Váš dotaz mě zaujal a nechal jsem se unést. Toto řešení vygeneruje pěkný PDF soubor s klikacím indexem a barevně zvýrazněným kódem. Najde všechny soubory v aktuálním adresáři a podadresářích a pro každý z nich vytvoří sekci v souboru PDF (viz poznámky níže, jak upřesnit příkaz find).
Vyžaduje, abyste měli nainstalované následující (pokyny k instalaci jsou pro systémy založené na Debianu, ale měly by být dostupné v repozitářích vaší distribuce):
-
pdflatex,coloralistingssudo apt-get install texlive-latex-extra latex-xcolor texlive-latex-recommendedTo by také mělo nainstalovat základní systém LaTeX, pokud jej nemáte.
Jakmile jsou nainstalovány, použijte tento skript k vytvoření dokumentu LaTeX se zdrojovým kódem. Trik spočívá v použití listings (část texlive-latex-recommended ) a color (instalováno latex-xcolor ) LaTeXové balíčky. \usepackage[..]{hyperref} je to, co dělá ze záznamů v obsahu klikací odkazy.
#!/usr/bin/env bash
tex_file=$(mktemp) ## Random temp file name
cat<<EOF >$tex_file ## Print the tex file header
\documentclass{article}
\usepackage{listings}
\usepackage[usenames,dvipsnames]{color} %% Allow color names
\lstdefinestyle{customasm}{
belowcaptionskip=1\baselineskip,
xleftmargin=\parindent,
language=C++, %% Change this to whatever you write in
breaklines=true, %% Wrap long lines
basicstyle=\footnotesize\ttfamily,
commentstyle=\itshape\color{Gray},
stringstyle=\color{Black},
keywordstyle=\bfseries\color{OliveGreen},
identifierstyle=\color{blue},
xleftmargin=-8em,
}
\usepackage[colorlinks=true,linkcolor=blue]{hyperref}
\begin{document}
\tableofcontents
EOF
find . -type f ! -regex ".*/\..*" ! -name ".*" ! -name "*~" ! -name 'src2pdf'|
sed 's/^\..//' | ## Change ./foo/bar.src to foo/bar.src
while read i; do ## Loop through each file
name=${i//_/\\_} ## escape underscores
echo "\newpage" >> $tex_file ## start each section on a new page
echo "\section{$i}" >> $tex_file ## Create a section for each filename
## This command will include the file in the PDF
echo "\lstinputlisting[style=customasm]{$i}" >>$tex_file
done &&
echo "\end{document}" >> $tex_file &&
pdflatex $tex_file -output-directory . &&
pdflatex $tex_file -output-directory . ## This needs to be run twice
## for the TOC to be generated
Spusťte skript v adresáři, který obsahuje zdrojové soubory
bash src2pdf
Tím se vytvoří soubor s názvem all.pdf v aktuálním adresáři. Zkusil jsem to s několika náhodnými zdrojovými soubory, které jsem našel ve svém systému (konkrétně dva soubory ze zdroje vlc-2.0.0 ) a toto je snímek obrazovky prvních dvou stránek výsledného PDF:
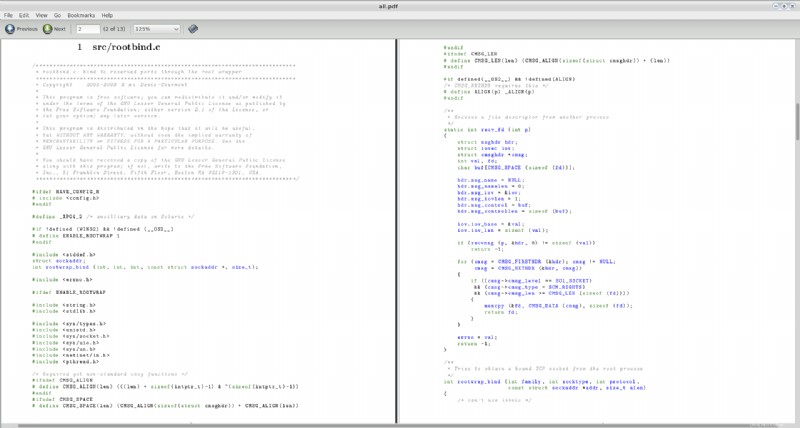
Pár komentářů:
- Skript nebude fungovat, pokud názvy souborů zdrojového kódu obsahují mezery. Protože mluvíme o zdrojovém kódu, budu předpokládat, že ne.
- Přidal jsem
! -name "*~"abyste se vyhnuli zálohování souborů. -
Doporučuji použít konkrétnější
findpříkaz k nalezení vašich souborů, jinak bude do PDF zahrnut jakýkoli náhodný soubor. Pokud všechny vaše soubory mají specifické přípony (.ca.hnapříklad), měli byste nahraditfindve skriptu s něčím takovýmfind . -name "*\.c" -o -name "\.h" | sed 's/^\..//' | - Pohrajte si s
listingsmožnosti, můžete to vyladit tak, aby to bylo přesně tak, jak chcete.
(ze StackOverflow)
for i in *.src; do echo "$i"; echo "---"; cat "$i"; echo ; done > result.txt
Výsledkem bude soubor result.txt obsahující:
- Název souboru
- oddělovač (---)
- Obsah souboru .src
- Opakujte shora, dokud nebudou všechny soubory *.src hotové
Pokud má váš zdrojový kód jinou příponu, změňte ji podle potřeby. Můžete také upravit bit echo a přidat potřebné informace (možná echo "filename $1" nebo změnit oddělovač nebo přidat oddělovač konce souboru).
odkaz má jiné metody, takže použijte kteroukoli metodu, která se vám nejvíce líbí. Tento považuji za nejflexibilnější, i když přichází s mírnou křivkou učení.
Kód poběží perfektně z bash terminálu (právě testován na VirtualBox Ubuntu)
Pokud vás nezajímá název souboru a zajímá vás pouze obsah sloučených souborů:
cat *.src > result.txt
bude fungovat naprosto dobře.
Další navrhovaná metoda byla:
grep "" *.src > result.txt
Což bude před každým řádkem uvádět název souboru, což může být pro některé lidi dobré, osobně to považuji za příliš mnoho informací, proto je mým prvním návrhem smyčka for výše.
Poděkování patří lidem na fóru StackOverflow.
EDIT:Právě jsem si uvědomil, že konečným výsledkem je konkrétně HTML nebo PDF, některá řešení, která jsem viděl, je vytisknout textový soubor do PostScriptu a poté převést postscript do PDF. Některý kód, který jsem viděl:
groff -Tps result.txt > res.ps
pak
ps2pdf res.ps res.pdf
(Vyžaduje, abyste měli ghostscript)
Doufám, že to pomůže.
Vím, že jdu pozdě, ale někomu, kdo hledá řešení, se to může hodit.
Na základě odpovědi @terdon jsem vytvořil skript BASH, který dělá tuto práci:https://github.com/eljuanchosf/source-code-to-pdf