Zde je scénář. Máte velký řetězec a chcete jeho část nahradit jiným řetězcem.
Chcete například změnit „dnes píšu řádek " až " teď píšu řádek ".
."V tomto rychlém tutoriálu vám ukážu, jak nativně nahradit podřetězec v Bash. Ukážu také příklad příkazu sed jako rozšíření.
Nahradit podřetězec nativně v bash (vhodné pro jeden řádek)
Bash má některé vestavěné metody pro manipulaci s řetězci. Pokud chcete nahradit část řetězce jinou, postupujte takto:
${main_string/search_term/replace_term}
Vytvořte řetězcovou proměnnou sestávající z řádku:„Dnes píšu řádek“ bez uvozovek a poté nahraďte today s now :
example@unixlinux.online:~$ line="I am writing a line today"
example@unixlinux.online:~$ echo "${line/today/now}"
I am writing a line now
Rozuměl jsi tomu, co se právě stalo? V syntaxi "${line/today/now}" , line je název proměnné, kam jsem právě uložil celou větu. Zde mu dávám pokyn, aby nahradil první výskyt slova today s now . Takže místo zobrazení obsahu původní proměnné vám to ukázalo řádek se změněným slovem.
Tedy line proměnná se ve skutečnosti nezměnila. Je to stále stejné:
example@unixlinux.online:~$ echo $line
I am writing a line today
Rozhodně však můžete nahradit slovo, které chcete, a upravit stejnou proměnnou, aby byly změny trvalé:
example@unixlinux.online:~$ line="${line/today/now}"
example@unixlinux.online:~$ echo $line
I am writing a line now
Nyní byly změny provedeny jako trvalé a tak můžete trvale nahradit první výskyt podřetězce v řetězci.
Můžete také použít jiné proměnné k uložení konkrétních podřetězců, které chcete nahradit:
example@unixlinux.online:~$ replace="now"
example@unixlinux.online:~$ replacewith="today"
example@unixlinux.online:~$ line="${line/${replace}/${replacewith}}"
example@unixlinux.online:~$ echo $line
I am writing a line today
Zde jsem uložil slovo, které má být nahrazeno, do proměnné s názvem replace a slovo, kterým by bylo nahrazeno uvnitř replacewith . Poté jsem použil stejnou metodu, jaká byla popsána výše, k „revizi“ čáry. Nyní byly změny, které jsem provedl na začátku tohoto tutoriálu, vráceny zpět.
Podívejme se na další příklad:
example@unixlinux.online:~$ hbday="Happy Birthday! Many Many Happy Returns!"
example@unixlinux.online:~$ hbday="${hbday/Many/So Many}"
example@unixlinux.online:~$ echo $hbday
Happy Birthday! So Many Many Happy Returns!
Nahrazení všech výskytů dílčího řetězce
Můžete také nahradit více výskytů podřetězců uvnitř řetězců. Podívejme se na to na dalším příkladu:
example@unixlinux.online:~$ hbday="${hbday//Many/So Many}"
ibexample@unixlinux.online:~$ echo $hbday
Happy Birthday! So Many So Many Happy Returns!
Ten extra / po hbday způsobil, že nahradil všechny výskyty Many s So Many uvnitř věty.
Nahradit řetězec pomocí příkazu sed (může fungovat i se soubory)
Zde je další způsob, jak nahradit podřetězce v řetězci v bash. Použijte příkaz sed tímto způsobem:
Nahradit první výskyt:
line=$(sed "s/$replace/s//$replacewith/" <<< "$line")Pokud vezmu první příklad, lze jej přehrát jako:
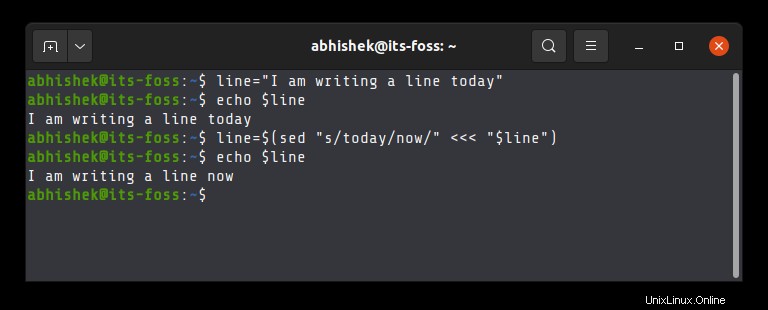
Všechny výskyty můžete také nahradit přidáním g na konci:
line=$(sed "s/$replace/$replacewith/g" <<< "$line")Nyní si můžete myslet, že je to složitější než nativní metoda bashových strun. Možná, ale sed je velmi výkonný a můžete jej použít k nahrazení všech výskytů řetězce v souboru.
sed -i 's/$replace/$replacewith/' filenameZde je příklad některých knih Agathy Christie s „Vražda“ v názvu:
example@unixlinux.online:~$ cat agatha.txt
The Murder in the Vicarage
Murder in Mesopotamia
Murder is Easy
Murder on the Orient Express
Murder In Retrospect
Nahradím Vraždu Manželstvím, protože někteří lidé si myslí, že obojí je stejné:
sed -i "s/Murder/Marriage/g" agatha.txtA zde je nyní změněný soubor:
The Marriage in the Vicarage
Marriage in Mesopotamia
Marriage is Easy
Marriage on the Orient Express
Marriage In Retrospect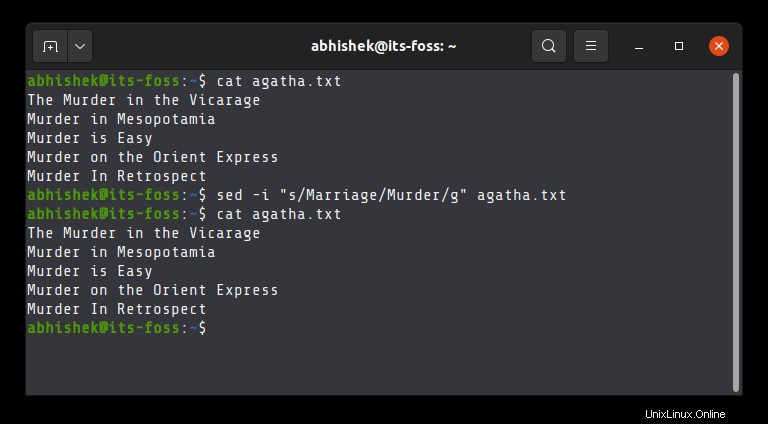
Sed je velmi výkonný nástroj pro úpravu textových souborů v Linuxu. Měli byste se naučit alespoň jeho základy.
Líbilo se vám čtení tohoto článku? Pokud se chcete o výměnu řetězců nebo o tomto článku podělit, udělejte to prosím v komentářích níže.