vytištěn řetězec „devconnected“.

Alternativně je možné přesměrovat výstup pomocí „1> ” syntaxe.
$ echo test 1> file
b – Přesměrování výstupu na soubory nedestruktivním způsobem
Při přesměrování standardního výstupu do souboru jste si pravděpodobně všimli, že vymaže stávající obsah souboru.
Někdy to může být docela problematické, protože byste chtěli zachovat stávající obsah souboru a jen přidat nějaké změny na konec souboru.
Chcete-li připojit obsah k souboru pomocí přesměrování výstupu, použijte operátor „>>“ spíše než operátor „>“.
Vzhledem k příkladu, který jsme právě použili dříve, přidejte do našeho stávajícího souboru druhý řádek.
$ echo a second line >> file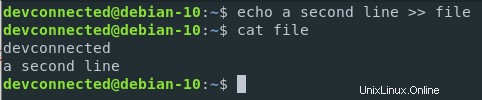
Skvělé!
Jak můžete vidět, obsah byl k souboru připojen, nikoli zcela přepsán.
c – Přesměrování výstupu má problémy
Když se zabýváte přesměrováním výstupu, můžete být v pokušení provést příkaz do souboru pouze za účelem přesměrování výstupu do stejného souboru.
Přesměrování na stejný soubor
echo 'This a cool butterfly' > file
sed 's/butterfly/parrot/g' file > fileCo očekáváte v testovacím souboru?
Výsledkem je, že soubor je zcela prázdný.

Proč?
Ve výchozím nastavení jádro při analýze vašeho příkazu nebude provádět příkazy postupně.
To znamená, že nebude čekat na konec příkazu sed, aby otevřel váš nový soubor a zapsal do něj obsah.
Namísto toho jádro otevře váš soubor, vymaže veškerý obsah v něm a počká na zpracování výsledku vaší operace sed.
Když operace sed vidí prázdný soubor (protože veškerý obsah byl operací přesměrování výstupu vymazán), obsah je prázdný.
V důsledku toho není k souboru nic připojeno a obsah je zcela prázdný.
Chcete-li přesměrovat výstup do stejného souboru, můžete použít roury nebo pokročilejší příkazy jako
command … input_file > temp_file && mv temp_file input_fileOchrana souboru před přepsáním
V Linuxu je možné chránit soubory před přepsáním operátorem „>“.
Své soubory můžete chránit nastavením parametru „noclobber“ v aktuálním prostředí shellu.
$ set -o noclobberJe také možnéomezit přesměrování výstupu spuštěním
$ set -CPoznámka :pro opětovné povolení přesměrování výstupu jednoduše spusťte set +C
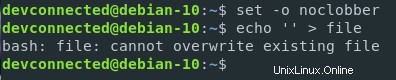
Jak vidíte, soubor nelze při nastavování tohoto parametru přepsat.
Pokud opravdu chci vynutit přepsání, mohu použít „>| ” k vynucení.

3 – Co je přesměrování vstupu v systému Linux?
a – Jak funguje přesměrování vstupu?
Přesměrování vstupu je akt přesměrování vstupu procesu na dané zařízení (nebo virtuální zařízení), takže začne číst z tohoto zařízení a ne z výchozího zařízení přiřazeného jádrem.
Například, když otevíráte terminál, komunikujete s ním pomocí klávesnice.
Existují však případy, kdy můžete chtít pracovat s obsahem souboru, protože chcete programově odeslat obsah souboru vašemu příkazu.
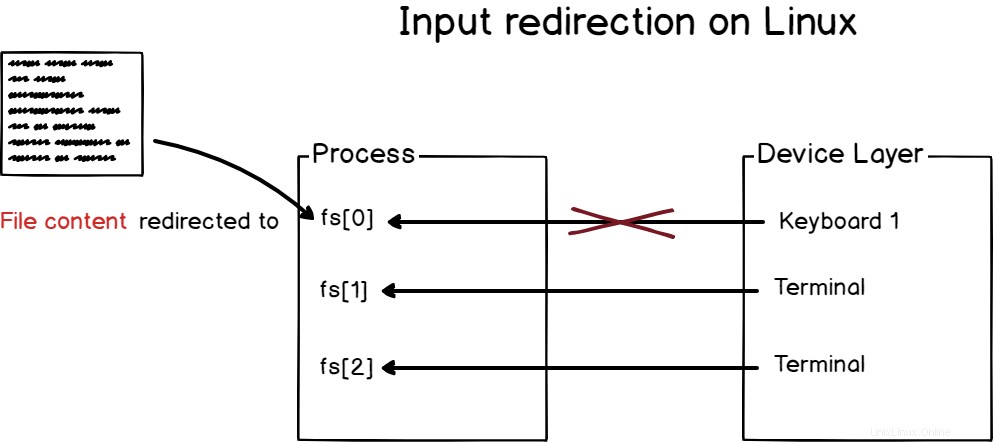
Chcete-li přesměrovat standardní vstup v systému Linux, musíte použít operátor „<“.
Řekněme například, že chcete použít obsah souboru a spustit na něm speciální příkaz.
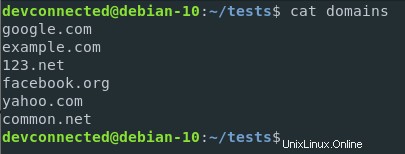
V tomto případě použiji soubor obsahující domény a příkaz bude jednoduchý příkaz pro řazení.
Tímto způsobem budou domény seřazeny podle abecedy.
S přesměrováním vstupu mohu spustit následující příkaz
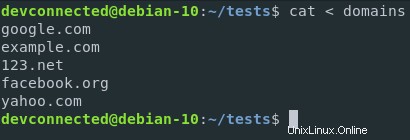
Pokud chci tyto domény seřadit, mohu přesměrovat obsah souboru domén na standardní vstup funkce řazení.
$ sort < domains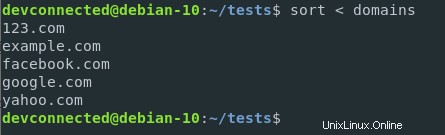
Pomocí této syntaxe je obsah souboru domén přesměrován na vstup funkce řazení. Je zcela odlišná od následující syntaxe
$ sort domainsI když může být výstup stejný, v tomto případě funkce řazení bere jako parametr soubor.
V příkladu přesměrování vstupu je funkce řazení volána bez parametru.
V důsledku toho, když funkci nejsou poskytnuty žádné parametry souboru, funkce je standardně čte ze standardního vstupu.
V tomto případě se jedná o čtení obsahu poskytnutého souboru.
b – Přesměrování standardního vstupu pomocí souboru obsahujícího více řádků
Pokud váš soubor obsahuje více řádků, stále můžete přesměrovat standardní vstup z vašeho příkazu pro každý jednotlivý řádek vašeho souboru.
Řekněme například, že chcete mít požadavek ping pro každou jednotlivou položku v souboru domén.
Ve výchozím nastavení příkaz ping očekává, že bude ping odeslána jedna IP nebo URL.
Můžete však přesměrovat obsah souboru vašich domén na vlastní funkci, která spustí funkci ping pro každý záznam.
$ ( while read ip; do ping -c 2 $ip; done ) < ips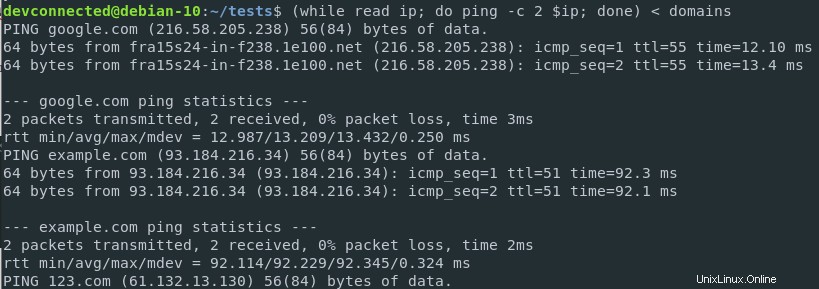
c – Kombinace přesměrování vstupu s přesměrováním výstupu
Nyní, když víte, že standardní vstup lze přesměrovat na příkaz, je užitečné zmínit, že přesměrování vstupu a výstupu lze provést v rámci stejného příkazu.
Nyní, když provádíte příkazy ping, získáváte statistiky pingu pro každou jednotlivou webovou stránku na seznamu domén.
Výsledky jsou vytištěny na standardním výstupu, kterým je v tomto případě terminál.
Ale co když chcete uložit výsledky do souboru?
Toho lze dosáhnout kombinací přesměrování vstupu a výstupu ve stejném příkazu .
$ ( while read ip; do ping -c 2 $ip; done ) < domains > stats.txt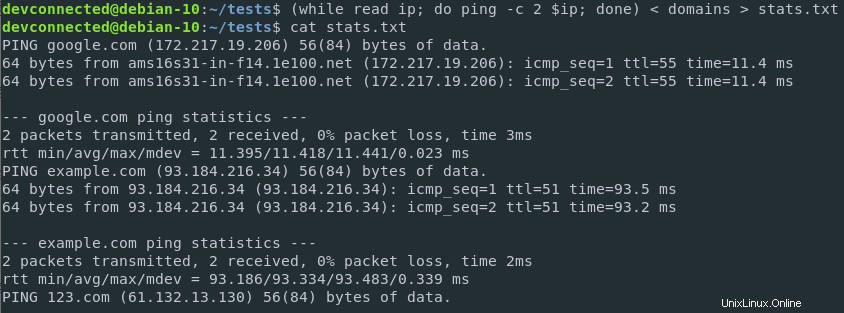
Skvělý!
Výsledky byly správně uloženy do souboru a mohou být později analyzovány jinými týmy ve vaší společnosti.
d – Úplné vyřazení standardního výstupu
V některých případech může být užitečné standardní výstup úplně zahodit.
Může to být proto, že vás nezajímá standardní výstup procesu nebo protože tento proces tiskne příliš mnoho řádků na standardní výstup.
Chcete-li v systému Linux zcela zahodit standardní výstup, přesměrujte standardní výstup do /dev/null.
Přesměrování na /dev/null způsobí úplné zahození a vymazání dat.
$ cat file > /dev/nullPoznámka:přesměrování na /dev/null nevymaže obsah souboru, ale pouze zahodí obsah standardního výstupu.
4 – Co je standardní přesměrování chyb v systému Linux?
Nakonec, po přesměrování vstupu a výstupu, se podívejme, jak lze přesměrovat standardní chybu.
a – Jak funguje standardní přesměrování chyb?
Velmi podobně jako to, co jsme viděli dříve, přesměrování chyb je přesměrování chyb vrácených procesy na definované zařízení na vašem hostiteli.
Pokud například spouštím příkaz se špatnými parametry, na obrazovce vidím chybovou zprávu, která byla zpracována pomocí deskriptoru souboru odpovědného za chybové zprávy (fd[2]).>
Všimněte si, že neexistují žádné triviální způsoby, jak odlišit chybovou zprávu od standardní výstupní zprávy v terminálu, budete se muset spolehnout na to, že programátor odešle chybové zprávy do správného deskriptoru souboru.
Chcete-li přesměrovat chybový výstup v systému Linux, použijte „2> ” operátor
$ command 2> filePoužijme příklad příkazu ping k vygenerování chybové zprávy na terminálu.

Nyní se podíváme na verzi, kde je chybový výstup přesměrován do chybového souboru.

Jak vidíte, použil jsem operátor „2>“ k přesměrování chyb do souboru „error-file“.
Pokud bych do souboru přesměroval pouze standardní výstup, nic by se do něj nevytisklo.

Jak můžete vidět, chybová zpráva byla vytištěna na můj terminál a do mého výstupu „normálního souboru“ nebylo nic přidáno.
b – Kombinace standardní chyby se standardním výstupem
V některých případech můžete chtít zkombinovat chybové zprávy se standardním výstupem a přesměrovat jej do souboru.
Může to být obzvláště užitečné, protože některé programy nevracejí pouze standardní zprávy nebo chybové zprávy, ale také kombinaci dvou.
Vezměme si příklad najít příkaz.
Pokud spouštím příkaz find v kořenovém adresáři bez práv sudo, mohu mít neoprávněný přístup k některým adresářům, jako jsou například procesy, které nevlastním.
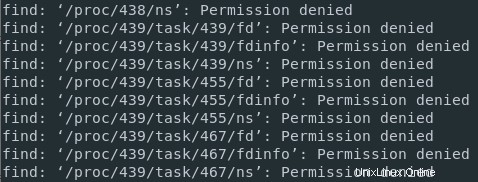
V důsledku toho bude docházet ke směsi standardních zpráv (soubory vlastněné mým uživatelem) a chybové zprávy (při pokusu o přístup k adresáři, který nevlastním).
V tomto případě chci mít oba výstupy uložené do souboru.
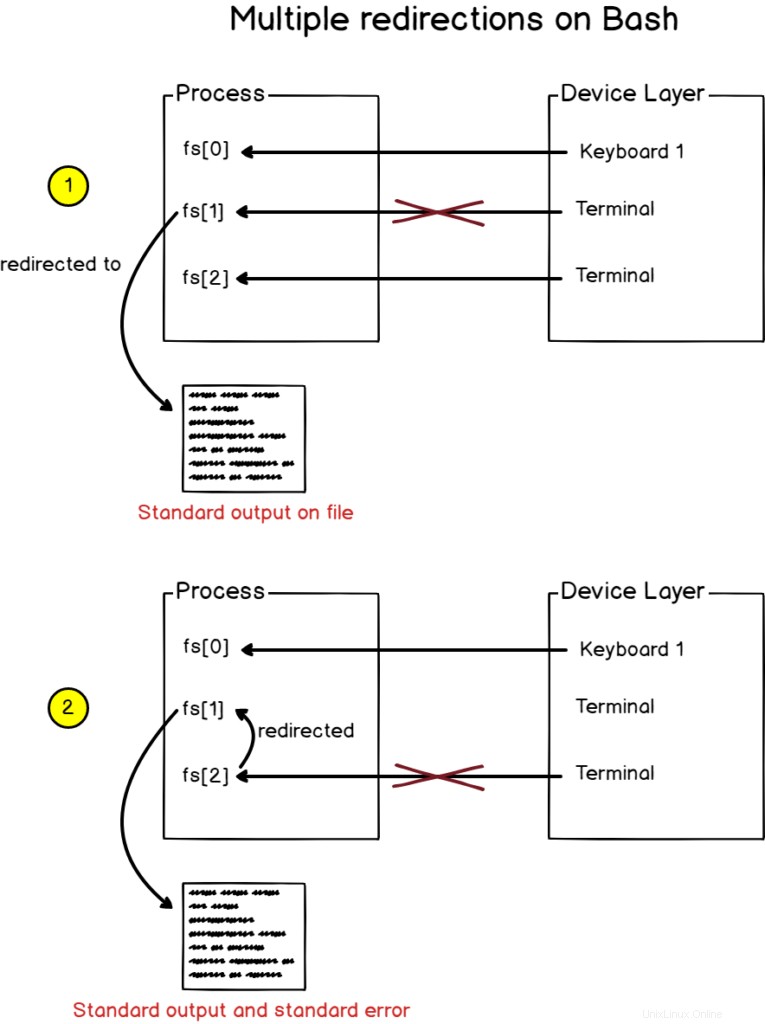
Chcete-li přesměrovat standardní výstup i chybový výstup do souboru, použijte syntaxi „2<&1“ s předchozím „>“.
$ find / -user devconnected > file 2>&1Případně můžete použít „&>“ syntaxe jako kratší způsob přesměrování výstupu i chyb.
$ find / -user devconnected &> fileTak co se tady stalo?
Když bash vidí více přesměrování, zpracuje je z zleva doprava
V důsledku toho je výstup funkce find nejprve přesměrován do souboru.
Dále je zpracováno druhé přesměrování a přesměruje standardní chybu na standardní výstup (který byl dříve přiřazen k souboru).
5 – Co jsou kanály v Linuxu?
Pipelines se trochu liší od přesměrování.
Při standardním přesměrování vstupu nebo výstupu jste v podstatě přepsali výchozí vstup nebo výstup do vlastního souboru.
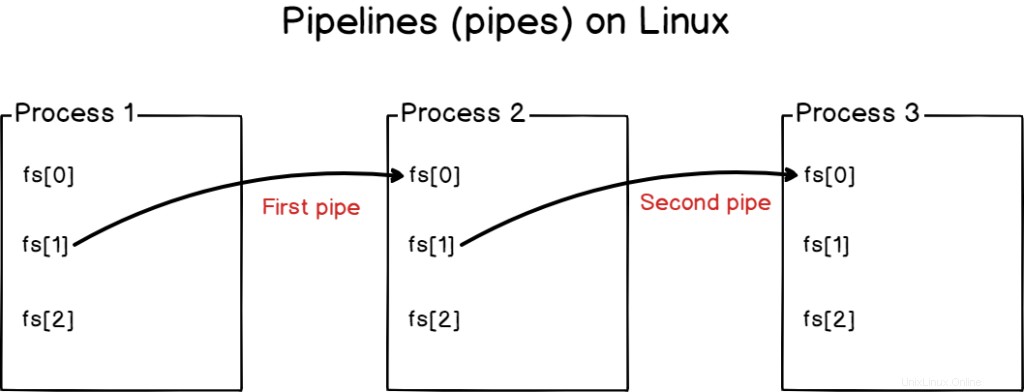
U potrubí nepřepisujete vstupy ani výstupy, ale spojujete je dohromady.
Pipelines se v systémech Linux používají k propojení procesů a propojení standardních výstupů z jednoho programu se standardním vstupem jiného programu.
Pomocí potrubí lze propojit více procesů (nebo potrubí )
Správci systému často využívají kanály k vytváření složitých dotazů spojením jednoduchých dotazů dohromady.
Jedním z nejpopulárnějších příkladů je pravděpodobně počítání počtu řádků v textovém souboru po použití některých vlastních filtrů na obsah souboru.
Vraťme se k souboru domén, který jsme vytvořili v předchozích částech, a změňme přípony jejich zemí tak, aby zahrnovaly domény .net.
Nyní řekněme, že chcete spočítat počty domén .com v souboru.
Jak byste to provedli? Pomocí potrubí.
Nejprve chcete filtrovat výsledky tak, aby byly v souboru izolovány pouze domény .com. Pak chcete výsledek přenést do příkazu „wc“, abyste je mohli spočítat.
Zde je návod, jak byste v souboru počítali domény .com.
$ grep .com domains | wc -l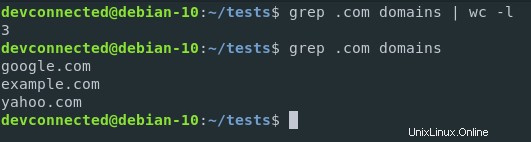
Zde je to, co se stalo s diagramem pro případ, že mu stále nerozumíte.
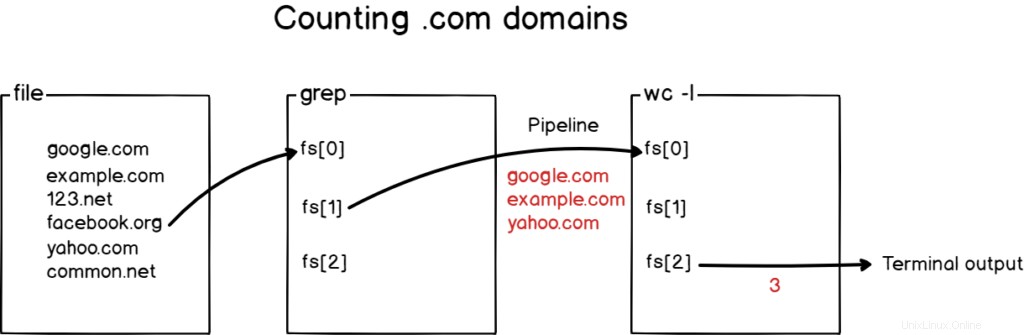
Skvělé!
6 – Závěr
V dnešním tutoriálu jste se naučili, co je přesměrování vstupu a výstupu a jak jej lze efektivně využít k provádění administrativních operací na vašem systému Linux.
Také jste se dozvěděli o potrubích (nebo potrubích) které se používají k řetězení příkazů za účelem provádění delších a složitějších příkazů na vašem hostiteli.
Pokud vás zajímá administrace Linuxu, máme pro ni na devconnected celou kategorii, takže se na to určitě podívejte!