Data mining je proces analýzy velkého množství dat za účelem získání užitečných informací. Má neuvěřitelně rozmanité aplikace v oblasti akademického výzkumu a obchodu. Výzkumníci využívají dolování dat k odvození nových řešení problémů výpočetního výzkumu, zatímco korporace na něm závisí, aby získaly převahu v obchodních příjmech. Společnosti jako Amazon využívají různé techniky dolování dat ke zlepšení svého nástroje pro doporučení produktů, zatímco vyhledávací giganti jako Google a Microsoft je využívají k efektivnímu hodnocení výsledků svých vyhledávačů. Díky rostoucí poptávce po Data Science obecně bylo v posledních desetiletích dodáno velké množství robustního softwaru pro dolování dat pro Linux. Zůstaňte s námi, abyste se dozvěděli více o 20 nejlepších linuxových softwarech pro dolování dat.
Software pro dolování dat s bohatými funkcemi
Data mining pokrývá mnoho témat Data Science, včetně sběru dat, statistické analýzy, konceptů umělé inteligence a samozřejmě – programování. Díky své masivní doméně přicházejí nástroje pro dolování dat v různých variantách, vyvinuté pro provádění různých věcí. Naši odborníci proto vybrali všestrannou řadu softwaru pro dolování dat pro Linux, který při kreativním použití dokáže dokonale vyhovět požadavkům moderních datových inženýrů.
1. Rapid Miner
Rapid Miner, vrchol moderního linuxového softwaru pro dolování dat, je mnohem vyšší než ostatní, kdykoli jde o spolehlivé platformy pro dolování dat. Dříve známá jako YALE je výkonná a flexibilní sada pro dolování dat s velkým množstvím robustních funkcí, které posouvají vaše těžební dovednosti na další úroveň. Rapid Miner je vyvinut nad programovacím jazykem Java a dělá přesně to, co jeho název napovídá – upevňuje vaše projekty dolování dat.
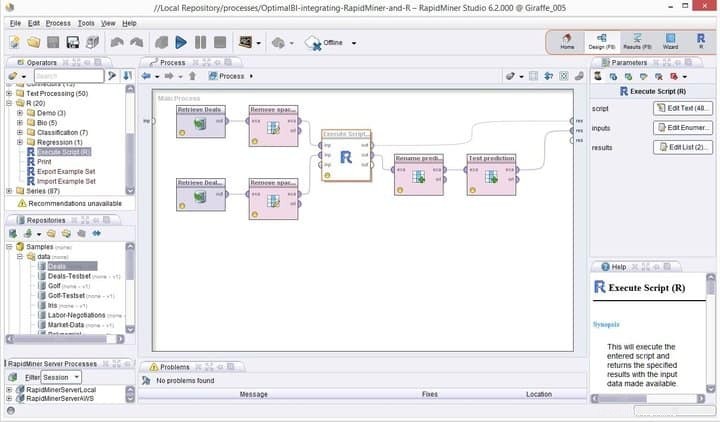
Funkce Rapid Miner
- Rapid Miner přichází s minimálním, ale intuitivním rozhraním GUI s další verzí příkazového řádku pro terminálové geeky.
- Toto robustní a flexibilní vizuální prostředí pro prediktivní analýzu umožňuje uživatelům analyzovat velká data bez explicitního programování.
- K dispozici je obrovský seznam flexibilních rozšíření, která umožňují další funkce z toho, co získáte při první instalaci.
- Tento výkonný software pro dolování dat pro Linux můžete velmi snadno integrovat do přizpůsobených projektů dolování dat.
2. R
R může být známé jméno pro absolventy CS s odpovídajícími znalostmi programování. Ale pro datového vědce má mnohem větší hodnotu. Stručně řečeno, R je kompletní prostředí pro statistickou analýzu dat a grafiky. Je to vysoce flexibilní platforma pro dolování dat, která nabízí výkonné analytické techniky, jako je modelování, statistické testy, analýza časových řad, klasifikace, shlukování a mnoho dalších. Pokud jste profesionál s vynikajícími programovacími schopnostmi, R se může ukázat jako nejlepší zbraň ve vašem arzenálu.
Funkce R
- R nabízí robustní a efektivní řešení pro ukládání a manipulaci s velkým množstvím podnikových dat.
- Spousta vestavěných a ucelených nástrojů pro analýzu dat zajišťuje, že inženýři mohou využít R pro širokou škálu projektů dolování dat.
- Je snadné ladit problémy ve stávajících projektech dolování dat díky robustním schopnostem R při přehrávání chyb.
- R je široce používán pro rozsáhlé projekty dolování dat a obsahuje obrovský seznam předem vytvořených řešení nadšenci pro open source.
3. Oranžová
Pokud jste datový vědec se zkušenostmi v CS, možná už znáte Orange. Vy ostatní si to představte jako robustní software pro dolování dat pro Linux postavený na Pythonu. Obecně platí, že Orange nabízí flexibilní a přínosnou sadu knihoven Python, které jsou schopné pracovat s moderními technikami dolování dat, jako je klasifikace, modelování, regrese, shlukování spolu s nástroji pro vizualizaci dat a předzpracování.
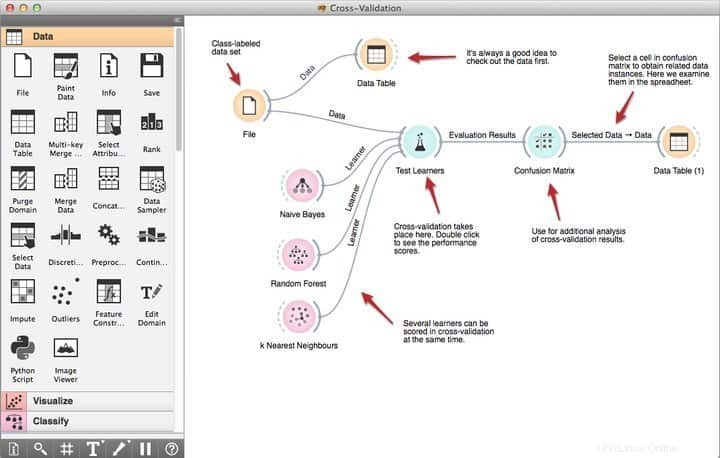
Funkce Orange
- Jeho výkonný vizuální programovací nástroj s názvem Orange Canvas umožňuje začátečníkům vytvářet rychlá řešení pro dolování dat pomocí jeho funkcí produktivní správy pracovních toků.
- Dodává se s robustní sadou prémiových vizualizačních nástrojů pro rozhodovací stromy, podmnožinu atributů, ukládání do sáčků, posílení a mnoho dalších.
- Podle jejich požadavků spadá Orange pod licenci GNU GPL, což umožňuje programátorům upravovat nebo přizpůsobovat tento bezplatný software pro dolování dat.
- Oranžovou si můžete vybrat hned teď a integrovat ji se svými stávajícími projekty dolování dat, abyste získali další možnosti, včetně více než 100 předpřipravených widgetů.
4. MOA
MOA, zkratka pro Massive Online Analysis, dělá přesně to, co říká její název. Jedná se o inovativní software pro dolování dat pro Linux s primárním důrazem na dolování velkých datových toků. MOA si klade za cíl vybavit začínající datové vědce výkonnou, ale flexibilní platformu pro dolování dat, která jim umožní efektivně testovat různé algoritmy dolování dat na neustále se vyvíjejících datových tocích. MOA přichází s robustní sbírkou standardních metod strojového učení, včetně klasifikace, regrese, shlukování, detekce odlehlých hodnot a systémů doporučení.
Funkce MOA
- MOA nabízí tři různé možnosti rozhraní, včetně rozhraní GUI, rozhraní založeného na konzole a flexibilního rozhraní API založeného na jazyce Java pro online integraci.
- Zahrnuje flexibilní algoritmy detekce změn, aby bylo možné zjistit co nejvíce informací z datových toků v reálném čase.
- Tento software pro dolování dat s otevřeným zdrojovým kódem je vhodný pro ty, kteří chtějí pro své procesy těžby využívat data v reálném čase.
- MOA obsahuje open source licenci GNU GPL, a proto nevyžaduje žádné právní formality pro přizpůsobení nebo úpravy.
5. ROOT
Můžete se spolehnout na platformu pro dolování dat vyvinutou CERNem, že? ROOT je nesmírně výkonný linuxový software pro dolování dat pro řešení skutečných výzev zahrnujících obrovské množství fyzikálních dat s vysokou energií. Brzy si získal oblibu mezi datovými vědci pracujícími v různých oblastech a v současnosti se široce používá pro dolování dat a analýzu astronomických dat. Pokud jste absolventem vědy s hlubokým zájmem o částicovou fyziku, toto je skutečná platforma pro vás.
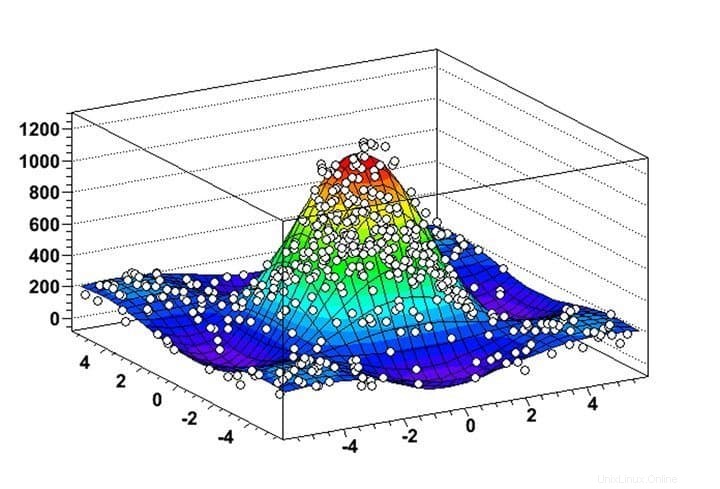
Funkce ROOT
- ROOT umožňuje nesmírně užitečnou vizualizaci distribuce dat a těžebních algoritmů prostřednictvím vysoce flexibilních funkcí histogramu a grafů.
- V tomto softwaru pro dolování dat pro Linux můžete analyzovat 2D objekty, jako jsou čáry, polygony, šipky, grafy a histogramy, spolu s 3D grafickými objekty.
- ROOT poskytuje několik čtyřvektorových výpočetních nástrojů a možností manipulace s obrázky pro praktickou analýzu datových sad v reálném světě.
- Software je primárně napsán v C++, ale využívá Python a R k maximalizaci funkcí dolování dat.
6. DataMelt
DataMelt, jeden z nejlepších softwaru pro dolování dat v Linuxu pro výzkumníky i inženýry, nabízí komplexní sadu výkonných, ale flexibilních funkcí pro analýzu velkých datových sad. Je to pravděpodobně jedna z nejpohodlnějších platforem pro dolování dat pro začátečníky, kteří se těší na posílení své kariéry v oblasti datové vědy. Tento tajemný software pro dolování dat, dříve známý jako SCaVis, spojuje obrovské softwarové balíčky s otevřeným zdrojovým kódem do koherentního rozhraní.
Funkce DataMelt
- DataMelt implementuje značné množství svých nástrojů pro manipulaci s daty a vykreslování v Javě a pro účely skriptování využívá Jython.
- Výkonná makra Pythonu byla použita k tomu, aby umožnila datovým vědcům vizualizovat reálná data, histogramy a 3D struktury.
- Vestavěné integrované vývojové prostředí (IDE) využívá flexibilní knihovny JAIDA FreeHEP a umožňuje zvýrazňování syntaxe, dokončování kódu, analyzátor programů a prostředí Jython.
- Licencování tohoto softwaru pro dolování dat s otevřeným zdrojovým kódem pro Linux umožňuje vědcům dat rozšiřovat software podle potřeby.
7. Chrastití
Rattle (analytický nástroj R Analytic Tool To Learn Easily) je bezplatný software pro dolování dat, který poskytuje výkonné rozhraní pro funkce dolování dat a binární klasifikace R. Poskytuje také praktickou sadu business intelligence známou jako RStat pro korporace a profesionály v oblasti datových vědců. Rattle umožňuje uživatelům importovat datové sady ze souborů CSV nebo ODBC a prozkoumat je za účelem modelování jejich řešení pro dolování dat.
Funkce Rattle
- Rattle umožňuje vědcům zabývajícím se daty vyvíjet a analyzovat komplexní datové modely a exportovat je buď jako PMML (predictive modeling markup language) nebo jako skóre.
- Je to plnohodnotný linuxový software pro dolování dat, který mohou korporace, vlády a výzkumné instituce snadno použít pro rozsáhlé dolování dat.
- Data lze načítat z velkého množství zdrojů, včetně souborů CSV, TXT, Excel, ARFF, ODBC a RData, plus korpus a skripty.
- Mezi techniky strojového učení, které tato platforma pro dolování dat nabízí, patří rozhodovací stromy, náhodné lesy, podpůrné vektorové stroje, logistická regrese, neuronová síť a další.
8. ELKI
ELKI je nesmírně výkonný linuxový software pro dolování dat napsaný v programovacím jazyce Java. Jeho cílem je zpřístupnit dolování dat lidem, kteří nejsou držiteli profesionálních certifikací pro datovou vědu. Je to jedna z nejpoužívanějších platforem pro dolování dat ve výzkumných a výukových nadacích díky své působivé sbírce robustních funkcí dolování dat. ELKI přichází s vestavěnou podporou pro téměř každý oblíbený algoritmus dolování dat, včetně shlukování, klasifikace, správy databázových indexů a detekce odlehlých hodnot.
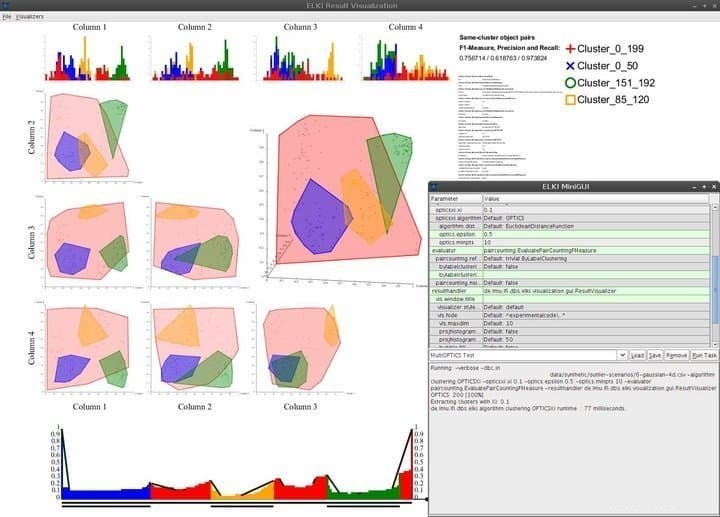
Funkce ELKI
- ELKI přichází s minimálním, ale elegantním uživatelským rozhraním, které poskytuje téměř potřebné navigační schopnosti.
- Schopnosti vizualizace zahrnují, ale nejsou omezeny na histogramy, ROC křivky, OPTICKÉ grafy, paralelní souřadnice, Voronoiovy buňky, tvary alfa a další.
- ELKI využívá několik strategií rozdělení R-stromu a hromadného načítání pro efektivní strukturování indexů.
- Tento software pro dolování dat pro Linux umožňuje vědcům zkoumat a vyhodnocovat geografická data pomocí robustních funkcí detekce prostorových odlehlých hodnot.
9. KNIME
KNIME je pravděpodobně jedním z nejinovativnějších open source softwaru pro dolování dat, který jsme mohli získat. Poskytuje velmi komplexní a flexibilní platformu pro dolování dat, která se může pochlubit koherentními funkcemi pro integraci dat, zpracování, analýzu, reportování a vyhodnocování. KNIME umožňuje vytváření vizuálních pracovních toků nazývaných pipelines, které umožňují datovým vědcům zkoumat komplexní datové sady v reálném čase. Samotný software je vysoce škálovatelný a lze jej bez jakýchkoli překážek integrovat do budoucích projektů.
Funkce KNIME
- Rozhraní GUI tohoto bezplatného softwaru pro dolování dat je velmi intuitivní a zahrnuje specifické navigační schopnosti požadované v moderním dolování dat.
- KNIME stojí na vrcholu interaktivního vývojového prostředí Eclipse a využívá jeho robustní rozhraní API k poskytování rozšiřitelnosti nadšencům do open source.
- Je dodáváno praktické uživatelské rozhraní založené na konzoli, které umožňuje dávkové spouštění prostřednictvím automatických skriptů.
- KNIME podporuje širokou škálu technik dolování dat, včetně shlukování, indukce pravidel, asociačních pravidel, bayesovských sítí, neuronových sítí a mnoha dalších.
10. Weka
Weka, zkratka pro Waikato Environment for Knowledge Analysis, je působivý software pro dolování dat pro Linux. Nabízí rozsáhlou sadu softwaru pro strojové učení napsaného v Javě, včetně algoritmů pro konvenční techniky dolování dat, jako jsou rozhodovací stromy, podpůrné vektorové stroje, klasifikátory založené na instancích, shlukování, Bayesovy sítě, neuronové sítě a mnoho dalších. Weka přichází s možnostmi obousměrné integrace s MOA, a proto může být hojně využívána v oblastech, kde je zpracování datových toků v reálném čase povinné.
Funkce Weka
- Výkonná vizualizace dat a schopnosti zpracování dat společnosti Weka činí vyhodnocování rozsáhlých datových sad mnohem jednodušší než většina bezplatného softwaru pro dolování dat.
- Vestavěné grafické uživatelské rozhraní (GUI) je velmi intuitivní a umožňuje relativně pohodlné použití algoritmů strojového učení.
- Flexibilní rozhraní API umožňuje zcela bezproblémové vkládání Weka do stávajících nebo budoucích projektů dolování dat.
- Weka’s robust environment allows rewarding data preprocessing abilities to make the most out of industrial or research data.
11. KEEL
KEEL stands for Knowledge Extraction based on Evolutionary Learning, and as the name implies, it is a Linux data mining software for assessing evolutionary algorithms. It is a powerful data mining platform that provides advanced functionalities to help engineers bring new data mining solutions while providing researchers with a mesmerizing platform for scientific undertakings. KEEL is written using the powerful interpreted programming language Java and ships with an open-source GNU GPL license.
Features of KEEL
- The user interface of KEEL is simple in visual, yet it provides all the navigational power required to manage the software effectively.
- It comes with a pre-built set of extensive evolutionary algorithms to predict models, preprocessing methods, and postprocessing procedures.
- KEEL offers over 100 different algorithms for data transformation, discretization, feature selection, noise filtering, and many more.
- It’s among those few data mining software for Linux that comes with extremely accurate data reduction methodologies, alongside functions for extracting rules based on patterns.
12. Apache Mahout
Apache Mahout is one of the most used data mining platforms by professional data scientists due to its substantial empowering features. It is primarily an open source collection of frequently used machine learning techniques and their implementations to help cluster, classify, and frequent pattern recognition in large-scale datasets. Many notable tech giants leverage Apache Mahout for real-time data mining, including Adobe, AOL, Drupal, and Twitter, due to the flexibility it offers.
Features of Apache Mahout
- This data mining software for Linux integrates to the Apache Hadoop stack very well, thus offering an excellent platform for people looking for distributed data mining solutions.
- Data scientists can leverage Mahout on top of Apache Spark as the back-end for implementing flexible and highly scalable data mining projects.
- Mahout comes with native support for CPU/GPU/CUDA acceleration, thus allowing you to leverage the maximum processing power you could get.
13. Sisense
Sisense is arguably among the best data mining software for Linux beginners. It provides data scientists with the specific features they require for diving into massive datasets and discover crucial insights like customer’s shopping habits, search rankings, and other business analytics. Sisense offers a compelling dashboard, making it reasonably straightforward to explore and visualize large amounts of unprocessed data. If you’re coming into data mining from a non-technical background, Sisense might be the best data mining platform for you.
Features of Sisense
- Sisense allows data science professionals to connect with any number of data sources – both structured and unstructured.
- The user interface is very intuitive, and the dashboard provides a highly interactive workflow for visualizing large-scale disparate data sources.
- Sisense can be readily employed in enterprises, government institutions, healthcare management, supply chains, manufacturing, and other types of corporations.
- Sisense allows for a handy drag-and-drop feature empowering data scientists in managing their projects with superior productivity.
14. Databionic
The Databionic ESOM tools offer a plethora of rewarding and flexible data mining techniques such as clustering, visualization, and classification with Emergent Self-Organizing Maps (ESOM) that enable data scientists to analyze large-scale data for business analytics. Developed in Germany, Databionic provides almost every necessary functionalities you’d look for in a modern-day Linux data mining software. It comes under a free and open source GNU GPL license and encourages professionals to tweak the software as they see fit.
Features of Databionic
- This data mining software for Linux is written using the Java programming language and offers maximum portability and extensibility.
- A compelling set of pre-built initialization methods and training algorithms are shipped with Databionic to ease your data mining projects.
- Databionic enables you to effectively visualize high-dimensional and disparate datasets with U-Matrix, P-Matrix, Component Planes, and SDH.
- Users can quickly build personalized ESOM classifiers for automating their data mining tasks with Databionic.
15. Anaconda
Anaconda is an extremely innovative, powerful, and open source data mining software powered by Python, the holy grail of data science programming languages. Industry leaders, including CISCO, Bloomberg, and BMW, utilize this awe-inspiring data mining platform to stay on top of their fellow competitors and curate new analytics solutions. Anaconda is often a mandatory requirement for companies hiring data scientists due to its extensive usage in the field.
Features of Anaconda
- Anaconda allows data scientists to harness the might of data science, machine learning, and AI – all from a single platform and deploy projects with a single click of the mouse.
- This free data mining software comes with an extensive set of pre-built data science packages for Python, R, and Scala.
- Anaconda ships with a BSD license, allowing developers to leverage it to build robust data mining solutions without any legal hassle.
- It is relatively simple to integrate this modern-day data mining software for Linux with other data science software in your arsenal.
16. Shogun
Shogun is, as the developers call it – a unified and efficient machine learning library aimed at solving real-world problems involving big data, and of course – data mining. It is one of the best data mining software for Linux that provides top-notch functionalities and makes sure they can be leveraged as the users want them to. If you’re looking for robust open source data mining software, Shogun might be the perfect tool for you.
Features of Shogun
- Shogun features an extensive range of data mining features, including but not limited to classification, regression, dimensionality reduction, support vector machines, and such.
- It offers a full-fledged implementation of powerful hidden Markov models for enhancing your data mining capabilities right out of the box.
- The user interface is fully hackable and can integrate with futuristic projects too well, thanks to its robust APIs.
- Shogun performs relatively much better than regular Linux data mining software, owing to its gratitude to C++.
17. GNU Octave
GNU Octave is an extremely powerful yet user-friendly scientific computing solution that features a robust high-level programming language similar to MATLAB in many ways. It has widespread usage in the areas of numerical computing and syncs perfectly with most MATLAB implementations. Data scientists can leverage this mesmerizing data science platform for analyzing diverse ranges of real-time data and dig out potentially rewarding insights from them.
Features of GNU Octave
- GNU Octave aims primarily at solving linear and nonlinear numerical problems and runs seamlessly on Linux, macOS, BSD, and Windows.
- The syntax of its high-level programming language is very identical to MATLAB and can operate on both vectors and matrices.
- The powerful mathematics-oriented data visualization capabilities of this Linux data mining software helps in analyzing large amounts of data without requiring external tools.
- The software comes with a GUI interface and a command-line variant for enhancing productivity to the highest level.
18. Apache UIMA
Apache UIMA is highly modular informatics management and analysis system that has gained immense popularity among data scientists due to its compelling data mining functionalities. UIMA stands for Unstructured Information Management Architecture and, as the name already suggests, is an analytic tool for exploring unstructured data. This data mining software for Linux provides a select set of flexible features to discover useful insights from large volumes of disparate data.
Features of Apache UIMA
- It is a Java-based data mining framework for analyzing and evaluating massive datasets involving real-time unstructured data.
- UIMA is hugely scalable and can be used as network services and processing pipelines.
- This Linux data mining software facilitates the analysis of multimedia contents such as audio and video data.
- The software suite comes under an Apache license and is thus free to use and modify by users.
19. Turi Create
Turi is arguably among the most excellent data mining software for Linux we’ve tested during our compilation of this guide. Known previously as Graphlab Create, Turi offers a plethora of robust data science functionalities to build highly modular, scalable data mining solutions. Turi boasts a wide range of diverse, high-performance, distributed computation features and can greatly simplify the development of custom data-mining programs.
Features of Turi Create
- This Linux data mining software is based on graphs and focuses more on tasks than algorithms.
- Although the software doesn’t require any external graphic processing unit (GPU), using one can significantly boost performance.
- Apart from standard text and image data, Turi has built-in support for audio, video, and sensor data.
- It is written using the C++ programming language and is one of the fastest data mining software we’ve tested.
20. ROSETTA
Marketed by the devs as a rough set toolkit for analysis of data, ROSETTA is a general-purpose tool for discernibility-based modeling, with very compelling use cases in the field of data mining. It is a powerful framework for analyzing tabular data and offers some very robust knowledge discovery functionalities. You can utilize ROSETTA in preprocessing large-scale datasets, computing attribute sets, generating rules, and many more.
Features of ROSETTA
- This data mining software for Linux comes with an incredibly intuitive GUI interface with very productive navigational abilities in place.
- Users can integrate this data mining platform with database management systems (DBMSs) via ODBC relatively easily.
- ROSETTA comes with in-built support for both unsupervised and supervised machine learning models.
- The robust set of advanced filtering methods make postprocessing reasonably simple.
Konec myšlenek
Due to its diverse application in real life, data mining software for Linux tends to vary in flavor and functionality. Some of the most popular data mining tools include Rapid Miner, R, Orange, ELKI, MOA, Weka, ROOT, and DataMelt. So, when selecting the right Linux data mining software, you’ve to choose programs that meet your requirements. Hopefully, we could provide you the essential insights on some of the most widely used data mining tools. You should now be able to select the one that does the job for you perfectly. Thanks for your patience, and don’t forget to check us out for regular posts on exciting Linux software and tutorials.