Aktualizovaná odpověď v roce 2020 :
Podle odpovědi @Owena ORC vyrostla a dospěla jako vlastní projekt Apache. Dokončený seznam uživatelů ORC ukazuje, jak rozšířené je nyní podporováno v mnoha různých technologiích velkých dat.
Díky @Owenovi a projektovému týmu ORC Apache, projektový web ORC má plně udržovanou aktuální dokumentaci o použití samostatného nástroje Java nebo C++ na souboru ORC uloženém v místním souborovém systému Linux. Což neslo pochodeň pro původní wiki stránku Hive+ORC Apache.
Původní odpověď ze dne:May 30 '14 at 16:27
Nástroj pro výpis souborů ORC je dodáván s podregistrem (0.11 nebo vyšší):
hive --orcfiledump <hdfs-location-of-orc-file>Zdrojový odkaz
Je také schopen vidět obsah souboru ORC pomocí desktopové aplikace běžící na Linuxu.
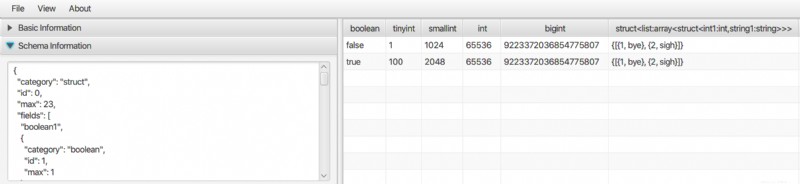
K dispozici je desktopová aplikace pro prohlížení parket a dalších dat v binárním formátu, jako je ORC a AVRO. Je to čistě Java aplikace, kterou lze spustit na Linuxu, Macu i Windows. Podrobnosti naleznete v prohlížeči souborů Bigdata.
Podporuje komplexní datový typ, jako je pole, mapa, struktura atd.
Nyní existuje také nativní spustitelný soubor pro Linux a MacOS, který tiskne obsah souboru orc v JSON. Podívejte se na projekt ORC (http://orc.apache.org/) a sestavte nástroje C++.
% orc-contents examples/TestOrcFile.test1.orc
K dispozici je také nativní nástroj metadat:
% orc-metadata ../examples/TestOrcFile.test1.orc
Projekt ORC má také samostatný uber jar, který umí totéž z Javy.
% java -jar orc-tools-1.2.3-uber.jar data myfile.orc