Scrapy je open source framework vyvinutý v Pythonu, který vám umožňuje vytvářet webové prohledávače nebo prohledávače pro rychlé a snadné získávání informací z webových stránek.
Tato příručka ukazuje, jak vytvořit a spustit webový pavouk pomocí Scrapy na vašem serveru pro extrahování informací z webových stránek pomocí různých technik.
Nejprve se připojte k serveru prostřednictvím připojení SSH. Pokud jste tak ještě neučinili, doporučujeme se podle našeho průvodce bezpečně připojit pomocí SSH. V případě lokálního serveru přejděte k dalšímu kroku a otevřete terminál svého serveru.
Vytvoření virtuálního prostředí
Před zahájením vlastní instalace pokračujte aktualizací systémových balíčků:
$ sudo apt-get updatePokračujte instalací některých závislostí nezbytných pro provoz:
$ sudo apt-get install python-dev python-pip libxml2-dev zlib1g-dev libxslt1-dev libffi-dev libssl-devPo dokončení instalace můžete začít konfigurovat virtualenv, balíček Pythonu, který vám umožní instalovat balíčky Pythonu izolovaným způsobem, aniž byste ohrozili ostatní software. Ačkoli je tento krok volitelný, vývojáři Scrapy velmi doporučují:
$ sudo pip install virtualenvPotom připravte adresář pro instalaci prostředí Scrapy:
$ sudo mkdir /var/scrapy
$ cd /var/scrapyA inicializujte virtuální prostředí:
$ sudo virtualenv /var/scrapy
New python executable in /var/scrapy/bin/python
Installing setuptools, pip, wheel...
done.Pro aktivaci virtuálního prostředí stačí spustit následující příkaz:
$ sudo source /var/scrapy/bin/activateMůžete kdykoli ukončit pomocí příkazu "deaktivovat".
Instalace Scrapy
Nyní nainstalujte Scrapy a vytvořte nový projekt:
$ sudo pip install Scrapy
$ sudo scrapy startproject example
$ cd exampleV nově vytvořeném adresáři projektu bude mít soubor následující strukturu:
example/
scrapy.cfg # configuration file
example/ # module of python project
__init__.py
items.py
middlewares.py
pipelines.py
settings.py # project settings
spiders/
__init__.pyPoužití shellu pro testovací účely
Scrapy vám umožňuje stahovat obsah HTML webových stránek a extrapolovat z nich informace pomocí různých technik, jako jsou selektory CSS. Pro usnadnění tohoto procesu poskytuje Scrapy „shell“, aby bylo možné testovat extrakci informací v reálném čase.
V tomto tutoriálu uvidíte, jak zachytit první příspěvek na hlavní stránce slavného sociálního Redditu:
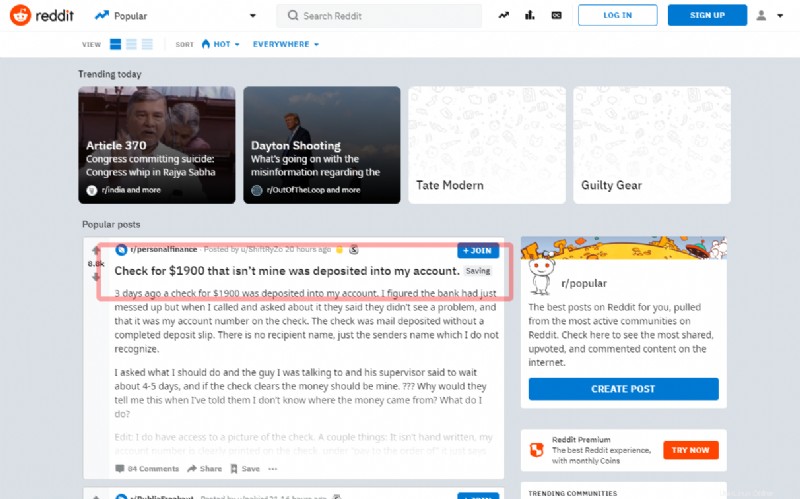
Než přejdete k zápisu zdroje, zkuste pomocí shellu extrahovat název:
$ sudo scrapy shell "reddit.com"Během několika sekund si Scrapy stáhne hlavní stránku. Zadávejte tedy příkazy pomocí objektu „response“. Jako v následujícím příkladu použijte selektor "článek h3 ::text":k získání názvu prvního příspěvku
>>> response.css('article h3::text')[0].get()Pokud volič funguje správně, zobrazí se název. Poté opusťte shell:
>>> exit()Chcete-li vytvořit nového pavouka, vytvořte nový soubor Python v adresáři projektu příklad / spiders / reddit.py:
import scrapy
class RedditSpider(scrapy.Spider):
name = "reddit"
def start_requests(self):
yield scrapy.Request(url="https://www.reddit.com/", callback=self.parseHome)
def parseHome(self, response):
headline = response.css('article h3::text')[0].get()
with open( 'popular.list', 'ab' ) as popular_file:
popular_file.write( headline + "\n" )Všichni pavouci zdědí třídu Spider modulu Scrapy a spouštějí požadavky pomocí metody start_requests:
yield scrapy.Request(url="https://www.reddit.com/", callback=self.parseHome)Když Scrapy dokončí načítání stránky, zavolá funkci zpětného volání (self.parseHome).
Máte-li objekt odpovědi, můžete obsah, který vás zajímá, převzít:
headline = response.css('article h3::text')[0].get()A pro demonstrační účely jej uložte do souboru "popular.list".
Spusťte nově vytvořeného pavouka pomocí příkazu:
$ sudo scrapy crawl redditPo dokončení bude poslední extrahovaný titul nalezen v souboru popular.list:
$ cat popular.listPlánování Scrapyd
Chcete-li naplánovat spouštění svých pavouků, použijte službu nabízenou Scrapy „Scrapy Cloud“ (viz https://scrapinghub.com/scrapy-cloud ) nebo nainstalujte démona s otevřeným zdrojovým kódem přímo na váš server .
Ujistěte se, že jste v dříve vytvořeném virtuálním prostředí a nainstalujte balíček scrapyd přes pip:
$ cd /var/scrapy/
$ sudo source /var/scrapy/bin/activate
$ sudo pip install scrapydPo dokončení instalace připravte službu vytvořením souboru /etc/systemd/system/scrapyd.service s následujícím obsahem:
[Unit]
Description=Scrapy Daemon
[Service]
ExecStart=/var/scrapy/bin/scrapydUložte nově vytvořený soubor a spusťte službu přes:
$ sudo systemctl start scrapydNyní je démon nakonfigurován a připraven přijímat nové pavouky.
Chcete-li nasadit svůj vzorový pavouk, musíte použít nástroj nazvaný „scrapyd-client“, který poskytuje Scrapy. Pokračujte v jeho instalaci přes pip:
$ sudo pip install scrapyd-clientPokračujte úpravou souboru scrapy.cfg a nastavením dat nasazení:
[settings]
default = example.settings
[deploy]
url = http://localhost:6800/
project = exampleNyní nasaďte jednoduchým spuštěním příkazu:
$ sudo scrapyd-deployChcete-li naplánovat spuštění pavouka, stačí zavolat scrapyd API:
$ sudo curl http://localhost:6800/schedule.json -d project=example -d spider=reddit