V tomto tutoriálu se naučíte používat velmi zásadní grep příkaz v Linuxu. Projdeme si, proč je důležité tento příkaz ovládat a jak jej můžete využít ve svých každodenních úkolech na příkazovém řádku.
Pojďme se rovnou ponořit s několika vysvětleními a příklady.
Proč používáme grep?
Grep je nástroj příkazového řádku, který uživatelé Linuxu používají k vyhledávání řetězců textu. Můžete jej použít k vyhledání určitého slova nebo kombinace slov v souboru, nebo můžete výstup jiných linuxových příkazů převést do grep, takže grep vám může zobrazit pouze výstup, který potřebujete vidět.
Podívejme se na některé skutečně běžné příklady. Řekněme, že potřebujete zkontrolovat obsah adresáře, abyste zjistili, zda v něm existuje určitý soubor. To je něco, k čemu byste použili příkaz „ls“.
Ale aby byl celý tento proces kontroly obsahu adresáře ještě rychlejší, můžete výstup příkazu ls převést do příkazu grep. Podívejme se v našem domovském adresáři na složku s názvem Dokumenty.
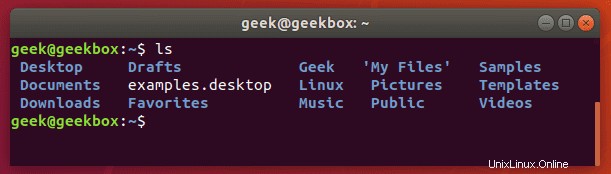
A teď zkusme znovu zkontrolovat adresář, ale tentokrát pomocí grep pro kontrolu konkrétně složky Dokumenty.
$ ls | grep Documents
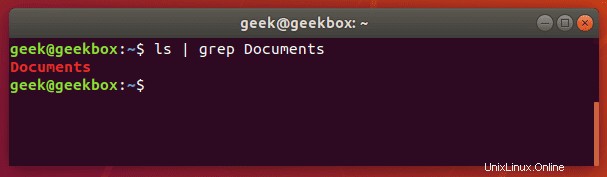
Jak můžete vidět na obrázku výše, použití příkazu grep nám ušetřilo čas tím, že jsme rychle izolovali slovo, které jsme hledali, od zbytku zbytečného výstupu, který příkaz ls vytvořil.
Pokud by složka Dokumenty neexistovala, grep by nevrátil žádný výstup. Pokud tedy grep nic nevrací, znamená to, že nemohl najít slovo, které hledáte.
Najít řetězec
Pokud potřebujete hledat řetězec textu, nikoli pouze jedno slovo, budete muset řetězec zabalit do uvozovek. Co kdybychom například potřebovali hledat adresář „My Documents“ místo adresáře „Documents“ s jedním slovem?
$ ls | grep 'My Documents'
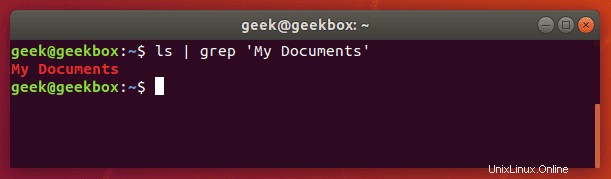
Grep bude akceptovat jednoduché i dvojité uvozovky, takže textový řetězec zalamujte do obou.
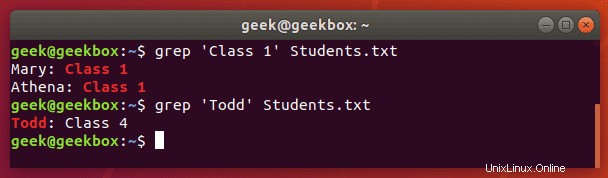
I když můžete použít grep k prohledávání výstupu z jiných nástrojů příkazového řádku, můžete jej také použít k přímému prohledávání dokumentů. Zde je příklad, kdy hledáme v textovém dokumentu řetězec.
$ grep 'Class 1' Students.txt
Najít více řetězců
Můžete také použít grep k nalezení více slov nebo řetězců. Pomocí přepínače -e můžete zadat více vzorů. Zkusme v textovém dokumentu vyhledat dva různé řetězce:
$ grep -e 'Class 1' -e Todd Students.txt
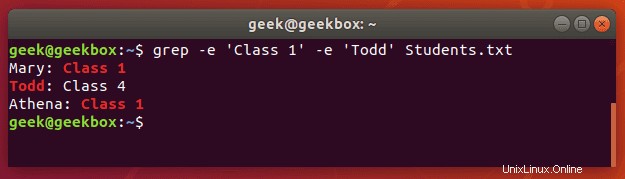
Všimněte si, že jsme potřebovali použít pouze uvozovky kolem řetězců, které obsahovaly mezery.
Rozdíl mezi grep, egrep fgrep, pgrep, zgrep
Různé přepínače grep byly historicky součástí různých binárních souborů. Na moderních systémech Linux najdete tyto přepínače dostupné v příkazu base grep, ale je běžné, že distribuce podporují i další příkazy.
Z manuálové stránky pro grep:
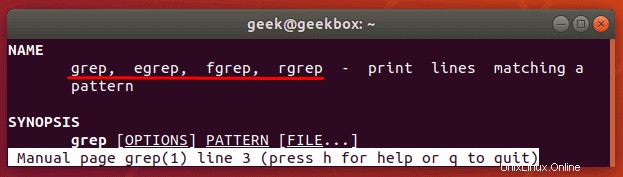
egrep je ekvivalentem grep -E
Tento přepínač bude vzor interpretovat jako rozšířený regulární výraz. S tím můžete dělat spoustu různých věcí, ale zde je příklad toho, jak vypadá použití regulárního výrazu s grep.
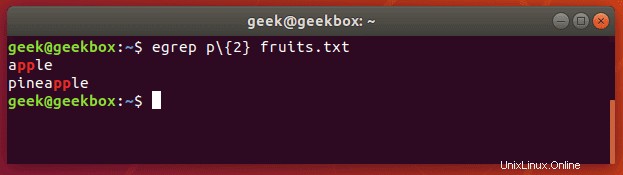
Pojďme v textovém dokumentu vyhledat řetězce, které obsahují dvě po sobě jdoucí písmena „p“:
$ egrep p\{2} fruits.txt nebo
$ grep -E p\{2} fruits.txt
fgrep je ekvivalentem grep -F
Tento přepínač bude interpretovat vzor jako seznam pevných řetězců a pokusí se najít shodu s kterýmkoli z nich. Je to užitečné, když potřebujete hledat znaky regulárních výrazů. To znamená, že nemusíte unikat speciálním znakům, jako byste to udělali s běžným grep.
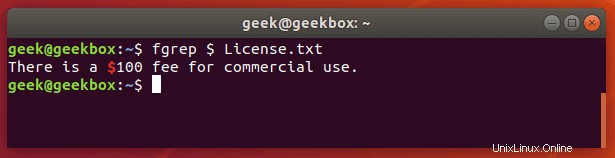
pgrep je příkaz k vyhledání názvu běžícího procesu ve vašem systému a vrácení jeho příslušných ID procesů. Můžete jej například použít k nalezení ID procesu démona SSH:
$ pgrep sshd
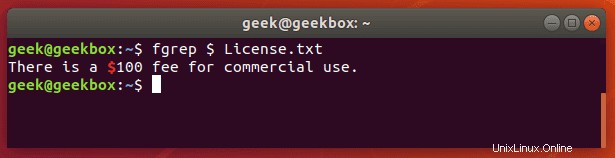
Tato funkce je podobná pouhému propojení výstupu příkazu „ps“ do grep.
Tyto informace můžete použít k ukončení běžícího procesu nebo k řešení problémů se službami běžícími ve vašem systému.
Zgrep můžete použít k vyhledání vzoru v komprimovaných souborech. Umožňuje vám prohledávat soubory uvnitř komprimovaného archivu, aniž byste museli archiv nejprve dekomprimovat, což vám v podstatě ušetří krok nebo dva navíc.
$ zgrep apple fruits.txt.gz
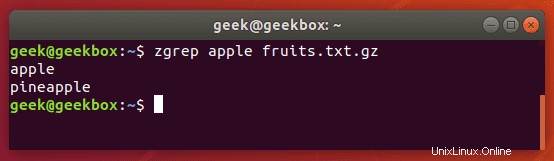
zgrep funguje také na soubory tar, ale zdá se, že jde jen tak daleko, že vám řekne, zda byl schopen najít shodu.
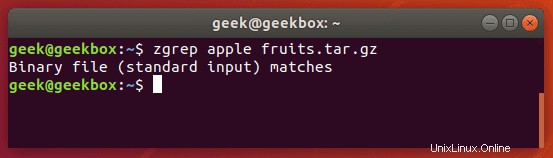
Zmiňujeme to proto, že soubory komprimované pomocí gzip jsou velmi často archivy tar.
Rozdíl mezi find a grep
Pro ty, kteří s příkazovým řádkem Linuxu teprve začínají, je důležité si uvědomit, že find a grep jsou dva příkazy se dvěma velmi odlišnými funkcemi, i když oba používáme k „vyhledání“ něčeho, co uživatel určí.
Je užitečné použít grep k nalezení souboru, když jej použijete k prohledávání výstupu příkazu ls, jak jsme si ukázali v prvních příkladech tutoriálu.
Pokud však potřebujete rekurzivně vyhledat název souboru – nebo část názvu souboru, pokud použijete zástupný znak (hvězdičku), jste mnohem napřed, než použijete příkaz „najít“.
$ find /path/to/search -name name-of-file
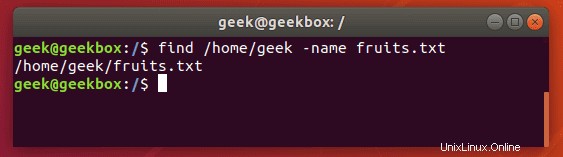
Výše uvedený výstup ukazuje, že příkaz find byl schopen úspěšně najít soubor, který jsme hledali.
Vyhledávejte rekurzivně
Přepínač -r s grep můžete použít k rekurzivnímu prohledávání všech souborů v adresáři a jeho podadresářích pro zadaný vzor.
$ grep -r pattern /directory/to/search
Pokud nezadáte adresář, grep pouze prohledá váš aktuální pracovní adresář. Na níže uvedeném snímku obrazovky nalezl grep dva soubory odpovídající našemu vzoru a vrátil se s názvy souborů a adresářem, ve kterém se nacházejí.

Zachyťte místo nebo tabulátor
Jak jsme zmínili dříve v našem vysvětlení, jak hledat řetězec, můžete text zalomit do uvozovek, pokud obsahuje mezery. Stejná metoda bude fungovat pro karty, ale za chvíli si vysvětlíme, jak vložit kartu do příkazu grep.
Vložte mezeru nebo více mezer do uvozovek, aby grep tento znak vyhledal.
$ grep " " sample.txt
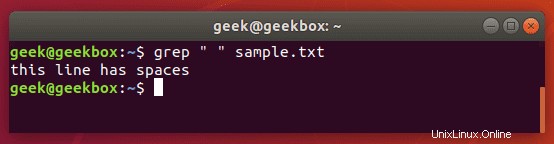
Existuje několik různých způsobů, jak můžete vyhledat kartu pomocí grep, ale většina metod je experimentální nebo může být v různých distribucích nekonzistentní.
Nejjednodušší způsob je vyhledat samotný znak tabulátoru, který můžete vytvořit stisknutím ctrl+v na klávesnici a následným tabulátorem.
Normálně stisknutí tabulátoru v okně terminálu sdělí terminálu, že chcete automaticky dokončit příkaz, ale předchozí stisknutí kombinace ctrl+v způsobí, že se znak tabulátoru vypíše tak, jak byste to normálně očekávali v textovém editoru. .
$ grep " " sample.txt
Znalost tohoto malého triku je zvláště užitečná při procházení konfiguračních souborů v Linuxu, protože tabulátory se často používají k oddělení příkazů od jejich hodnot.
Používání regulárních výrazů
Funkce Grepu je dále rozšířena použitím regulárních výrazů, což vám umožňuje větší flexibilitu při vyhledávání. Existuje jich několik a my projdeme některé z nejběžnějších v níže uvedených příkladech:
[ ] hranaté závorky se používají ke shodě s libovolným ze sady znaků.
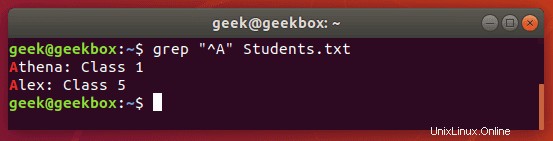
$ grep "Class [123]" Students.txt
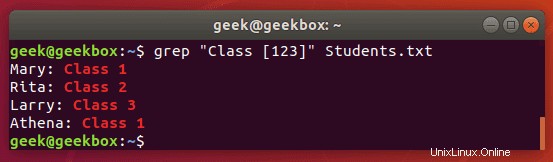
Tento příkaz vrátí všechny řádky s nápisem „Třída 1“, „Třída 2“ nebo „Třída 3“.
[-] hranaté závorky se spojovníkem lze použít k určení rozsahu znaků, ať už číselných nebo abecedních.
$ grep "Class [1-3]" Students.txt
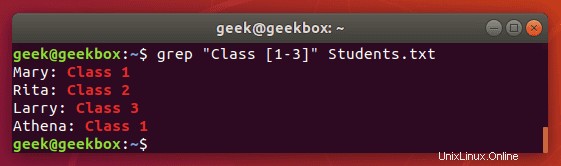
Dostaneme stejný výstup jako předtím, ale příkaz je mnohem snazší psát, zvláště pokud jsme měli větší rozsah čísel nebo písmen.
^ stříška se používá k hledání vzoru, který se vyskytuje pouze na začátku řádku.
$ grep "^Class" Students.txt
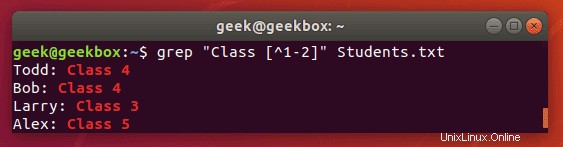
[^] hranaté závorky s stříškou se používají k vyloučení znaků z vyhledávacího vzoru.
$ grep "Class [^1-2]" Students.txt
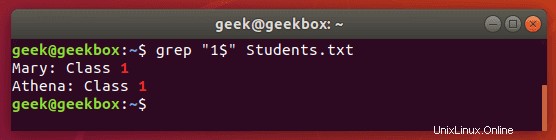
Znak dolaru $ se používá k hledání vzoru, který se vyskytuje pouze na konci řádku.
$ grep "1$" Students.txt
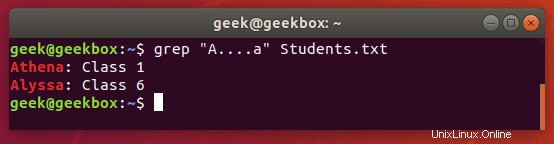
. tečka se používá ke shodě s libovolným jedním znakem, takže je to zástupný znak, ale pouze pro jeden znak.
$ grep "A….a" Students.txt
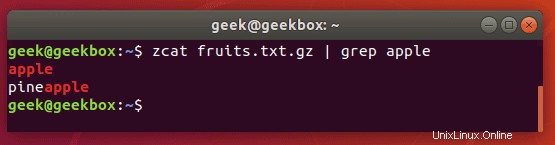
Grep gz soubory bez rozbalení
Jak jsme si ukázali dříve, můžete použít příkaz zgrep k prohledávání komprimovaných souborů, aniž byste je museli nejprve rozbalit.
$ zgrep word-to-search /path/to/file.gz
Můžete také použít příkaz zcat k zobrazení obsahu souboru gz a poté tento výstup přesměrovat do grep, aby se izolovaly řádky obsahující váš hledaný řetězec.
$ zcat file.gz | grep word-to-search
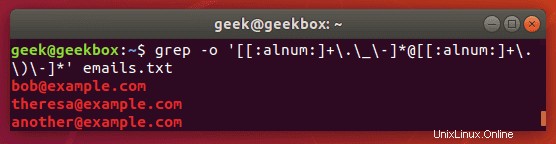
Grep e-mailové adresy ze souboru zip
Můžeme použít efektní regulární výraz k extrahování všech e-mailových adres ze souboru zip.
$ grep -o '[[:alnum:]+\.\_\-]*@[[:alnum:]+\.\_\-]*' emails.txt
Příznak -o extrahuje e-mailovou adresu pouze místo zobrazení celého řádku, který obsahuje e-mailovou adresu. Výsledkem je čistší výstup.
Stejně jako u většiny věcí v Linuxu existuje více než jeden způsob, jak to udělat. Můžete také použít egrep a jinou sadu výrazů. Ale výše uvedený příklad funguje dobře a je to docela jednoduchý způsob, jak extrahovat e-mailové adresy a ignorovat vše ostatní.
Grep IP adresy
Grep na IP adresy může být trochu složitější, protože nemůžeme jen říct grepu, aby hledal čtyři čísla oddělená tečkami – no, mohli bychom ale tento příkaz má také potenciál vrátit neplatné IP adresy.
Následující příkaz najde a izoluje pouze platné adresy IPv4:
$ grep -E -o "(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)" /var/log/auth.log
Použili jsme to na našem serveru Ubuntu, abychom viděli, odkud byly provedeny nejnovější pokusy o SSH.
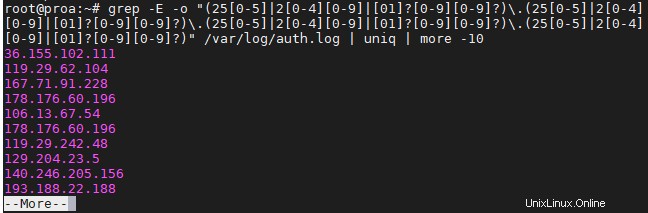
Chcete-li se vyhnout opakování informací a zabránit tomu, aby zaplavily vaši obrazovku, možná budete chtít své příkazy grep převést na „uniq“ a „more“, jak jsme to udělali na snímku obrazovky výše.
Grep nebo podmínka
Existuje několik různých způsobů, jak můžete použít podmínku nebo s grep, ale my vám ukážeme ten, který vyžaduje nejmenší počet úhozů a je nejsnáze zapamatovatelný:
$ grep -E 'string1|string2' filename
nebo technicky použití egrep znamená ještě méně stisknutí kláves:
$ egrep 'string1|string2' filename
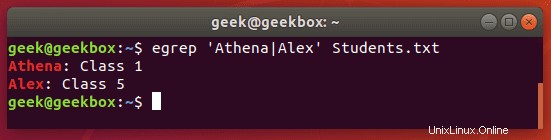
Ignorovat rozlišování malých a velkých písmen
Ve výchozím nastavení grep rozlišuje velká a malá písmena, což znamená, že ve vyhledávacím řetězci musíte být přesní. Tomu se můžete vyhnout, když řeknete grep, aby ignoroval malá a velká písmena pomocí přepínače -i.
$ grep -i string filename
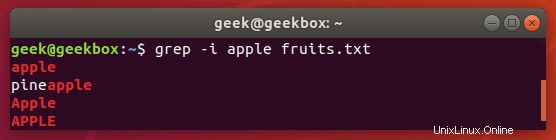
Vyhledávání s rozlišováním malých a velkých písmen
Co když chceme hledat řetězec, kde první může být velká nebo malá písmena, ale zbytek řetězce by měl být malá? Ignorování malých a velkých písmen pomocí přepínače -i v tomto případě nebude fungovat, takže jednoduchý způsob, jak to udělat, je pomocí závorek.
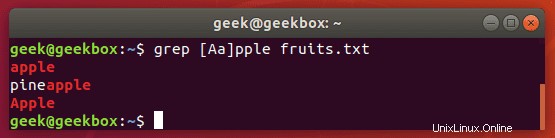
$ grep [Ss]tring filename
Tento příkaz říká grep, aby rozlišoval velká a malá písmena kromě prvního písmene.
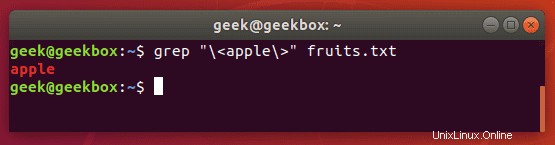
Přesná shoda grepu
V našich příkladech výše, kdykoli hledáme v dokumentu řetězec „jablko“, grep také vrátí „ananas“ jako součást výstupu. Chcete-li se tomu vyhnout a hledat striktně „jablko“, můžete použít tento příkaz:
$ grep "\<apple\>" fruits.txt
Můžete také použít přepínač -w, který grepu řekne, že řetězec musí odpovídat celému řádku. Je zřejmé, že to bude fungovat pouze v situacích, kdy neočekáváte, že zbytek řádku bude mít vůbec nějaký text.
Vyloučit vzor
Chcete-li zobrazit obsah souboru, ale vyloučit vzory z výstupu, můžete použít přepínač -v.
$ grep -v string-to-exclude filename
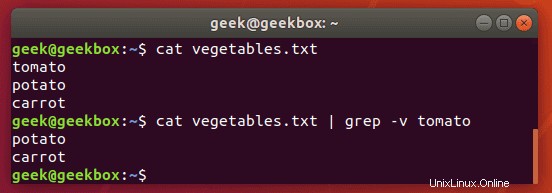
Jak můžete vidět na snímku obrazovky, řetězec, který jsme vyloučili, se již nezobrazuje, když spustíme stejný příkaz s přepínačem -v.
Grep and nahradit
K nahrazení všech instancí řetězce v souboru lze použít příkaz grep vedený do sed. Tento příkaz nahradí „řetězec1“ řetězcem „řetězec2“ ve všech souborech vzhledem k aktuálnímu pracovnímu adresáři:
$ grep -rl 'string1' ./ | xargs sed -i 's/string1/string2/g'
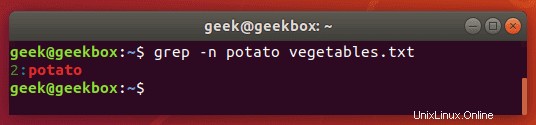
Grep s číslem řádku
Chcete-li zobrazit číslo řádku, který obsahuje váš řetězec, použijte přepínač -n:
$ grep -n string filename
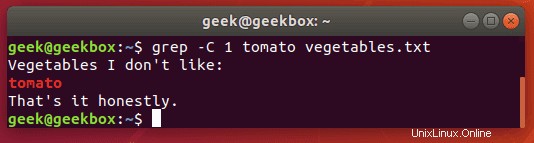
Zobrazit řádky před a za
Pokud potřebujete trochu více kontextu pro výstup grep, můžete zobrazit jeden řádek před a za zadaným vyhledávacím řetězcem pomocí přepínače -c:
$ grep -c 1 string filename
Zadejte počet řádků, které chcete zobrazit – v tomto příkladu jsme udělali pouze 1 řádek.
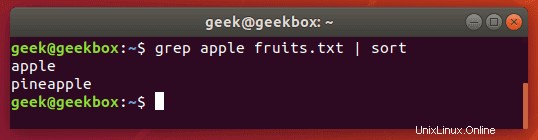
Seřaďte výsledek
Propojte výstup greps do příkazu sort, abyste seřadili výsledky v nějakém pořadí. Výchozí nastavení je abecední.
$ grep string filename | sort
Doufám, že vám bude návod užitečný. Vraťte se.