Apache Hadoop je open-source framework, který se používá ke správě, ukládání a zpracování dat pro různé velké datové aplikace běžící pod clusterovými systémy. Je napsán v Javě s nějakým nativním kódem v C a skriptech shellu. Využívá distribuovaný systém souborů (HDFS) a lze jej škálovat z jednotlivých serverů na tisíce počítačů.
Apache Hadoop je založen na čtyřech hlavních komponentách:
- Hadoop Common : Je to sbírka utilit a knihoven potřebných pro ostatní moduly Hadoop.
- HDFS: Také známý jako Hadoop Distributed File System distribuovaný mezi více uzly.
- MapReduce: Je to rámec používaný k psaní aplikací pro zpracování obrovského množství dat.
- Hadoop PŘÍZE: Také známý jako Yet Another Resource Negotiator je vrstva správy zdrojů Hadoopu.
V tomto tutoriálu vysvětlíme, jak nastavit cluster Hadoop s jedním uzlem na Ubuntu 20.04.
Předpoklady
- Server se systémem Ubuntu 20.04 se 4 GB RAM.
- Na vašem serveru je nakonfigurováno heslo uživatele root.
Aktualizujte systémové balíčky
Před spuštěním se doporučuje aktualizovat systémové balíčky na nejnovější verzi. Můžete to udělat pomocí následujícího příkazu:
apt-get update -y
apt-get upgrade -y
Jakmile je váš systém aktualizován, restartujte jej, aby se změny implementovaly.
Instalovat Javu
Apache Hadoop je aplikace založená na Javě. Budete tedy muset do svého systému nainstalovat Javu. Můžete jej nainstalovat pomocí následujícího příkazu:
apt-get install default-jdk default-jre -y
Po instalaci můžete ověřit nainstalovanou verzi Javy pomocí následujícího příkazu:
java -version
Měli byste získat následující výstup:
openjdk version "11.0.7" 2020-04-14 OpenJDK Runtime Environment (build 11.0.7+10-post-Ubuntu-3ubuntu1) OpenJDK 64-Bit Server VM (build 11.0.7+10-post-Ubuntu-3ubuntu1, mixed mode, sharing)
Vytvoření uživatele Hadoop a nastavení SSH bez hesla
Nejprve vytvořte nového uživatele s názvem hadoop pomocí následujícího příkazu:
adduser hadoop
Dále přidejte uživatele hadoop do skupiny sudo
usermod -aG sudo hadoop
Dále se přihlaste s uživatelem hadoop a vygenerujte pár klíčů SSH pomocí následujícího příkazu:
su - hadoop
ssh-keygen -t rsa
Měli byste získat následující výstup:
Generating public/private rsa key pair. Enter file in which to save the key (/home/hadoop/.ssh/id_rsa): Created directory '/home/hadoop/.ssh'. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/hadoop/.ssh/id_rsa Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub The key fingerprint is: SHA256:HG2K6x1aCGuJMqRKJb+GKIDRdKCd8LXnGsB7WSxApno [email protected] The key's randomart image is: +---[RSA 3072]----+ |..=.. | | O.+.o . | |oo*.o + . o | |o .o * o + | |o+E.= o S | |=.+o * o | |*.o.= o o | |=+ o.. + . | |o .. o . | +----[SHA256]-----+
Dále přidejte tento klíč do autorizovaných klíčů ssh a udělte správné oprávnění:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
Dále ověřte SSH bez hesla pomocí následujícího příkazu:
ssh localhost
Jakmile se přihlásíte bez hesla, můžete přejít k dalšímu kroku.
Instalovat Hadoop
Nejprve se přihlaste pomocí uživatele hadoop a stáhněte si nejnovější verzi Hadoop pomocí následujícího příkazu:
su - hadoop
wget https://downloads.apache.org/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz
Po dokončení stahování rozbalte stažený soubor pomocí následujícího příkazu:
tar -xvzf hadoop-3.2.1.tar.gz
Dále přesuňte extrahovaný adresář do /usr/local/:
sudo mv hadoop-3.2.1 /usr/local/hadoop
Dále vytvořte adresář pro uložení protokolu pomocí následujícího příkazu:
sudo mkdir /usr/local/hadoop/logs
Dále změňte vlastnictví adresáře hadoop na hadoop:
sudo chown -R hadoop:hadoop /usr/local/hadoop
Dále budete muset nakonfigurovat proměnné prostředí Hadoop. Můžete to udělat úpravou souboru ~/.bashrc:
nano ~/.bashrc
Přidejte následující řádky:
export HADOOP_HOME=/usr/local/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
Po dokončení uložte a zavřete soubor. Poté aktivujte proměnné prostředí pomocí následujícího příkazu:
source ~/.bashrc
Konfigurovat Hadoop
V této části se naučíme, jak nastavit Hadoop na jednom uzlu.
Konfigurace proměnných prostředí Java
Dále budete muset definovat proměnné prostředí Java v hadoop-env.sh pro konfiguraci nastavení projektu YARN, HDFS, MapReduce a Hadoop.
Nejprve vyhledejte správnou cestu Java pomocí následujícího příkazu:
which javac
Měli byste vidět následující výstup:
/usr/bin/javac
Dále vyhledejte adresář OpenJDK pomocí následujícího příkazu:
readlink -f /usr/bin/javac
Měli byste vidět následující výstup:
/usr/lib/jvm/java-11-openjdk-amd64/bin/javac
Dále upravte soubor hadoop-env.sh a definujte cestu Java:
sudo nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh
Přidejte následující řádky:
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64 export HADOOP_CLASSPATH+=" $HADOOP_HOME/lib/*.jar"
Dále si také budete muset stáhnout aktivační soubor Javax. Můžete si jej stáhnout pomocí následujícího příkazu:
cd /usr/local/hadoop/lib
sudo wget https://jcenter.bintray.com/javax/activation/javax.activation-api/1.2.0/javax.activation-api-1.2.0.jar
Nyní můžete ověřit verzi Hadoop pomocí následujícího příkazu:
hadoop version
Měli byste získat následující výstup:
Hadoop 3.2.1 Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r b3cbbb467e22ea829b3808f4b7b01d07e0bf3842 Compiled by rohithsharmaks on 2019-09-10T15:56Z Compiled with protoc 2.5.0 From source with checksum 776eaf9eee9c0ffc370bcbc1888737 This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-3.2.1.jar
Konfigurovat soubor core-site.xml
Dále budete muset zadat adresu URL pro váš NameNode. Můžete to udělat úpravou souboru core-site.xml:
sudo nano $HADOOP_HOME/etc/hadoop/core-site.xml
Přidejte následující řádky:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://0.0.0.0:9000</value>
<description>The default file system URI</description>
</property>
</configuration>
Po dokončení uložte a zavřete soubor:
Konfigurovat soubor hdfs-site.xml
Dále budete muset definovat umístění pro ukládání metadat uzlu, souboru fsimage a souboru protokolu úprav. Můžete to udělat úpravou souboru hdfs-site.xml. Nejprve vytvořte adresář pro ukládání metadat uzlu:
sudo mkdir -p /home/hadoop/hdfs/{namenode,datanode}
sudo chown -R hadoop:hadoop /home/hadoop/hdfs Dále upravte soubor hdfs-site.xml a definujte umístění adresáře:
sudo nano $HADOOP_HOME/etc/hadoop/hdfs-site.xml
Přidejte následující řádky:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hdfs/datanode</value>
</property>
</configuration>
Uložte a zavřete soubor.
Konfigurovat soubor mapred-site.xml
Dále budete muset definovat hodnoty MapReduce. Můžete jej definovat úpravou souboru mapred-site.xml:
sudo nano $HADOOP_HOME/etc/hadoop/mapred-site.xml
Přidejte následující řádky:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
Uložte a zavřete soubor.
Konfigurovat soubor yarn-site.xml
Dále budete muset upravit soubor yarn-site.xml a definovat nastavení související s YARN:
sudo nano $HADOOP_HOME/etc/hadoop/yarn-site.xml
Přidejte následující řádky:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
Po dokončení uložte a zavřete soubor.
Formátovat HDFS NameNode
Dále budete muset ověřit konfiguraci Hadoop a naformátovat HDFS NameNode.
Nejprve se přihlaste jako uživatel Hadoop a naformátujte HDFS NameNode pomocí následujícího příkazu:
su - hadoop
hdfs namenode -format
Měli byste získat následující výstup:
2020-06-07 11:35:57,691 INFO util.GSet: VM type = 64-bit 2020-06-07 11:35:57,692 INFO util.GSet: 0.25% max memory 1.9 GB = 5.0 MB 2020-06-07 11:35:57,692 INFO util.GSet: capacity = 2^19 = 524288 entries 2020-06-07 11:35:57,706 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets = 10 2020-06-07 11:35:57,706 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users = 10 2020-06-07 11:35:57,706 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes = 1,5,25 2020-06-07 11:35:57,710 INFO namenode.FSNamesystem: Retry cache on namenode is enabled 2020-06-07 11:35:57,710 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis 2020-06-07 11:35:57,712 INFO util.GSet: Computing capacity for map NameNodeRetryCache 2020-06-07 11:35:57,712 INFO util.GSet: VM type = 64-bit 2020-06-07 11:35:57,712 INFO util.GSet: 0.029999999329447746% max memory 1.9 GB = 611.9 KB 2020-06-07 11:35:57,712 INFO util.GSet: capacity = 2^16 = 65536 entries 2020-06-07 11:35:57,743 INFO namenode.FSImage: Allocated new BlockPoolId: BP-1242120599-69.87.216.36-1591529757733 2020-06-07 11:35:57,763 INFO common.Storage: Storage directory /home/hadoop/hdfs/namenode has been successfully formatted. 2020-06-07 11:35:57,817 INFO namenode.FSImageFormatProtobuf: Saving image file /home/hadoop/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 using no compression 2020-06-07 11:35:57,972 INFO namenode.FSImageFormatProtobuf: Image file /home/hadoop/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 of size 398 bytes saved in 0 seconds . 2020-06-07 11:35:57,987 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 2020-06-07 11:35:58,000 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid=0 when meet shutdown. 2020-06-07 11:35:58,003 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at ubuntu2004/69.87.216.36 ************************************************************/
Spustit cluster Hadoop
Nejprve spusťte NameNode a DataNode následujícím příkazem:
start-dfs.sh
Měli byste získat následující výstup:
Starting namenodes on [0.0.0.0] Starting datanodes Starting secondary namenodes [ubuntu2004]
Dále spusťte prostředek YARN a správce uzlů spuštěním následujícího příkazu:
start-yarn.sh
Měli byste získat následující výstup:
Starting resourcemanager Starting nodemanagers
Nyní je můžete ověřit pomocí následujícího příkazu:
jps
Měli byste získat následující výstup:
5047 NameNode 5850 Jps 5326 SecondaryNameNode 5151 DataNode
Přístup k webovému rozhraní Hadoop
Nyní můžete přistupovat k Hadoop NameNode pomocí adresy URL http://your-server-ip:9870. Měli byste vidět následující obrazovku:
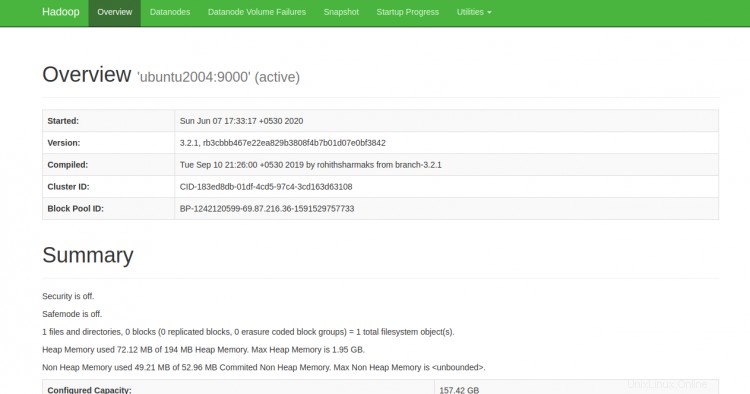
K jednotlivým DataNodes můžete také přistupovat pomocí adresy URL http://ip-ip-vašeho-serveru:9864. Měli byste vidět následující obrazovku:
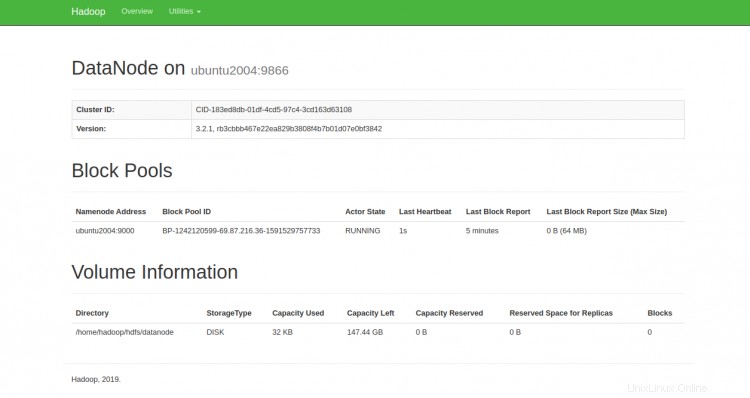
Pro přístup ke správci zdrojů YARN použijte adresu URL http://ip-ip-vašeho-serveru:8088. Měli byste vidět následující obrazovku:
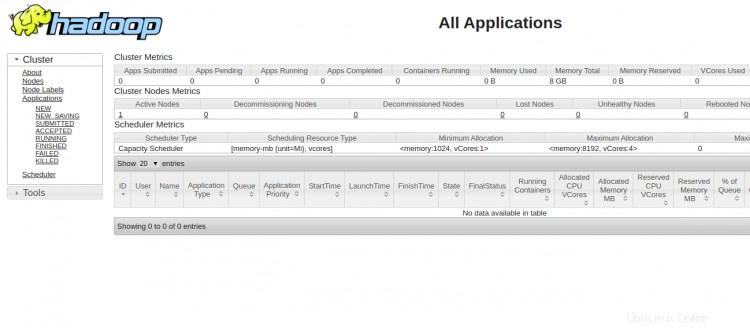
Závěr
Gratulujeme! úspěšně jste nainstalovali Hadoop na jeden uzel. Nyní můžete začít prozkoumávat základní příkazy HDFS a navrhovat plně distribuovaný cluster Hadoop. Neváhejte se mě zeptat, pokud máte nějaké otázky.