Chcete-li uspořádat data jako propojený seznam pomocí struct list_head musíte deklarovat kořen seznamu a deklarujte položku seznamu pro propojení. Jak kořenové, tak podřízené položky jsou stejného typu (struct list_head ). children záznam struct task_struct záznam je root . sibling záznam struct task_struct je list entry . Abyste viděli rozdíly, musíte si přečíst kód, kde children a sibling Jsou používány. Použití list_for_each pro children znamená to, co children je root . Použití list_entry pro sibling znamená to, co sibling je list entry .
Více o seznamech linuxových jader si můžete přečíst zde.
Otázka :Jaký je důvod, proč zde předáváme "sourozence", který nakonec obsahuje jiný seznam s jiným offsetem?
Odpověď:
Pokud byl seznam vytvořen tímto způsobem:
list_add(&subtask->sibling, ¤t->children);
Než
list_for_each(list, ¤t->children)
Inicializuje ukazatele seznamu na sibling , takže musíte použít subling jako parametr k list_entry. Tak jak linuxové jádro uvádí navržené API.
Ale pokud byl seznam vytvořen v jiném (špatně ) způsobem:
list_add(&subtask->children, ¤t->sibling);
Potom musíte tento seznam opakovat (špatně ) způsobem:
list_for_each(list, ¤t->sibling)
A nyní musíte použít children jako parametr pro list_entry .
Doufám, že to pomůže.
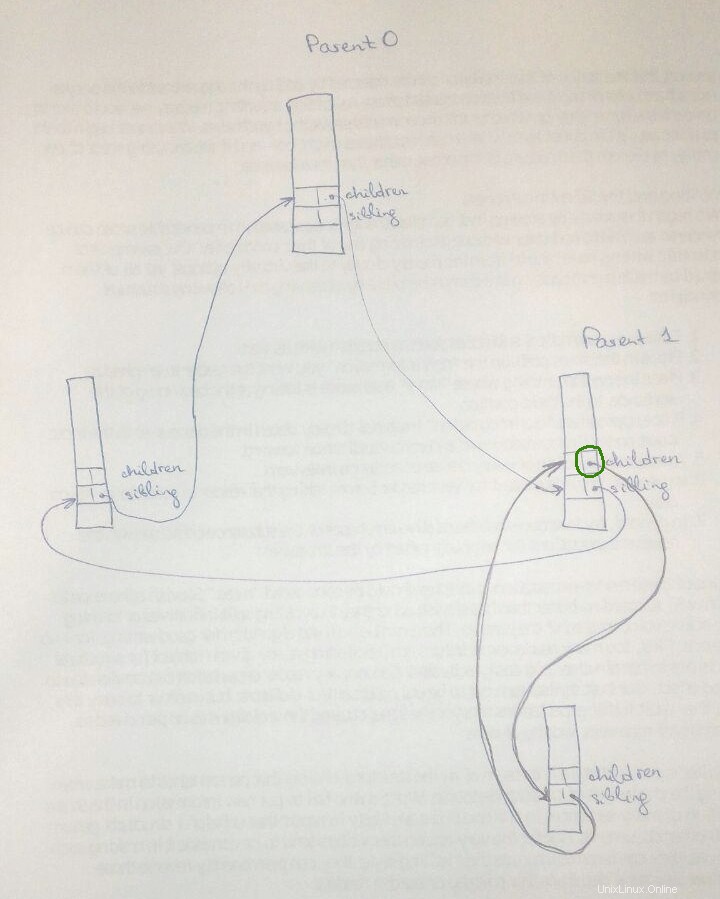
Následuje obrázkové znázornění, které může někomu v budoucnu pomoci. Horní pole představuje rodiče a dvě spodní pole jsou jeho děti

Zde je obrázek doplňující předchozí odpovědi. Stejným procesem může být rodič i dítě (jako Rodič1 na obrázku) a musíme tyto dvě role rozlišovat.
Intuitivně, pokud children z Parent0 by ukazovalo na children z Parent1, poté Parent0.children.next->next (zelený kroužek na obrázku), což je stejné jako Parent1.children.next , by ukazoval na potomka Parent1 namísto dalšího potomka Parent0.