ripgrep je vynikajícím výsledkem snahy RIIR (přepište to v Rustu), která probíhá v komunitě open source. Má být lepší náhradou za klasický příkaz grep.
Syntaxe pro použití ripgrep je následující:
rg <pattern> [files/directories]U ripgrepu není třeba uvádět název souboru. Pokud není zadán název souboru, prohledají se všechny soubory. To je neuvěřitelně užitečné, pokud nevíte, který soubor obsahuje vzor, který hledáte.
Můžete také použít grep k vyhledávání ve všech souborech, ale ripgrep to dělá bez jakéhokoli dalšího úsilí.
Co je to ripgrep?
ripgrep je rekurzivní nástroj pro porovnávání vzorů regulárních výrazů, který bere v úvahu váš gitignore. Pokud máte ve svém gitignore konkrétní soubory, přípony nebo adresáře, ripgrep je bude ignorovat, čímž urychlí dobu provádění.
Několik funkcí, díky kterým ripgrep vyniká, je následujících:
- Vyhledává vzory rekurzivně v adresářích
- Barevné zvýraznění ve výstupu
- Podporuje širokou škálu formátů kódování, jako je UTF-8, SHIFT_JIS
- Možnost vyhledávat v komprimovaných souborech zip
- Ve výchozím nastavení ignoruje skryté soubory a pro rychlejší vyhledávání používá váš soubor gitignore
Můžete si to představit jako grep, ale primárně zaměřené na vyhledávání souborů/obsahu souborů namísto surového byte streamu, kterým se grep zabývá.
Instalovat ripgrep
Zatímco grep je na většině systémů Linux předinstalovaný, ripgrep toto privilegium nemá.
Je však k dispozici v repozitářích všech hlavních distribucí Linuxu a můžete jej nainstalovat pomocí správce balíčků.
Pokud jste uživatelem Arch Linuxu, již víte, jak instalovat balíčky :p, ale přesto byste měli použít tento příkaz:
pacman -S ripgrepUživatelé Gentoo mohou nainstalovat ripgrep pomocí následujícího příkazu:
emerge sys-apps/ripgrepPokud používáte Fedoru nebo Red Hat, nakloňte si klobouk při psaní tohoto příkazu do terminálu:
sudo dnf install ripgrepUživatelé openSUSE (15.1 a novější) by měli ve svém terminálu použít následující příkaz:
sudo zypper install ripgrepPro uživatele používající Debian Buster (v10) nebo novější použijte apt. Ubuntu Cosmic Cuttlefish (18.10) nebo novější může také používat oficiální úložiště distribuce.
sudo apt install ripgrepPoužití příkazu ripgrep
Pokud jste obeznámeni s používáním příkazů grep, zjistíte, že ripgrep funguje podobně. Zadáte mu vyhledávací řetězec a název souboru a ono prohledá soubor a ukáže vám, kde se vstupní řetězec shodoval s obsahem souboru.
Pro tento tutoriál jsem naklonoval úložiště projektu dust a budu provádět příkazy uvnitř klonovaného úložiště.
Základní vyhledávání
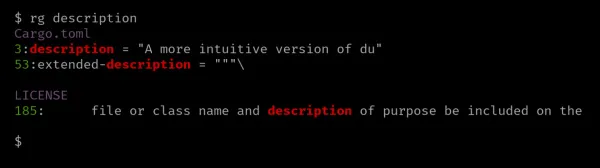
Ukázka hledání popisu slova v souboru Cargo.html:
$ rg description Cargo.toml
3:description = "A more intuitive version of du"
53:extended-description = """\Jak se očekávalo, nástroj ripgrep prohledal soubor, který jsem určil, a zobrazil soubory s odpovídajícím textem a číslem řádku.

Pokud zadáte více souborů, které se mají hledat (pokud neurčíte žádné soubory, vyhledá všechny), ripgrep také určí název souboru, jehož obsah se shodoval.
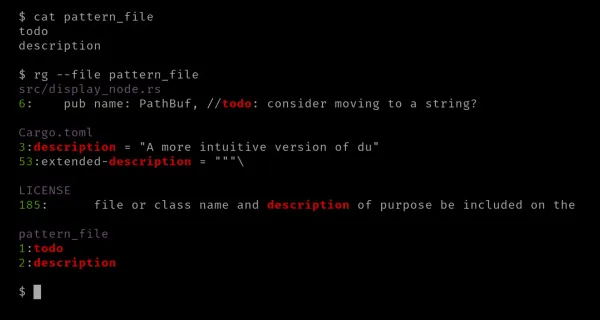
Případně můžete také použít volbu '--file', která obsahuje vzor, který chcete porovnat. Když pravidelně vyhledáváte sadu vzorů, které se mají shodovat, můžete ji uložit do souboru a určit ji pomocí možnosti '--file'.
Kontextové vyhledávání
Někdy je hezké mít kontext odpovídající řádky, zejména při vyhledávání v úložišti kódu. Zde pomáhá možnost '-C' nebo '--context'. Tato možnost přijímá číselnou hodnotu a zobrazuje řádky před a po shodě.
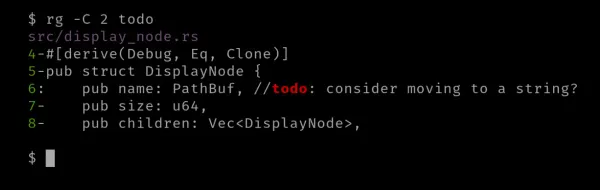
Mohou nastat situace, kdy chcete vidět pouze několik řádků výše, včetně odpovídající řádky. Někdy chcete pouze řádky níže, včetně odpovídající.
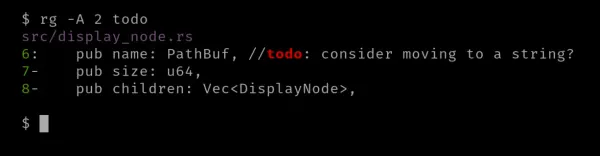
Pro zobrazení řádků po každé shodě můžete použít volbu '-A', zkratku pro '--after-context' a číselnou hodnotu.
A pro řádky před každou shodou můžete použít možnost „-B“, zkratku pro „--before-context“, spolu s číselnou hodnotou.
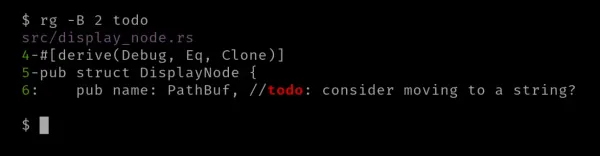
Sloupce
Existuje několik možností týkajících se sloupců, které ripgrep poskytuje.
Příznak '--column' oceníte, pokud jste uživatelem vim. Vytiskne 'line:column' shodného textu v souboru.

Další možností související se sloupci je '-M' nebo '--max-columns', která přebírá číselnou hodnotu pro maximální počet sloupců. Pokud sloupce odpovídajících řádků překročí, budete informováni, že konkrétní řádek byl vynechán z výstupu na terminál.
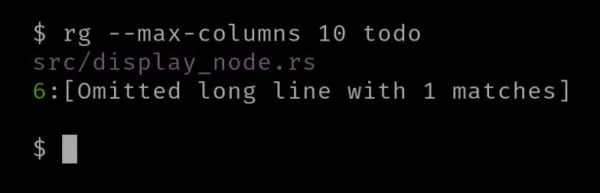
Různé
Existuje několik možností, které můžete použít s ripgrep.
Můžete použít možnost „-s“ nebo „--case-sensitive“ pro přiřazení textu k rozlišení velkých a malých písmen.
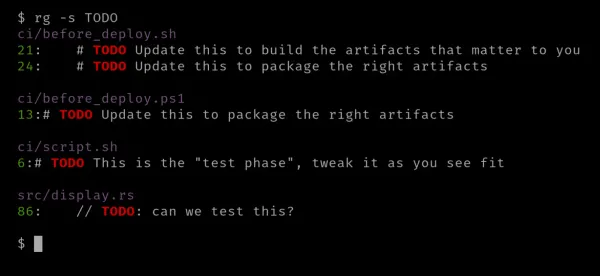
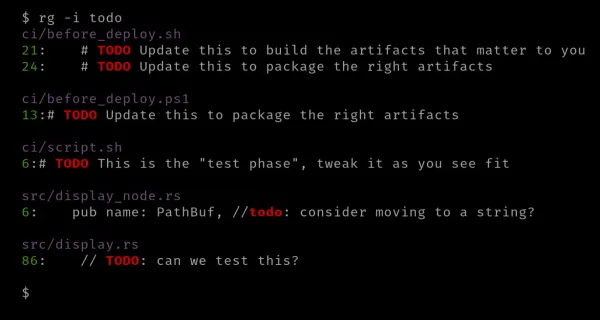
Pokud chcete, aby se nerozlišovala malá a velká písmena, můžete použít příznak „-i“ nebo „--ignore-case“.
Pokud máte obrovskou kódovou základnu, můžete pro porovnávání vzorů použít více vláken. Vlákna můžete zadat ručně pomocí volby '-j' nebo '--threads'; přijímá číselnou hodnotu.
$ rg -j 4 TODOMohou nastat situace, kdy budete chtít vzor z výsledků vyhledávání vyloučit. Chcete-li to provést, můžete použít '-v' nebo '--invert-match' k vyloučení zadaného vzoru.

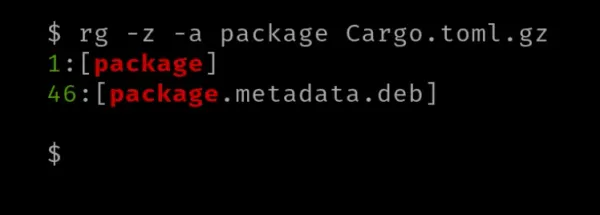
ripgrep může vyhledávat text v komprimovaném archivu (pokud je komprimovaný soubor textový soubor) pomocí příznaku '-z' nebo '--search-zip'. Tento příznak je obvykle doprovázen příznakem '-a', který považuje binární soubory za textové.
Závěr
ripgrep je fantastický nástroj, který můžete využít, zejména jako programátor v prostředí podobném UNIXu.
ripgrep, i když název může naznačovat něco jiného, nemá nahradit grep, protože se chová jinak. Ale oba nástroje jsou přesto užitečné; záleží na vašem případu použití.