Pokud používáte Linux k běžné práci nebo k vývoji a nasazování softwaru, museli jste se s příkazem grep setkat.
V tomto vysvětlujícím článku vám řeknu, co je příkaz grep a jak funguje.
Co je grep?
Grep je nástroj příkazového řádku v systémech Unix a Linux. Používá se k nalezení vyhledávacích vzorů v obsahu daného souboru.
S jeho neobvyklým názvem jste možná uhodli, že grep je zkratka. To je alespoň částečně pravda, ale záleží na tom, koho se ptáte.
Podle renomovaných zdrojů je název ve skutečnosti odvozen od příkazu v textovém editoru UNIX s názvem ed. Ve kterém je vstup g/re/p provedl globální (g) hledání regulárního výrazu (re) a následně vytiskl (p) všechny odpovídající řádky.
Příkaz grep dělá to, co příkazy g/re/p v editoru. Provede globální průzkum regulárního výrazu a vytiskne jej. Je mnohem rychlejší při vyhledávání velkých souborů.

Toto je oficiální narativ, ale můžete jej také vidět popsaný jako G lobální R pravidelné E xpression (P processor | P arser | P tiskárna). Po pravdě řečeno to všechno dělá.
Zajímavý příběh za vytvořením grep
Ken Thompson udělal neuvěřitelné příspěvky do počítačové vědy. Pomohl vytvořit Unix, popularizoval jeho modulární přístup a napsal mnoho jeho programů včetně grep.
Thompson postavil grep, aby pomohl jednomu ze svých kolegů v Bellových laboratořích. Cílem tohoto vědce bylo prozkoumat lingvistické vzorce a identifikovat autory (včetně Alexandra Hamiltona) Federalist Papers. Tento rozsáhlý soubor prací byl sbírkou 85 anonymních článků a esejů vypracovaných na obranu ústavy Spojených států. Ale protože tyto články byly anonymní, vědec se snažil identifikovat autory na základě jazykového vzoru.
Původní unixový textový editor, ed, (také vytvořený Thompsonem) nebyl schopen prohledávat tak velké množství textu vzhledem k hardwarovým omezením té doby. Thompson tedy přeměnil vyhledávací funkci na samostatný nástroj nezávislý na editoru ed.
Pokud o tom přemýšlíte, znamená to, že Alexander Hamilton technicky pomohl vytvořit grep. Neváhejte a podělte se o tento zábavný fakt se svými přáteli na párty s hodinkami Hamilton. 🤓
Co je to opět regulární výraz?
Regulární výraz (nebo regulární výraz) lze považovat za něco jako vyhledávací dotaz. Regulární výrazy se používají k identifikaci, shodě nebo jiné správě textu.
Regex však umí mnohem více než jen vyhledávání klíčových slov. Lze jej použít k nalezení jakéhokoli představitelného vzoru. Vzory lze snáze najít pomocí metaznaků. Tyto speciální znaky, díky nimž je tento vyhledávací nástroj mnohem výkonnější.

Je třeba poznamenat, že grep je pouze jeden nástroj, který používá regex. V celé řadě nástrojů existují podobné možnosti, ale metaznaky a syntaxe se mohou lišit. To znamená, že je důležité znát pravidla pro váš konkrétní procesor regulárních výrazů.
Praktický příklad grep:Párování telefonních čísel
Tento nástroj může zastrašit nováčky i zkušené uživatele Linuxu. Bohužel i relativně jednoduchý vzor, jako je telefonní číslo, může mít za následek „děsivě“ vypadající řetězec regulárních výrazů.
Chci vás ujistit, že není třeba panikařit, když vidíte takové výrazy. Jakmile se seznámíte se základy regulárního výrazu, může vám to otevřít nový svět možností pro vaše počítače.
Kulturní poznámka :Tento příklad používá pro telefonní čísla americké konvence (NANP). Jedná se o 10místná ID, která jsou rozdělena na kód oblasti (3 číslice) a jedinečnou 7místnou kombinaci, kde první 3 číslice odpovídají centrální telekomunikační kanceláři (známé jako předčíslí) a poslední 4 se nazývají linka. číslo. Vzor je tedy AAA-PPP-LLLL.
Vytvořil jsem soubor s názvem phone.txt a zapsali si 4 běžné varianty stejného telefonního čísla. Budu používat grep k rozpoznání číselného vzoru bez ohledu na formát.
Také jsem přidal jeden řádek, který nebude odpovídat výrazu pro použití jako ovládací prvek. Poslední řádek 555!123!1234 není standardní vzor telefonního čísla a nebude vrácen výrazem grep.
Obsah souboru phone.txt soubory jsou:
example@unixlinux.online:~$ cat phone.txt
5551231234
555 123 1234
555-123-1234
(555)-123-1234
555!123!1234
Abych „grep“ telefonní čísla, napíšu svůj regulární výraz pomocí metaznaků, abych izoloval relevantní data a ignoroval to, co nepotřebuji.
Kompletní příkaz bude vypadat takto:
example@unixlinux.online:~$ grep '\(([0-9]\{3\})\|[0-9]\{3\}\)[ -]\?[0-9]\{3\}[ -]\?[0-9]\{4\}' phone.txt
Vypadá to trochu intenzivně, že? Pojďme si to rozdělit na kousky, abychom získali lepší představu o tom, co se děje.
Porozumění regulárnímu výrazu, jeden segment po druhém
Nejprve oddělme část regulárního výrazu, která hledá „předčíslí“ v telefonním čísle.
Podobný vzor se částečně opakuje, aby se získal i zbytek číslic. Je důležité poznamenat, že kód oblasti je někdy zapouzdřen v závorkách, takže to musíte zohlednit pomocí zde uvedeného výrazu.
Logika celé sekce kódu oblasti je zapouzdřena do escapované sady kulatých závorek. Můžete vidět, že můj kód začíná \( a končí \) .
Když použijete hranaté závorky [0-9] , dáváte grepu vědět, že hledáte číslo mezi 0 a 9. Podobně můžete použít [a-z] aby odpovídala písmenům abecedy.
Číslo ve složených závorkách {3\} , znamená, že položka ve hranatých závorkách se shoduje přesně třikrát.
Stále zmatený? Nenechte se vystresovat. Na tento příklad se podíváte několika způsoby, abyste měli jistotu, že půjdete vpřed.
Zkusme se podívat na logiku sekce kódu oblasti v pseudokódu. Izoloval jsem každý segment výrazu.
Pseudokód regulárního kódu oblasti
- \(
- (3místné číslo)
- |
- 3místné číslo
- \)
Doufejme, že když to vidíte takto, bude regex jednodušší. Srozumitelným jazykem hledáte 3místná čísla. Každá číslice může být 0-9 a může existovat nebo nemusí být v závorkách kolem kódu oblasti.
Pak je na konci naší první části jeden zvláštní kousek.
- [ -]\?
Co to znamená? \? symbol znamená "odpovídá nule nebo jednomu z předchozích znaků". Zde se jedná o to, co je v našich hranatých závorkách [ -] .
Jinými slovy, za číslicemi může nebo nemusí být spojovník.
Kód oblasti
Nyní znovu sestavme stejný blok se skutečným kódem. Poté přidám další části výrazu.
- \(
- ([0-9]\{3\})
- |
- [0-9]\{3\}
- \)
- [ -]\?
Předpona
Chcete-li dokončit vzor telefonního čísla, stačí znovu použít některý ze stávajících kódů.
[0-9]\{3\}[ -]\?
Nemusíte se obávat závorek kolem předpony, ale stále můžete nebo nemusíte mít - mezi předčíslím a číslicemi řádku telefonního čísla.
Čísla řádků
Poslední část telefonního čísla nevyžaduje, abychom hledali další znaky, ale musíte aktualizovat výraz, aby odrážel další číslici.
[0-9]\{4\}
A je to. Nyní se ujistěte, že výraz je obsažen v uvozovkách, aby se minimalizovalo neočekávané chování.
Zde je znovu úplný výraz
example@unixlinux.online:~$ grep '\(([0-9]\{3\})\|[0-9]\{3\}\)[ -]\?[0-9]\{3\}[ -]\?[0-9]\{4\}' phone.txt
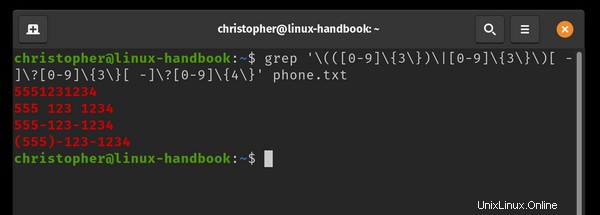
Můžete vidět, že výsledky jsou barevně zvýrazněny. Toto nemusí být výchozí chování vaší distribuce Linuxu.
Bonusový tip
Pokud chcete, aby byly vaše výsledky zvýrazněny, můžete přidat --color=auto na tvůj příkaz. Můžete to také přidat do svého profilu prostředí jako alias, takže pokaždé, když zadáte grep běží jako grep --color=auto .
Doufám, že nyní lépe rozumíte příkazu grep. Pro vysvětlení jsem ukázal jen jeden příklad. Máte-li zájem, můžete se podívat na tento článek, kde najdete další praktické příklady příkazu grep.
Uveďte svůj návrh na článek zanecháním komentáře.