Když používáte textový procesor, formátování textu tak, aby se řádky vešly do dostupného prostoru na cílovém zařízení, by neměl být problém. Ale při práci na terminálu to není tak snadné.
Řádky můžete samozřejmě vždy přerušovat ručně pomocí svého oblíbeného textového editoru, ale to je zřídka žádoucí a pro automatizované zpracování to nepřipadá v úvahu.
Doufejme, že POSIX fold a GNU/BSD fmt příkaz vám může pomoci přeformátovat text tak, aby řádky nepřesáhly danou délku.
Co je to zase řádek v Unixu?
Než se pustíte do podrobností o přehybu a fmt příkazy, pojďme nejprve definovat, o čem mluvíme. V textovém souboru je řádek vytvořen z libovolného počtu znaků, za nimiž následuje speciální kontrolní sekvence nového řádku (někdy nazývaná EOL, pro konec řádku )
Na systémech podobných Unixu je řídicí sekvence na konci řádku tvořena (jediným) znakem line feed , někdy zkráceně LF nebo psáno \n podle konvence převzaté z jazyka C. Na binární úrovni je znak odřádkování reprezentován jako bajt obsahující 0a hexadecimální hodnotu.
Můžete to snadno zkontrolovat pomocí hexdump utility, kterou v tomto článku hodně využijeme. Takže to může být dobrá příležitost, abyste se s tímto nástrojem seznámili. Můžete například prozkoumat níže uvedené hexadecimální výpisy a zjistit, kolik znaků nového řádku bylo odesláno každým příkazem echo. Jakmile si myslíte, že máte řešení, zkuste tyto příkazy znovu bez
sh$ echo hello | hexdump -C
00000000 68 65 6c 6c 6f 0a |hello.|
00000006
sh$ echo -n hello | hexdump -C
00000000 68 65 6c 6c 6f |hello|
00000005
sh$ echo -e 'hello\n' | hexdump -C
00000000 68 65 6c 6c 6f 0a 0a |hello..|
00000007
Na tomto místě stojí za zmínku různé operační systémy mohou dodržovat různá pravidla týkající se sekvence nového řádku. Jak jsme viděli výše, operační systémy podobné Unixu používají linkový kanál znak, ale Windows, stejně jako většina internetových protokolů, používají dva znaky:carriage return+line feed pár (CRLF nebo 0d 0a , nebo \r\n ). Na „klasických“ Mac OS (až do MacOS 9.2 včetně na počátku 21. století) používaly počítače Apple jako znak nové řádky samotný CR. Ostatní starší počítače také používaly pár LFCR nebo dokonce zcela odlišné sekvence bajtů v případě starších systémů nekompatibilních s ASCII. Naštěstí ty poslední jsou pozůstatky minulosti a pochybuji, že dnes uvidíte nějaký počítač EBCDIC v provozu!
Když už mluvíme o historii, pokud jste zvědaví, použití řídicích znaků „carriage return“ a „line feed“ pochází z Baudotova kódu používaného v éře dálnopisu. Možná jste viděli dálnopis vyobrazený ve starých filmech jako rozhraní k počítači o velikosti místnosti. Ale ještě předtím byly dálnopisy používány „samostatně“ pro komunikaci z bodu do bodu nebo pro vícebodovou komunikaci. V té době vypadal typický terminál jako těžký psací stroj s mechanickou klávesnicí, papírem a pojízdným vozíkem držícím tiskovou hlavu. Chcete-li začít nový řádek, musí být vozík posunut zpět zcela vlevo a papír se musí pohybovat nahoru otáčením desky (někdy nazývané „válec“). Tyto dva pohyby byly řízeny dvěma nezávislými elektromechanickými systémy, řídicí znaky posunu řádku a návratu vozíku byly přímo připojeny k těmto dvěma částem zařízení. Vzhledem k tomu, že pohyb vozíku vyžaduje více časů než otáčení talíře, bylo logické nejprve zahájit návrat vozíku. Oddělení těchto dvou funkcí mělo také několik zajímavých vedlejších efektů, jako je umožnění přetisku (zasláním pouze CR) nebo efektivní přenos „dvojitého meziřádku“ (jeden CR + dva LF).
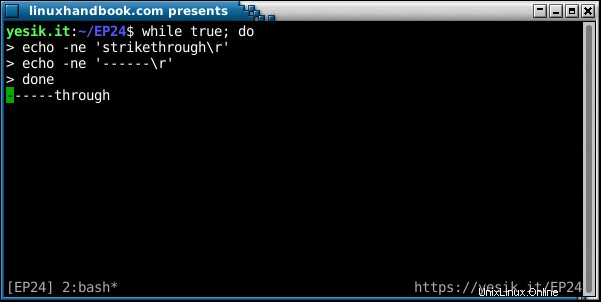
Definice na začátku této části většinou popisuje to, co je logické linka je. Většinou však musí být tato „libovolně dlouhá“ logická linka odeslána na fyzickém zařízení, jako je obrazovka nebo tiskárna, kde je dostupný prostor omezený. Zobrazení krátkých logických řádků na zařízení s většími fyzickými řádky není problém. Prostě napravo od textu je nevyužité místo. Ale co když se pokusíte zobrazit řádek textu větší, než je dostupné místo v zařízení? Ve skutečnosti existují dvě řešení, z nichž každé má své nevýhody:
- Za prvé, zařízení může zkrátit řádky ve své fyzické velikosti, čímž se uživateli skryje část obsahu. Některé tiskárny to dělají, zejména hloupé tiskárny (a ano, dnes se stále používají základní jehličkové tiskárny, zvláště v drsném nebo špinavém prostředí!)
- Druhou možností, jak zobrazit dlouhé logické řádky, je rozdělit je na několik fyzických řádků. Tomu se říká obtékání řádků protože se zdá, že čáry obtékají dostupný prostor, což je efekt zvláště viditelný, pokud můžete změnit velikost displeje, jako když pracujete s emulátorem terminálu.
Tato automatická chování jsou docela užitečná, ale stále existují situace, kdy chcete na dané pozici přerušit dlouhé čáry bez ohledu na fyzickou velikost zařízení. Může být například užitečné, protože chcete, aby se zalomení řádků objevovalo na stejné pozici na obrazovce i na tiskárně. Nebo proto, že chcete, aby byl váš text použit v aplikaci, která neprovádí zalamování řádků (například pokud programově vkládáte text do souboru SVG). A konečně, věřte tomu nebo ne, stále existuje spousta komunikačních protokolů, které ukládají maximální šířku linky při přenosech, včetně populárních, jako je IRC a SMTP (pokud jste někdy viděli chybu 550 Překročena maximální délka linky, víte, co jsem mluvit o). Existuje tedy spousta příležitostí, kdy potřebujete rozbít dlouhé řady na menší kousky. Toto je úkol POSIX fold příkaz.
Příkaz fold
Při použití bez možnosti skládání příkaz přidává další řídicí sekvence nového řádku, aby zajistil, že žádný řádek nepřekročí limit 80 znaků. Aby bylo jasno, jeden řádek bude obsahovat maximálně 80 znaků plus sekvenci nového řádku.
Pokud jste si stáhli podpůrný materiál k tomuto článku, můžete to zkusit sami:
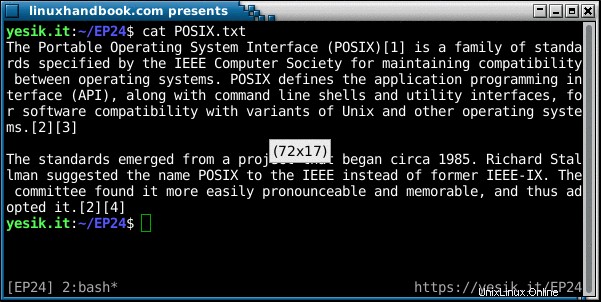
sh$ fold POSIX.txt | head -5
The Portable Operating System Interface (POSIX)[1] is a family of standards spec
ified by the IEEE Computer Society for maintaining compatibility between operati
ng systems. POSIX defines the application programming interface (API), along wit
h command line shells and utility interfaces, for software compatibility with va
riants of Unix and other operating systems.[2][3]
# Using AWK to prefix each line by its length:
sh$ fold POSIX.txt | awk '{ printf("%3d %s\n", length($0), $0) }'
80 The Portable Operating System Interface (POSIX)[1] is a family of standards spec
80 ified by the IEEE Computer Society for maintaining compatibility between operati
80 ng systems. POSIX defines the application programming interface (API), along wit
80 h command line shells and utility interfaces, for software compatibility with va
49 riants of Unix and other operating systems.[2][3]
0
80 The standards emerged from a project that began circa 1985. Richard Stallman sug
80 gested the name POSIX to the IEEE instead of former IEEE-IX. The committee found
71 it more easily pronounceable and memorable, and thus adopted it.[2][4]
Maximální délku výstupního řádku můžete změnit pomocí -w volba. Zajímavější je pravděpodobně použití -s možnost zajistit, že se řádky budou lámat na hranici slova. Porovnejme výsledek bez a s -s možnost při použití na druhý odstavec našeho ukázkového textu:
# Without `-s` option: fold will break lines at the specified position
# Broken lines have exactly the required width
sh$ awk -vRS='' 'NR==2' POSIX.txt |
fold -w 30 | awk '{ printf("%3d %s\n", length($0), $0) }'
30 The standards emerged from a p
30 roject that began circa 1985.
30 Richard Stallman suggested the
30 name POSIX to the IEEE instea
30 d of former IEEE-IX. The commi
30 ttee found it more easily pron
30 ounceable and memorable, and t
21 hus adopted it.[2][4]
# With `-s` option: fold will break lines at the last space before the specified position
# Broken lines are shorter or equal to the required width
awk -vRS='' 'NR==2' POSIX.txt |
fold -s -w 30 | awk '{ printf("%3d %s\n", length($0), $0) }'
29 The standards emerged from a
25 project that began circa
23 1985. Richard Stallman
28 suggested the name POSIX to
27 the IEEE instead of former
29 IEEE-IX. The committee found
29 it more easily pronounceable
24 and memorable, and thus
17 adopted it.[2][4]
Je zřejmé, že pokud váš text obsahuje slova delší než maximální délka řádku, příkaz fold nebude schopen respektovat -s vlajka. V takovém případě fold obslužný program přeruší příliš velká slova na maximální pozici a vždy zajistí, že žádný řádek nepřekročí maximální povolenou šířku.
sh$ echo "It's Supercalifragilisticexpialidocious!" | fold -sw 10
It's
Supercalif
ragilistic
expialidoc
ious!Vícebajtové znaky
Jako většina, ne-li všechny, základní nástroje, fold příkaz byl navržen v době, kdy jeden znak odpovídal jednomu bajtu. To však již není případ moderních počítačů, zejména s rozšířeným přijetím UTF-8. Něco, co vede k nešťastným problémům:
# Just in case, check first the relevant locale
# settings are properly defined
debian-9.4$ locale | grep LC_CTYPE
LC_CTYPE="en_US.utf8"
# Everything is OK, unfortunately...
debian-9.4$ echo élève | fold -w2
é
l�
�v
e
Slovo „élève“ (francouzské slovo pro „student“) obsahuje dvě písmena s diakritikou:é (LATINSKÉ MALÉ PÍSMENO E S AKUTNÍM) a è (LATINSKÉ MALÉ PÍSMENO E S HROBEM). Pomocí znakové sady UTF-8 jsou tato písmena zakódována pomocí dvou bajtů každé (respektive c3 a9 a c3 a8 ), namísto pouze jednoho bajtu, jak je tomu u latinských písmen bez diakritiku. Můžete to zkontrolovat prozkoumáním nezpracovaných bajtů pomocí hexdump užitečnost. Měli byste být schopni určit bajtové sekvence odpovídající é a è znaky. Mimochodem, v tom výpisu můžete také vidět našeho starého přítele znak pro odřádkování, jehož hexadecimální kód byl zmíněn dříve:
debian-9.4$ echo élève | hexdump -C
00000000 c3 a9 6c c3 a8 76 65 0a |..l..ve.|
00000008Podívejme se nyní na výstup vytvořený příkazem fold:
debian-9.4$ echo élève | fold -w2
é
l�
�v
e
debian-9.4$ echo élève | fold -w 2 | hexdump -C
00000000 c3 a9 0a 6c c3 0a a8 76 0a 65 0a |...l...v.e.|
0000000b
Je zřejmé, že výsledek vytvořený fold příkaz je o něco delší než původní řetězec znaků kvůli dalším novým řádkům:respektive 11 bajtů dlouhý a 8 bajtů dlouhý, včetně nových řádků. Když už o tom mluvíme, ve výstupu fold možná jste viděli posun řádku (0a ) znak objevující se každé dva bajty. A to je přesně ten problém:příkaz fold přerušil řádky na byte pozice, nikoli na znak pozice. I když k tomuto přerušení dojde uprostřed vícebajtového znaku! Není třeba zmiňovat, že výsledný výstup již není platným tokem bajtů UTF-8, proto se používá náhradní znak Unicode (� ) mým terminálem jako zástupný symbol pro neplatné sekvence bajtů.
Stejně jako u cut příkaz, o kterém jsem psal před několika týdny, jde o omezení v GNU implementaci fold utility a to je jasně v rozporu se specifikacemi POSIX, které výslovně stanoví, že „Řádek nesmí být uprostřed znaku přerušovaný.“
Vypadá to tedy jako GNU fold implementace správně řeší pouze jednobajtová kódování znaků s pevnou délkou (US-ASCII, Latin1 atd.). Jako náhradní řešení, pokud existuje vhodná znaková sada, můžete svůj text před zpracováním překódovat na jednobajtové kódování znaků a poté jej překódovat zpět do UTF-8. To je však přinejmenším těžkopádné:
debian-9.4$ echo élève |
iconv -t latin1 | fold -w 2 |
iconv -f latin1 | hexdump -C
00000000 c3 a9 6c 0a c3 a8 76 0a 65 0a |..l...v.e.|
0000000a
debian-9.4$ echo élève |
iconv -t latin1 | fold -w 2 |
iconv -f latin1
él
èv
e
To vše mě docela zklamalo a rozhodl jsem se zkontrolovat chování jiných implementací. Jak to často bývá, OpenBSD implementace fold utility je v tomto ohledu mnohem lepší, protože je kompatibilní s POSIX a bude respektovat LC_CTYPE nastavení národního prostředí pro správné zpracování vícebajtových znaků:
openbsd-6.3$ locale | grep LC_CTYPE
LC_CTYPE=en_US.UTF-8
openbsd-6.3$ echo élève | fold -w 2 C
él
èv
e
openbsd-6.3$ echo élève | fold -w 2 | hexdump -C
00000000 c3 a9 6c 0a c3 a8 76 0a 65 0a |..l...v.e.|
0000000aJak můžete vidět, implementace OpenBSD správně ořezala řádky na znak pozic, bez ohledu na počet bajtů potřebných k jejich zakódování. V drtivé většině případů použití je to to, co chcete. Pokud však potřebujete chování staršího (tj. GNU stylu) s ohledem na jeden bajt jako jeden znak, můžete dočasně změnit aktuální národní prostředí na tzv. POSIX locale (identifikované konstantou „POSIX“ nebo z historických důvodů „C “):
openbsd-6.3$ echo élève | LC_ALL=C fold -w 2
é
l�
�v
e
openbsd-6.3$ echo élève | LC_ALL=C fold -w 2 | hexdump -C
00000000 c3 a9 0a 6c c3 0a a8 76 0a 65 0a |...l...v.e.|
0000000b
Nakonec POSIX specifikuje -b příznak, který dává pokyn pro fold nástroj pro měření délky řádku v bajtech , ale to přesto zaručuje vícebajtové znaky (podle aktuálního LC_CTYPE nastavení národního prostředí) nebude být zlomený.
Jako cvičení vám důrazně doporučuji věnovat čas potřebný k nalezení rozdílů na úrovni bajtů mezi výsledkem získaným změnou aktuálního národního prostředí na „C“ (výše) a výsledkem získaným pomocí -b místo toho příznak (níže). Může to být jemné. Ale existuje rozdíl:
openbsd-6.3$ echo élève | fold -b -w 2 | hexdump -C
00000000 c3 a9 0a 6c 0a c3 a8 0a 76 65 0a |...l....ve.|
0000000bTak co, našli jste ten rozdíl?
No, změnou národního prostředí na "C", fold obslužný program se o vícebajtové sekvence nestaral – protože podle definice, když je národní prostředí „C“, nástroje musí předpokládat jeden znak je jeden bajt . Nový řádek lze tedy přidat kdekoli, dokonce i uprostřed sekvence bajtů, které by byly považovány za vícebajtový znak v jiném kódování znaků. Přesně to se stalo, když nástroj vytvořil c3 0a a8 bajtová sekvence:dva bajty c3 a8 jsou chápány jako jeden znak když LC_CTYPE definuje kódování znaků na UTF-8. Ale stejná sekvence bajtů je považována za dva znaky v národním prostředí „C“:
# Bytes are bytes. They don't change so
# the byte count is the same whatever is the locale
openbsd-6.3$ printf "%d bytes\n" $(echo -n é | LC_ALL=en_US.UTF-8 wc -c)
2 bytes
openbsd-6.3$ printf "%d bytes\n" $(echo -n é | LC_ALL=C wc -c)
2 bytes
# The interpretation of the bytes may change depending on the encoding
# so the corresponding character count will change
openbsd-6.3$ printf "%d chars\n" $(echo -n é | LC_ALL=en_US.UTF-8 wc -m)
1 chars
openbsd-6.3$ printf "%d chars\n" $(echo -n é | LC_ALL=C wc -m)
2 chars
Na druhou stranu s -b nástroj by měl být stále vícebajtový. Tato možnost se mění pouze ve způsobu, jakým počítá pozice , tentokrát v bajtech, spíše než ve znacích, jak je to standardně. V takovém případě, protože vícebajtové sekvence nejsou rozděleny, výsledný výstup zůstává platným znakovým proudem (podle aktuálního LC_CTYPE nastavení národního prostředí):
openbsd-6.3$ echo élève | fold -b -w 2
é
l
è
ve
Už jste to viděli, náhradní znak Unicode se již nevyskytuje (� ) a v tomto procesu jsme neztratili žádný smysluplný znak – na úkor toho, že jsme tentokrát skončili s řádky obsahujícími proměnný počet znaků a proměnlivý počet bajtů. A konečně, veškerý nástroj zajišťuje, že na řádku není více bajtů, než je požadováno pomocí -w volba. Něco, co můžeme zkontrolovat pomocí wc nástroj:
openbsd-6.3$ echo élève | fold -b -w 2 | while read line; do
> printf "%3d bytes %3d chars %s\n" \
> $(echo -n $line | wc -c) \
> $(echo -n $line | wc -m) \
> $line
> done
2 bytes 1 chars é
1 bytes 1 chars l
2 bytes 1 chars è
2 bytes 2 chars ve
Ještě jednou si věnujte čas potřebný ke studiu výše uvedeného příkladu. Využívá printf a wc příkazy, které jsem dříve podrobně nevysvětloval. Pokud tedy věci nejsou dostatečně jasné, neváhejte použít sekci komentářů a požádat o vysvětlení!
Ze zvědavosti jsem zkontroloval -b flag na mém Debian boxu pomocí GNU fold implementace:
debian-9.4$ echo élève | fold -w 2 | hexdump -C
00000000 c3 a9 0a 6c c3 0a a8 76 0a 65 0a |...l...v.e.|
0000000b
debian-9.4$ echo élève | fold -b -w 2 | hexdump -C
00000000 c3 a9 0a 6c c3 0a a8 76 0a 65 0a |...l...v.e.|
0000000b
Neztrácejte čas hledáním rozdílu mezi -b a non--b verze tohoto příkladu:viděli jsme, že implementace GNU fold nezná vícebajtovou verzi, takže oba výsledky jsou totožné. Pokud o tom nejste přesvědčeni, možná byste mohli použít diff -s příkaz, aby to váš počítač potvrdil. Pokud to uděláte, použijte prosím sekci komentářů ke sdílení příkazu, který jste použili, s ostatními čtenáři!
Každopádně, znamená to -b volba nepoužitelná v GNU implementaci fold užitečnost? Pozornějším čtením dokumentace GNU Coreutils pro fold našel jsem -b možnost se zabývá pouze speciálními znaky jako tabulátor nebo backspace, které se v normálním režimu počítají pro 1~8 (jedna až osm) nebo -1 (mínus jedna) pozice, ale v bajtovém režimu se vždy počítají pro 1 pozici. Matoucí? Možná bychom si mohli vzít nějaký čas, abychom to vysvětlili podrobněji.
Ovládání tabulátorů a backspace
Většina textových souborů, se kterými se budete zabývat, obsahuje pouze tisknutelné znaky a sekvence na konci řádků. Občas se však může stát, že si některé řídicí znaky najdou cestu do vašich dat. Znak tabulátoru (\t ) je jedním z nich. Mnohem vzácněji se používá backspace (\b ) lze také narazit. Stále to zde zmiňuji, protože, jak název napovídá, je to řídicí znak, díky kterému se kurzor posouvá o jednu pozici zpět (směrem doleva), zatímco většina ostatních postav postupuje vpřed (směrem doprava).
sh$ echo -e 'tab:[\t] backspace:[\b]'
tab:[ ] backspace:]
To nemusí být vidět ve vašem prohlížeči, proto vám důrazně doporučuji vyzkoušet to na svém terminálu. Ale znaky tabulátoru (\t ) zaujímá na výstupu několik pozic. A backspace? Zdá se, že ve výstupu je něco divného, že? Nechte tedy věci trochu zpomalit rozdělením textového řetězce na několik částí a vložením spánku mezi nimi:
# For that to work, type all the commands on the same line
# or using backslashes like here if you split them into
# several (physical) lines:
sh$ echo -ne 'tab:[\t] backspace:['; \
sleep 1; echo -ne '\b'; \
sleep 1; echo -n ']'; \
sleep 1; echo ''OK? Viděl jsi to tentokrát? Pojďme si rozložit posloupnost událostí:
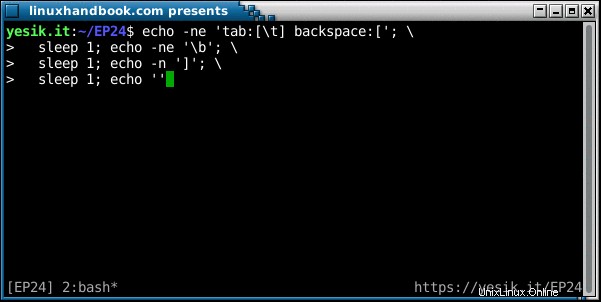
- První řetězec znaků se zobrazuje „normálně“ až po druhou hranatou závorku. Kvůli
-nvlajka,echopříkaz ne odeslat znak nového řádku, takže kurzor zůstane na stejném řádku. - První spánek.
- Je aktivován Backspace, což má za následek posun kurzoru o jednu pozici zpět. Stále žádný nový řádek, takže kurzor zůstává na stejném řádku.
- Druhý spánek.
- Zobrazí se uzavírací hranatá závorka, přepsání ten úvodní.
- Třetí spánek.
- Při absenci
-nmožnost, posledníechopříkaz nakonec odešle znak nového řádku a kurzor se přesune na další řádek, kde se zobrazí výzva shellu.
Samozřejmě, že podobně skvělý efekt lze získat pomocí návratu vozíku, pokud si to pamatujete:
sh$ echo -n 'hello'; sleep 1; echo -e '\rgood bye'
good bye
Jsem si jistý, že jste již viděli nějaký nástroj příkazového řádku, jako je curl , wget nebo ffmpeg zobrazení ukazatele průběhu. Dělají svá kouzla pomocí kombinace \b a/nebo \r .
Je zajímavé, že diskuse může být sama o sobě, cílem zde bylo pochopit, že manipulace s těmito znaky může být pro fold náročná užitečnost. Doufejme, že standard POSIX definuje pravidla:
Všechny tyto speciální úpravy jsou zakázány při použití -b volba. V takovém případě se řídicí znaky počítají (správně) na jeden bajt a tím zvýšit počítadlo pozic o jednu jedinou – stejně jako všechny ostatní postavy.
Pro lepší pochopení vám dovolím, abyste si sami prozkoumali dva následující dva příklady (možná pomocí hexdump užitečnost). Nyní byste měli být schopni zjistit, proč se z „ahoj“ stalo „peklo“ a kde přesně je „i“ ve výstupu (jak tam je, i když ho nevidíte!) Jako vždy, pokud potřebujete pomoc , nebo jednoduše, pokud se chcete podělit o své poznatky, sekce komentářů je vaše.
# Why "hello" has become "hell"? where is the "i"?
sh$ echo -e 'hello\rgood bi\bye' | fold -w4
hell
good
bye
# Why "hello" has become "hell"? where is the "i"?
# Why the second line seems to be made of only two chars instead of 4?
sh$ echo -e 'hello\rgood bi\bye' | fold -bw4
hell
go
od b
yeDalší omezení
Přehyb příkaz, který jsme dosud studovali, byl navržen tak, aby rozdělil dlouhé logické řádky na menší fyzické řádky, zejména pro účely formátování.
To znamená, že předpokládá, že každý vstupní řádek je samostatný a lze jej přerušit nezávisle na ostatních řádcích. To však není vždy případ. Podívejme se například na velmi důležitou zprávu, kterou jsem obdržel:
sh$ cat MAIL.txt
Dear friends,
Have a nice day!
We are manufactuer for event chairs and tables, more than 10 years experience.
We supply all kinds of wooden, resin and metal event chairs, include chiavari
chairs, cross back chairs, folding chairs, napoleon chairs, phoenix chairs, etc.
Our chairs and tables are of high quality and competitively priced.
If you need our products, welcome to contact me;we are happy to make you special
offer.
Best Regards
Doris
sh$ awk '{ length>maxlen && (maxlen=length) } END { print maxlen }' MAIL.txt
81
Je zřejmé, že čáry již byly přerušeny na určitou pevnou šířku. awk příkaz mi řekl, že maximální šířka řádku zde byla … 81 znaků – bez nové sekvence řádků. Ano, to bylo dostatečně zvláštní, takže jsem to dvakrát zkontroloval:skutečně nejdelší řádek má 80 tisknutelných znaků plus jednu mezeru navíc na 81. pozici a teprve poté je znak pro posun odřádku. Pravděpodobně by lidé z IT pracující jménem tohoto „výrobce“ židlí mohli využít čtení tohoto článku!
Každopádně za předpokladu, že bych chtěl změnit formátování tohoto e-mailu, budu mít problémy s fold příkaz z důvodu existujících zalomení řádků. Nechal jsem vás zkontrolovat dva níže uvedené příkazy, pokud chcete, ale žádný z nich nebude fungovat podle očekávání:
sh$ fold -sw 100 MAIL.txt
sh$ fold -sw 60 MAIL.txtPrvní z nich jednoduše neudělá nic, protože všechny řádky jsou již kratší než 100 znaků. Pokud jde o druhý příkaz, zalomí řádky na 60. pozici, ale zachová již existující znaky nového řádku, takže výsledek bude zubatý. Bude to zvláště viditelné ve třetím odstavci:
sh$ awk -v RS='' 'NR==3' MAIL.txt |
fold -sw 60 |
awk '{ length>maxlen && (maxlen=length); print length, $0 }'
53 We supply all kinds of wooden, resin and metal event
25 chairs, include chiavari
60 chairs, cross back chairs, folding chairs, napoleon chairs,
20 phoenix chairs, etc.První řádek třetího odstavce byl přerušen na pozici 53, což je v souladu s naší maximální šířkou 60 znaků na řádek. Druhý řádek se však na pozici 25 zlomil, protože znak nového řádku byl již přítomný ve vstupním souboru. Jinými slovy, abychom správně změnili velikost odstavců, musíme nejprve znovu spojit řádky, než je zalomíme na nové cílové pozici.
Můžete použít sed nebo awk k opětovnému připojení k řadám. A ve skutečnosti, jak jsem to zmínil v úvodním videu, to by pro vás byla dobrá výzva. Neváhejte tedy své řešení zveřejnit v sekci komentářů.
Pokud jde o mě, budu následovat jednodušší cestu, když se podívám na fmt příkaz. I když nejde o standardní příkaz POSIX, je dostupný jak ve světě GNU, tak ve světě BSD. Existuje tedy velká šance, že bude použitelný ve vašem systému. Jak uvidíme později, nedostatek standardizace bude mít bohužel některé negativní důsledky. Ale teď se soustřeďme na ty dobré stránky.
Příkaz fmt
fmt příkaz je vyvinutější než fold příkaz a má více možností formátování. Nejzajímavější na tom je, že dokáže identifikovat odstavce ve vstupním souboru na základě prázdných řádků. To znamená, že všechny řádky až po další prázdný řádek (nebo konec souboru) budou nejprve spojeny dohromady a vytvoří to, co jsem dříve nazval „logický řádek“ textu. Teprve poté fmt příkaz přeruší text na požadované pozici.
Podívejme se nyní, co se změní, když se použije na druhý odstavec mého vzorového e-mailu:
sh$ awk -v RS='' 'NR==3' MAIL.txt |
fmt -w 60 |
awk '{ length>maxlen && (maxlen=length); print length, $0 }'
60 We supply all kinds of wooden, resin and metal event chairs,
59 include chiavari chairs, cross back chairs, folding chairs,
37 napoleon chairs, phoenix chairs, etc.
Anekdoticky, fmt příkaz přijat k zabalení dalšího slova do prvního řádku. Ale zajímavější je, že druhý řádek je nyní vyplněn, což znamená, že znak nového řádku již přítomný ve vstupním souboru poté, co bylo slovo „chiavari“ (co je to?) zahozeno. Samozřejmě, věci nejsou dokonalé a fmt Algoritmus detekce odstavce někdy spouští falešné poplachy, například v pozdravech na konci e-mailu (řádek 14 výstupu):
sh$ fmt -w 60 MAIL.txt | cat -n
1 Dear friends,
2
3 Have a nice day! We are manufactuer for event chairs and
4 tables, more than 10 years experience.
5
6 We supply all kinds of wooden, resin and metal event chairs,
7 include chiavari chairs, cross back chairs, folding chairs,
8 napoleon chairs, phoenix chairs, etc.
9
10 Our chairs and tables are of high quality and competitively
11 priced. If you need our products, welcome to contact me;we
12 are happy to make you special offer.
13
14 Best Regards Doris
Řekl jsem dříve fmt příkaz byl vyvinutější nástroj pro formátování textu než fold užitečnost. Opravdu je. Nemusí to být na první pohled patrné, ale když se podíváte pozorně na řádky 10-11, můžete si všimnout, že jsou použity dva mezery za tečkou – prosazení nejdiskutovanější konvence používání dvou mezer na konci věty. Nebudu se pouštět do této debaty, abych věděl, zda byste měli nebo neměli používat dvě mezery mezi větami, ale zde nemáte na výběr:pokud je mi známo, žádná z běžných implementací fmt příkaz nabídnout příznak pro zakázání dvojité mezery za větou. Pokud taková možnost někde neexistuje a já ji přehlédl? Pokud je to tak, budu rád, když mi o tom dáte vědět pomocí sekce komentářů:jako francouzský spisovatel jsem nikdy nepoužil „dvojitou mezeru“ za větou…
Další možnosti fmt
fmt je navržen s některými více možnostmi formátování než příkaz fold. Nicméně, protože není definováno POSIX, existují velké nekompatibility mezi možnostmi GNU a BSD.
Například -c volba se používá ve světě BSD k vystředění textu, zatímco v GNU Coreutils fmt umožňuje režim korunového okraje, „zachovává odsazení prvních dvou řádků v odstavci a zarovná levý okraj každého následujícího řádku s okrajem druhého řádku. “
Nechal jsem vás experimentovat s GNU fmt -c jestli chceš. Osobně považuji za zajímavější studovat funkci centrování textu BSD kvůli určité zvláštnosti:skutečně v OpenBSD fmt -c vycentruje text podle cílové šířky – ale bez přeformátování! So the following command will not work as you might have expected:
openbsd-6.3$ fmt -c -w 60 MAIL.txt
Dear friends,
Have a nice day!
We are manufactuer for event chairs and tables, more than 10 years experience.
We supply all kinds of wooden, resin and metal event chairs, include chiavari
chairs, cross back chairs, folding chairs, napoleon chairs, phoenix chairs, etc.
Our chairs and tables are of high quality and competitively priced.
If you need our products, welcome to contact me;we are happy to make you special
offer.
Best Regards
Doris
If you really want to reflow the text for a maximum width of 60 characters and center the result, you will have to use two instances of the fmt příkaz:
openbsd-6.3$ fmt -w 60 MAIL.txt | fmt -c -w60
Dear friends,
Have a nice day! We are manufactuer for event chairs and
tables, more than 10 years experience.
We supply all kinds of wooden, resin and metal event chairs,
include chiavari chairs, cross back chairs, folding chairs,
napoleon chairs, phoenix chairs, etc.
Our chairs and tables are of high quality and competitively
priced. If you need our products, welcome to contact me;we
are happy to make you special offer.
Best Regards Doris
I will not make here an exhaustive list of the differences between the GNU and BSD fmt implementations … essentially because all the options are different! Except of course the -w volba. Speaking of that, I forgot to mention -N where N is an integer is a shortcut for -wN . Moreover you can use that shortcut both with the fold and fmt commands:so, if you were perseverent enough to read his article until this point, as a reward you may now amaze your friends by saving one (!) entire keystroke the next time you will use one of those utilities:
debian-9.4$ fmt -50 POSIX.txt | head -5
The Portable Operating System Interface
(POSIX)[1] is a family of standards specified
by the IEEE Computer Society for maintaining
compatibility between operating systems. POSIX
defines the application programming interface
openbsd-6.3$ fmt -50 POSIX.txt | head -5
The Portable Operating System Interface (POSIX)[1]
is a family of standards specified by the IEEE
Computer Society for maintaining compatibility
between operating systems. POSIX defines the
application programming interface (API), along
debian-9.4$ fold -sw50 POSIX.txt | head -5
The Portable Operating System Interface
(POSIX)[1] is a family of standards specified by
the IEEE Computer Society for maintaining
compatibility between operating systems. POSIX
defines the application programming interface
openbsd-6.3$ fold -sw50 POSIX.txt | head -5
The Portable Operating System Interface
(POSIX)[1] is a family of standards specified by
the IEEE Computer Society for maintaining
compatibility between operating systems. POSIX
defines the application programming interface
As the final word, you may also notice in that last example the GNU and BSD versions of the fmt utility are using a different formatting algorithm, producing a different result. On the other hand, the simpler fold algorithm produces consistent results between the implementations. All that to say if portability is a premium, you need to stick with the fold command, eventually completed by some other POSIX utilities. But if you need more fancy features and can afford to break compatibility, take a look at the manual for the fmt command specific to your own system. And let us know if you discovered some fun or creative usage for those vendor-specific options!