Pokud máte data, která nejsou vhodná pro relační databáze, je pravděpodobné, že hledáte řešení NoSQL. Možnosti NoSQL jsou rozmanité, Aerospike, MongoDB, Redis a mnoho dalších se snaží problém velkých dat vyřešit různými způsoby. V tomto článku se zaměříme na replikaci s cassandrou. Tato databáze ve skutečnosti dostala název z řecké mytologie, cassandra byla věštkyně, která vždy správně předpovídala budoucnost, ale všichni jí nevěřili. Tvůrci této databáze tedy předpovídají, že NoSQL v budoucnu nahradí relační databáze, ale neočekávají, že jim lidé z RDBMS uvěří.
Požadavky
Chcete-li postupovat podle tohoto článku, měli byste mít nastaveny 3 uzly jeden po druhém pomocí našeho předchozího průvodce nastavením cassandry. Měli byste mít všechny tři uzly v provozu a tři terminálová okna s relací ssh v každém z nich. Až to budete mít, začneme spojovat uzly Cassandra do jednoho shluku.
Vytvoření clusteru
Jste-li přihlášeni jako uživatel Cassandra, musíte upravit konfiguraci Cassandry v každém ze tří uzlů. Soubor se jmenuje cassandra.yaml
nano ~/conf/cassandra.yamlToto je třeba nakonfigurovat na všech 3 serverech. Řádek semen lze zadat na jeden server a poté zkopírovat, ale adresy IP každého serveru musí být zadány jako pravé.
cluster_name: 'Test Cluster'
seed_provider:
- class_name: org.apache.cassandra.locator.SimpleSeedProvider
parameters:
- seeds: "your-server-ip,your-server-ip-2,your-server-ip-3"
listen_address: your-server-ip
rpc_address: your-server-ipChcete-li nastavit entpoint snitch, vložte tuto jednolinku do všech tří uzlů:
sed -i 's/endpoint_snitch: SimpleSnitch/endpoint_snitch: GossipingPropertyFileSnitch/g' ~/conf/cassandra.yamlA použijte tento příkaz k připojení bootstrap řádku na konec souboru.
echo 'auto_bootstrap: false' >> ~/conf/cassandra.yamlSnitch, který jsme nastavili, má nekompatibilní název datového centra, dc1 místo datacenter1, takže to opravíme na všech třech uzlech:
sed -i 's/dc=dc1/dc=datacenter1/g' ~/conf/cassandra-rackdc.propertiesV případě potřeby restartujte všechny tři uzly a poté by stav sh bin/nodetool měl získat něco takového:
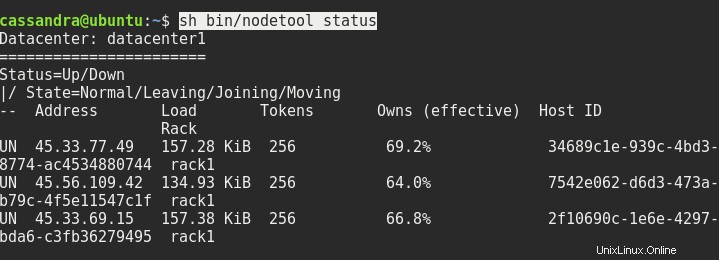
Další věc, kterou musíme udělat, je připojit se ke konzole z jednoho z uzlů do druhého uzlu. Po cqlsh musíme zadat adresu serveru a port 9042 takto:
cqlsh ip.addr.of.node 9042Místní přihlášení hostitele pouze pomocí cqlsh nebude fungovat.
Nastavení replikace
Pokud vás zajímá, proč jsme změnili výchozí konfiguraci snitch, teď to vysvětlím. Obecně existují dvě replikační strategie s Cassandrou. SimpleStrategy a NetworkTopologyStrategy. První používá výchozí snitch, druhý používá ty, které jsme nastavili. Tuto pokročilou strategii potřebujeme, pokud chceme mít snadné škálování clusteru. S touto strategií můžete přidat více uzlů v jiném datovém centru a rozšířit cluster po celém světě.
Takže uvnitř konzoly cqlsh musíme napsat toto:
CREATE KEYSPACE linoxide WITH replication = {'class': 'NetworkTopologyStrategy', 'datacenter1' : 3};Vytvoří nový klíčový prostor s názvem linoxide s replikací nastavenou pomocí NetworkTopologyStrategy a vytvoří 3 repliky v datovém centru1.
Dobře, uvidíme, co jsme vytvořili. Příkaz je tučně, výstup je zbytek.
SELECT * FROM system_schema.keyspaces;
keyspace_name | durable_writes | replication
--------------------+----------------+---------------------------------------------------------------------------------------
linoxide | True | {'class': 'org.apache.cassandra.locator.NetworkTopologyStrategy', 'datacenter1': '3'}
system_auth | True | {'class': 'org.apache.cassandra.locator.SimpleStrategy', 'replication_factor': '1'}
system_schema | True | {'class': 'org.apache.cassandra.locator.LocalStrategy'}
system_distributed | True | {'class': 'org.apache.cassandra.locator.SimpleStrategy', 'replication_factor': '3'}
system | True | {'class': 'org.apache.cassandra.locator.LocalStrategy'}
system_traces | True | {'class': 'org.apache.cassandra.locator.SimpleStrategy', 'replication_factor': '2'}Ukončeme cqlsh a vydáme příkaz nodetool ještě jednou, abychom viděli změnu v clusteru.
nodetool status
Datacenter: datacenter1
=======================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN 45.33.77.49 250.7 KiB 256 100.0% 34689c1e-939c-4bd3-8774-ac4534880744 rack1
UN 45.56.109.42 188.02 KiB 256 100.0% 7542e062-d6d3-473a-b79c-4f5e11547c1f rack1
UN 45.33.69.15 236.58 KiB 256 100.0% 2f10690c-1e6e-4297-bda6-c3fb36279495 rack1Všimněte si, že každý uzel má nyní 100 % dat, zatímco dříve to bylo 66 %. To je kvůli replikačnímu faktoru 3, který jsme nastavili, nyní máme jednu kopii dat na každém uzlu.
Závěr
Takže jsme nastavili cluster Cassandra s replikací. Odtud můžete přidávat další uzly, stojany a datová centra, můžete importovat libovolné množství dat a měnit faktor replikace ve všech nebo některých datových centrech. Způsoby, jak toho dosáhnout, najdete v oficiální dokumentaci Cassandry. Doufám, že vám tato příručka pomohla ponořit se do budoucnosti databázové technologie a že jste se rozhodli věřit Cassandře. Děkuji za přečtení a přeji hezký den.