Úvod
Apache Hive je nástroj pro ukládání dat, který se používá k provádění dotazů a analýze strukturovaných dat v Apache Hadoop. Používá jazyk podobný SQL s názvem HiveQL.
V tomto článku se dozvíte, jak vytvořit tabulku v Hive a načíst data. Ukážeme vám také klíčové příkazy HiveQL pro zobrazení dat.

Předpoklady
- Systém se systémem Linux
- Uživatelský účet s sudo nebo root privilegia
- Přístup k oknu terminálu/příkazovému řádku
- Pracovní Hadoop instalace
- Pracovní Úl instalace
Vytvoření a načtení tabulky v Hive
Tabulka v Hive je sada dat, která používá schéma k řazení dat podle daných identifikátorů.
Obecná syntaxe pro vytvoření tabulky v Hive je:
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
(col_name data_type [COMMENT 'col_comment'],, ...)
[COMMENT 'table_comment']
[ROW FORMAT row_format]
[FIELDS TERMINATED BY char]
[STORED AS file_format];
Chcete-li vytvořit tabulku v Hive, postupujte podle následujících kroků.
Krok 1:Vytvořte databázi
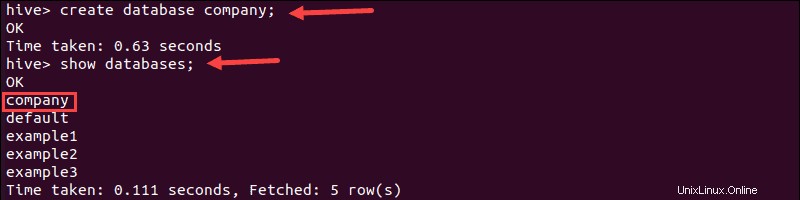
1. Spuštěním create vytvořte databázi s názvem „společnost“. příkaz:
create database company;Terminál vytiskne potvrzovací zprávu a čas potřebný k provedení akce.
2. Dále ověřte, zda je databáze vytvořena spuštěním show příkaz:
show databases;3. Najděte v seznamu databázi „společnosti“:
4. Otevřete „firemní“ databázi pomocí následujícího příkazu:
use company;
Krok 2:Vytvořte tabulku v Hive
„Firemní“ databáze po prvotním vytvoření neobsahuje žádné tabulky. Pojďme vytvořit tabulku, jejíž identifikátory budou odpovídat souboru .txt, ze kterého chcete přenést data.
1. Vytvořte soubor „employees.txt“ v /hdoop adresář. Soubor bude obsahovat údaje o zaměstnancích:

2. Uspořádejte data ze souboru „employees.txt“ do sloupců. Názvy sloupců v našem příkladu jsou:
- ID
- Jméno
- Země
- Oddělení
- Plat
3. Při vytváření tabulky používejte názvy sloupců. Vytvořte tabulku spuštěním následujícího příkazu:
create table employees (id int, name string, country string, department string, salary int)
4. Vytvořte logické schéma, které uspořádá data ze souboru .txt do odpovídajících sloupců. V souboru „employees.txt“ jsou data oddělena '-' . Chcete-li vytvořit typ logického schématu:
row format delimited fields terminated by '-';Terminál vytiskne potvrzovací zprávu:

5. Ověřte, zda je tabulka vytvořena spuštěním show příkaz:
show tables;
Krok 3:Načtení dat ze souboru
Vytvořili jste tabulku, ale ta je prázdná, protože nejsou načtena data ze souboru „employees.txt“ umístěného v /hdoop adresář.
1. Načtěte data spuštěním load příkaz:
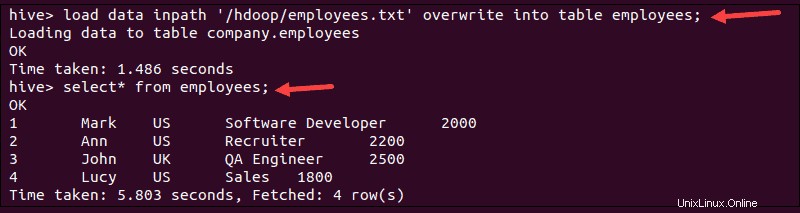
load data inpath '/hdoop/employees.txt' overwrite into table employees;
2. Ověřte, zda jsou data načtena spuštěním select příkaz:
select * from employees;Terminál vytiskne data importovaná ze souboru employees.txt soubor:
Zobrazit data podregistru
Pro zobrazení dat z tabulky máte několik možností. Pomocí následujících možností můžete efektivněji manipulovat s velkým množstvím dat.
Sloupce zobrazení
Zobrazte sloupce tabulky spuštěním desc příkaz:
desc employees;Výstup zobrazuje názvy a vlastnosti sloupců:

Zobrazit vybraná data
Předpokládejme, že chcete zobrazit zaměstnance a jejich země původu. Vyberte a zobrazte data spuštěním select příkaz:
select name,country from employees;Výstup obsahuje seznam zaměstnanců a jejich zemí:
