Úvod
MySQL je populární open-source databázová aplikace, která ukládá a strukturuje data způsobem, který je smysluplný a snadno dostupný. U velkých aplikací může velké množství dat vést k problémům s výkonem.
Tato příručka poskytuje několik tipů pro ladění, jak zlepšit výkon databáze MySQL .

Předpoklady
- Systém Linux s nainstalovaným a spuštěným MySQL, Centos nebo Ubuntu
- Existující databáze
- Přihlašovací údaje správce pro operační systém a databázi
Ladění výkonu systému MySQL
Na systémové úrovni upravíte možnosti hardwaru a softwaru, abyste zlepšili výkon MySQL.
1. Vyvažte čtyři hlavní hardwarové zdroje

Úložiště
Udělejte si chvilku na vyhodnocení úložiště. Pokud používáte tradiční pevné disky (HDD), můžete pro zlepšení výkonu upgradovat na SSD (Solid State Drives).
Použijte nástroj jako iotop nebo sar ze sysstatu balíček pro sledování rychlosti vstupu/výstupu disku. Pokud je využití disku mnohem vyšší než využití jiných zdrojů, zvažte přidání dalšího úložiště nebo upgrade na rychlejší úložiště.
Procesor
Procesory jsou obvykle považovány za měřítko toho, jak rychlý je váš systém. Použijte Linux nahoře příkaz pro rozpis toho, jak jsou vaše zdroje využívány. Věnujte pozornost procesům MySQL a procentuálnímu využití procesoru, které vyžadují.
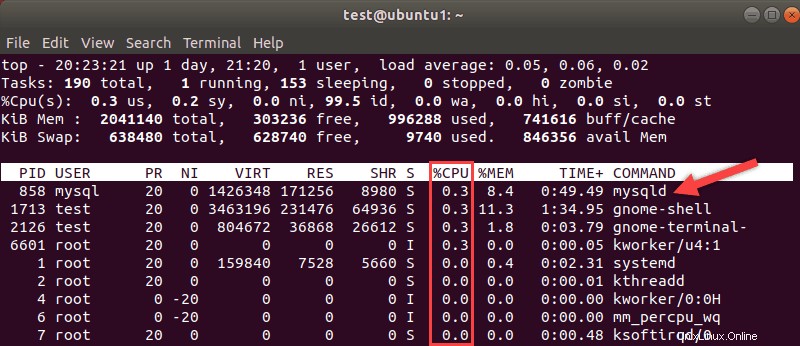
Upgrade procesorů je dražší, ale pokud je váš CPU úzkým hrdlem, může být upgrade nezbytný.
Paměť
Paměť představuje celkové množství paměti RAM na serveru úložiště databáze MySQL. Můžete upravit mezipaměť (více o tom později) a zlepšit výkon . Pokud nemáte dostatek paměti nebo pokud stávající paměť není optimalizována, můžete skončit poškozením svého výkonu namísto jeho zlepšení.
Stejně jako ostatní úzká místa, pokud vašemu serveru neustále dochází paměť, můžete upgradovat přidáním dalších. Pokud máte nedostatek paměti, váš server uloží do mezipaměti úložiště dat (jako pevný disk), aby fungoval jako paměť. Ukládání databáze do mezipaměti zpomaluje váš výkon.
Síť
Je důležité sledovat síťový provoz, abyste se ujistili, že máte dostatečnou infrastrukturu pro správu zátěže.
Přetížení sítě může vést k latenci, zahození paketů a dokonce k výpadkům serveru. Ujistěte se, že máte dostatečnou šířku pásma sítě pro pokrytí běžné úrovně databázového provozu.
2. Používejte InnoDB, nikoli MyISAM
MyISAM je starší databázový styl používaný pro některé databáze MySQL. Je to méně efektivní návrh databáze. Novější InnoDB podporuje pokročilejší funkce a má vestavěnou mechaniku optimalizace.
InnoDB používá seskupený index a uchovává data na stránkách, které jsou uloženy v po sobě jdoucích fyzických blocích. Pokud je hodnota pro stránku příliš velká, InnoDB ji přesune na jiné místo a poté hodnotu indexuje. Tato funkce pomáhá udržovat relevantní data na stejném místě na úložném zařízení, což znamená, že přístup k datům zabere fyzickému pevnému disku méně času.
3. Použijte nejnovější verzi MySQL
Použití nejnovější verze není vždy možné pro starší a starší databáze. Ale kdykoli je to možné, měli byste zkontrolovat používanou verzi MySQL a upgradovat na nejnovější.
Součástí pokračujícího vývoje je vylepšení výkonu. Některé běžné úpravy výkonu mohou být u novějších verzí MySQL zastaralé. Obecně je vždy lepší použít nativní vylepšení výkonu MySQL oproti skriptovacím a konfiguračním souborům.
Ladění výkonu softwaru MySQL
Ladění výkonu SQL je proces maximalizace rychlosti dotazů v relační databázi. Úkol obvykle zahrnuje více nástrojů a technik.
Tyto metody zahrnují:
- Vyladění konfiguračních souborů MySQL.
- Psaní efektivnějších databázových dotazů.
- Strukturování databáze pro efektivnější získávání dat.
4. Zvažte použití nástroje pro automatické zlepšování výkonu
Stejně jako u většiny softwaru ne všechny nástroje fungují na všech verzích MySQL. Prozkoumáme tři nástroje k vyhodnocení vaší databáze MySQL a doporučíme změny ke zlepšení výkonu.
První je tuning-primer. Tento nástroj je o něco starší, určený pro MySQL 5.5 – 5.7. Může analyzovat vaši databázi a navrhnout nastavení pro zlepšení výkonu. Může vám například navrhnout, abyste zvýšili query_cache_size Pokud se vám zdá, že váš systém nedokáže zpracovat dotazy dostatečně rychle, aby mezipaměť zůstala prázdná.
Druhým nástrojem pro ladění, užitečným pro většinu moderních databází SQL, je MySQLTuner. Tento skript (mysqltuner.pl ) je napsán v Perlu. Podobně jako tuning-primer analyzuje konfiguraci vaší databáze a hledá úzká hrdla a neefektivitu. Výstup zobrazuje metriky a doporučení:
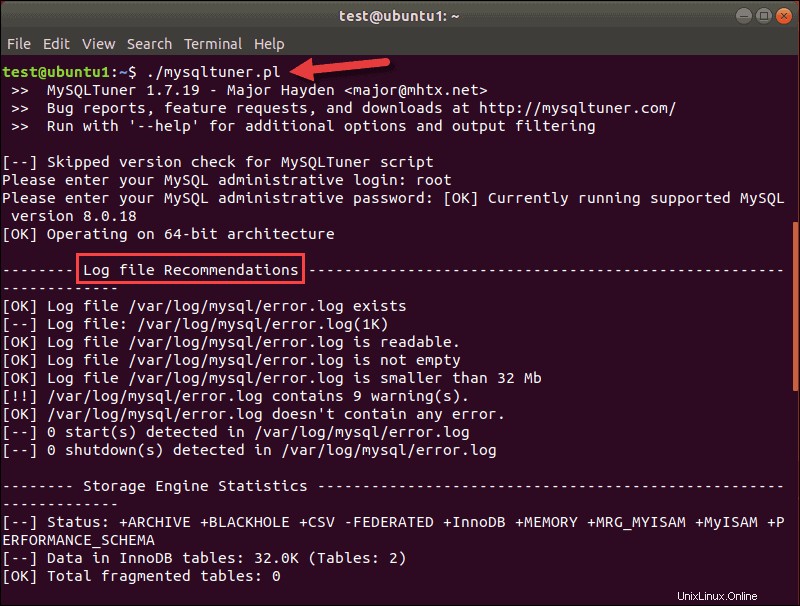
V horní části výstupu můžete vidět verzi nástroje MySQLTuner a vaši databázi.
Skript pracuje s MySQL 8.x. Doporučení souborů protokolu jsou na prvním místě v seznamu, ale pokud přejdete dolů, uvidíte obecná doporučení pro zlepšení výkonu MySQL.
Třetí nástroj, který již možná máte, je phpMyAdmin Advisor . Stejně jako další dva nástroje vyhodnotí vaši databázi a doporučí úpravy. Pokud již používáte phpMyAdmin, Advisor je užitečný nástroj, který můžete použít v GUI.
5. Optimalizovat dotazy
Dotaz je kódovaný požadavek na vyhledání dat v databázi, která odpovídají určité hodnotě. Existují některé operátory dotazů, jejichž spuštění ze své podstaty trvá dlouho. Techniky ladění výkonu SQL pomáhají optimalizovat dotazy pro lepší dobu běhu.
Detekce dotazů s nízkou dobou provádění je jedním z hlavních úkolů ladění výkonu. Běžně implementované dotazy na velké datové sady jsou pomalé a zabírají databáze. Tabulky proto nejsou dostupné pro žádné jiné úlohy.
Například databáze OLTP vyžaduje rychlé transakce a efektivní zpracování dotazů. Spuštění neefektivního dotazu blokuje použití databáze a zastavuje aktualizace informací.
Pokud vaše prostředí spoléhá na automatické dotazy, jako jsou spouštěče , mohou mít dopad na výkon. Zkontrolujte a ukončete procesy MySQL, které se mohou časem nahromadit.
6. Použijte indexy tam, kde je to vhodné
Mnoho databázových dotazů používá strukturu podobnou této:
SELECT … WHERETyto dotazy zahrnují vyhodnocování, filtrování a načítání výsledků. Můžete je restrukturalizovat přidáním malé sady indexů pro související tabulky. Dotaz může být nasměrován na index, aby se dotaz urychlil.
7. Funkce v predikátech
Vyhněte se použití funkce v predikátu dotazu. Například:
SELECT * FROM MYTABLE WHERE UPPER(COL1)='123'Copy
UPPER zápis vytvoří funkci, která musí fungovat během SELECT úkon. Tím se zdvojnásobí práce, kterou dotaz vykonává, a pokud je to možné, měli byste se tomu vyhnout.
8. Vyhněte se % zástupných znaků v predikátu
Při prohledávání textových dat pomáhají zástupné znaky širšímu vyhledávání. Chcete-li například vybrat všechna jména, která začínají ch , vytvořte index ve sloupci názvu a spusťte:
SELECT * FROM person WHERE name LIKE "ch%"Dotaz prohledá indexy, čímž sníží náklady na dotaz:

Hledání jmen pomocí zástupných znaků na začátku však výrazně zvyšuje náklady na dotaz, protože skenování indexování se nevztahuje na konce řetězců:
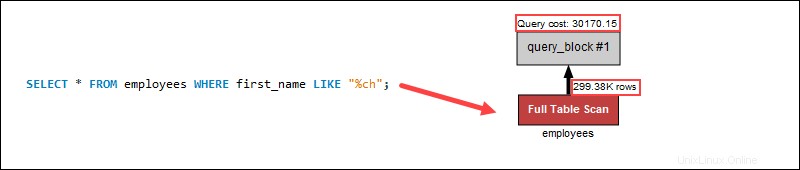
Zástupný znak na začátku vyhledávání neuplatňuje indexování. Místo toho úplné prohledání tabulky prohledává každý řádek jednotlivě, což zvyšuje náklady na dotaz v procesu. V příkladu dotazu použití zástupného znaku na konci pomáhá snížit náklady na dotaz, protože prochází méně řádků tabulky.
Způsob, jak hledat konce řetězců, je obrátit řetězec, indexovat obrácené řetězce a podívat se na počáteční znaky. Umístěním zástupného znaku na konec se nyní hledá začátek obráceného řetězce, což zefektivňuje vyhledávání.
9. Zadejte sloupce ve funkci SELECT
Běžně používaný výraz pro analytické a průzkumné dotazy je SELECT * . Výběr více, než potřebujete, vede ke zbytečné ztrátě výkonu a redundanci. Pokud určíte sloupce, které potřebujete, váš dotaz nebude muset prohledávat irelevantní sloupce.
Pokud jsou potřeba všechny sloupce, není jiný způsob, jak to udělat. Většina obchodních požadavků však nepotřebuje všechny sloupce dostupné v rámci datové sady. Zvažte místo toho výběr konkrétních sloupců.
Abych to shrnul, vyhněte se použití:
SELECT * FROM tableMísto toho zkuste:
SELECT column1, column2 FROM table10. Použijte ORDER BY Vhodně
ORDER BY výraz seřadí výsledky podle zadaného sloupce. Lze jej použít k řazení podle dvou sloupců najednou. Ty by měly být seřazeny ve stejném pořadí, vzestupně nebo sestupně.
Pokud se pokusíte seřadit různé sloupce v různém pořadí, zpomalí to výkon. Můžete to zkombinovat s indexem pro urychlení řazení.
11. GROUP BY Místo SELECT DISTINCT
Možnost SELECT DISTINCT dotaz se hodí, když se snažíte zbavit duplicitních hodnot. Tento příkaz však vyžaduje velké množství výpočetního výkonu.
Kdykoli je to možné, nepoužívejte SELECT DISTINCT , protože je velmi neefektivní a někdy matoucí. Pokud například tabulka uvádí informace o zákaznících s následující strukturou:
| id | jméno | příjmení | adresa | město | stát | zip |
|---|---|---|---|---|---|---|
| 0 | Jan | Smith | Květinová ulice 652 | Los Angeles | CA | 90017 |
| 1 | Jan | Smith | 1215 Ocean Boulevard | Los Angeles | CA | 90802 |
| 2 | Martha | Matthews | 3104 Pico Boulevard | Los Angeles | CA | 90019 |
| 3 | Martha | Jones | 2712 Venice Boulevard | Los Angeles | CA | 90019 |
Spuštění následujícího dotazu vrátí čtyři výsledky:
SELECT DISTINCT name, address FROM person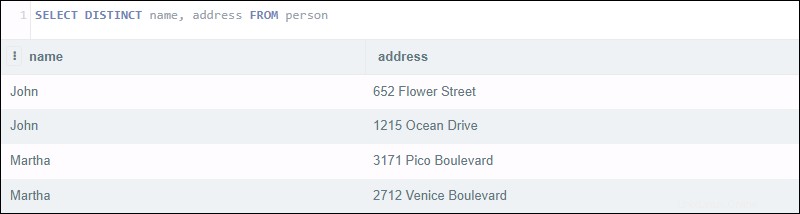
Zdá se, že příkaz by měl vrátit seznam odlišných jmen spolu s jejich adresou. Místo toho se dotaz podívá na obě sloupec jméno a adresa. Přestože existují dva páry zákazníků se stejným jménem, jejich adresy se liší.
Chcete-li odfiltrovat duplicitní jména a vrátit adresy, zkuste použít GROUP BY prohlášení:
SELECT name, address FROM person GROUP BY name
Výsledek vrátí první odlišný název spolu s adresou, takže prohlášení bude méně nejednoznačné. Chcete-li seskupit podle jedinečných adres, GROUP BY parametr by se pouze změnil na adresu a vrátil by stejný výsledek jako DISTINCT rychlejší výpis.
Abych to shrnul, vyhněte se použití:
SELECT DISTINCT column1, column2 FROM tableMísto toho zkuste použít:
SELECT column1, column2 FROM table GROUP BY column112. JOIN, WHERE, UNION, DISTINCT
Pokuste se použít vnitřní spojení, kdykoli je to možné. Vnější spojení se dívá na další data mimo zadané sloupce. To je v pořádku, pokud tato data potřebujete, ale zahrnout data, která nebudou vyžadována, je plýtvání výkonem.
Pomocí INNER JOIN je standardní přístup ke spojování stolů. Většina databázových strojů akceptuje použití WHERE také. Například následující dva dotazy vydávají stejný výsledek:
SELECT * FROM table1 INNER JOIN table2 ON table1.id = table2.idV porovnání s:
SELECT * FROM table1, table2 WHERE table1.id = table2.idTeoreticky mají také stejné runtime.
Volba, zda použít JOIN nebo WHERE dotaz závisí na databázovém stroji. Zatímco většina enginů má pro obě metody stejné runtime, v některých databázových systémech jedna běží rychleji než druhá.
UNION a DISTINCT příkazy jsou někdy součástí dotazů. Stejně jako vnější spojení je v pořádku použít tyto výrazy, pokud jsou nutné. Přidávají však další třídění a čtení databáze. Pokud je nepotřebujete, je lepší najít efektivnější výraz.
13. Použijte funkci EXPLAIN
Moderní databáze MySQL obsahují EXPLAIN funkce.
Přidání EXPLAIN výraz na začátek dotazu přečte a vyhodnotí dotaz. Pokud existují neefektivní výrazy nebo matoucí struktury, EXPLAIN vám je může pomoci najít. Poté můžete upravit frázování svého dotazu, abyste se vyhnuli neúmyslnému prohledávání tabulek nebo jiným zásahům do výkonu.
14. Konfigurace serveru MySQL
Tato konfigurace zahrnuje provedení změn ve vašem /etc/mysql/my.cnf soubor. Postupujte opatrně a provádějte drobné změny najednou.
query_cache_size – Určuje velikost mezipaměti dotazů MySQL čekajících na spuštění. Doporučení je začít s malými hodnotami kolem 10 MB a poté zvýšit na ne více než 100-200 MB. S příliš velkým počtem dotazů uložených v mezipaměti můžete zažít kaskádu dotazů „Čekání na zámek mezipaměti“. Pokud se vaše dotazy stále zálohují, je lepší použít EXPLAIN vyhodnotit každý dotaz a najít způsoby, jak je zefektivnit.
max_connection – Odkazuje na počet povolených připojení k databázi. Pokud se vám zobrazují chyby s odkazem na „Příliš mnoho připojení ” může pomoci zvýšení této hodnoty.
innodb_buffer_pool_size – Toto nastavení přiděluje systémovou paměť jako datovou mezipaměť pro vaši databázi. Pokud máte velké kusy dat, zvyšte tuto hodnotu. Všimněte si paměti RAM potřebné ke spuštění dalších systémových prostředků.
innodb_io_capacity – Tato proměnná nastavuje rychlost vstupu/výstupu z vašeho úložného zařízení. To přímo souvisí s typem a rychlostí vašeho úložného disku. HDD s 5400 otáčkami za minutu bude mít mnohem nižší kapacitu než high-end SSD nebo Intel Optane. Tuto hodnotu můžete upravit tak, aby lépe odpovídala vašemu hardwaru.