Grep, neboli Global Regular Expression Print, je extrémně užitečný linuxový příkaz pro hledání odpovídajících vzorů. Dokáže prohlížet soubory a adresáře a také číst vstup z příkazů. Vyhledává pomocí regulárních výrazů nebo regulárních výrazů a tiskne řádky ze souboru, který odpovídá danému vzoru.
V tomto příspěvku se podíváme na to, jak používat příkaz Grep v systému Linux. Zde popsané příkazy byly testovány na Ubuntu 20.04. Stejné příkazy Grep fungují také pro Debian, Mint, Fedora a CentOS.
Instalace příkazu grep
Většina distribucí Linuxu včetně Ubuntu 20.04 LTS je dodávána s nainstalovaným grep. V případě, že váš systém nemá nainstalovaný Grep, můžete jej nainstalovat pomocí níže uvedeného příkazu v Terminálu:
$ Sudo apt-get install grep

Syntaxe příkazu Grep
Základní syntaxe příkazu Grep je následující:
$ grep [options] PATTERN [FILE...]
Použití příkazu Grep
Nalezení slova v souboru
S Grep můžete hledat jakékoli slovo v konkrétním souboru. Syntaxe by byla:
$ grep <word> <filename>
Například níže uvedený příkaz bude hledat slovo „Donuts“ v souboru „Donuts.txt“.
$ grep Donuts Donuts.txt

Nalezení slova ve více souborech
Můžete také vyhledat konkrétní slovo ve více souborech.
$ grep <word> <filename1> < filename2>
Například níže uvedený příkaz vyhledá slovo „Donuts“ v souborech „Donuts.txt“ i „cakes.txt“.
$ grep Donuts Donuts.txt cakes.txt
Ignorování malých a velkých písmen
Grep ve výchozím nastavení provádí vyhledávání rozlišující malá a velká písmena, to znamená, že s „koblihami“ a „koblihami“ zachází odlišně. Pokud znovu spustíme výše uvedený příkaz s „donuts“, tentokrát neuvidíte žádný výstup.
$ grep donuts Donuts.txt

Chcete-li tento případ ignorovat, budete muset přidat „-i ” na váš příkaz takto:
$ grep –i <word> <filename>

Nalezení souboru podle přípony v adresáři
Soubor v konkrétním adresáři můžete také najít podle jeho přípony. Použijte k tomu následující syntaxi:
$ ls ~/<directory> | grep .<file type>
Chcete-li například najít všechny soubory „.jpeg“ ve složce „Downloads“, příkaz by byl:
$ ls ~/Downloads | grep .jpeg

Tisk čar, které neodpovídají vzoru
S Grep můžete také vytisknout čáry, které neodpovídají vašemu vzoru přidáním „-v “ na váš příkaz. Použijte k tomu následující syntaxi:
$ grep -v <word> <filename>
Například následující příkaz vytiskne všechny řádky kromě toho, který obsahuje slovo „Donuts“.

Tisk pouze odpovídající slovo
Ve výchozím nastavení grep vytiskne celý řádek, který obsahuje vzor. Chcete-li vytisknout pouze odpovídající slovo, přidejte „-o ” na váš příkaz.
$ grep -o <word> <filename>
Například následující příkaz vytiskne pouze slovo „Donuts“ namísto tisku celého řádku ze souboru „Donuts.txt“.

Tisk čísla řádku odpovídající vzoru a řádku
Ve výchozím nastavení grep vytiskne celý řádek, který obsahuje vzor. Chcete-li vytisknout číslo řádku i řádek, který obsahuje odpovídající slovo, přidejte „-n ” na váš příkaz.
$ grep -n <word> <filename>
Například následující příkaz vytiskne jak číslo řádku, tak řádek, který obsahuje slovo „Donuts“.
$ grep -n Donuts Donuts.txt

Tisk názvů souborů, které odpovídají vzoru
Chcete-li vytisknout všechny soubory ve vašem aktuálním adresáři, které odpovídají vašemu vzoru, použijte následující syntaxi:
$ grep -l “<word>” *
Například následující příkaz vytiskne všechny soubory, které obsahují slovo „Ahoj“:
$ grep -l “Hello” *

Tisk celého shodného slova
Ve výchozím nastavení grep tiskne všechna slova, která odpovídají vašemu vzoru, i když jsou součástí slova. Podívejte se na obrázek níže.
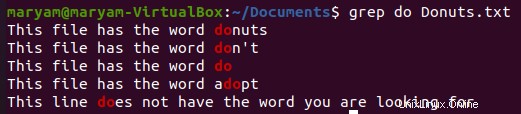
Hledali jsme řetězec „do “ a uvidí všechny řádky, které obsahují „do “. Chcete-li přesně odpovídat slovu, přidejte „-w ” na váš příkaz.
$ grep –w <word> <filename>
Chcete-li například vyhledat přesné slovo „dělat ” v souboru Donuts.txt by příkaz byl:
$ grep -w do Donuts.txt

Jak vidíte, vytiskne nyní pouze řádek, který obsahuje přesné slovo „do “.
Odpovídající řádky, které začínají konkrétním slovem
Chcete-li vytisknout řádky, které začínají konkrétním slovem, přidejte „^ ” na váš příkaz.
$ grep ^<word> <filename>
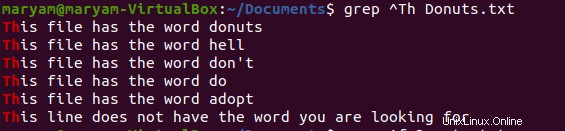
Například následující příkaz vytiskne všechny řádky, které začínají „Th “.
$ grep ^Th Donuts.txt
Odpovídající čáry končící vzorem
Chcete-li vytisknout řádky, které končí konkrétním vzorem, přidejte „$ ” na váš příkaz.
$ grep <word>$ <filename>
Například následující příkaz vytiskne všechny řádky, které končí „t “.
$ grep t$ Donuts.txt

Odpovídající řádky, které obsahují určitá písmena
Pokud chcete hledat řádky, které obsahují jedno nebo více písmen, použijte následující syntaxi:
$ grep “[<letters>]” <filename>
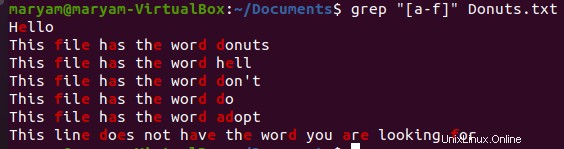
Například následující příkaz vytiskne všechny řádky, které obsahují jakékoli písmeno od „a“ do „f“.
$ grep “[a-f]” Donuts.txt
Rekurzivní vyhledávání
Chcete-li vyhledat všechny soubory v adresáři a podadresáři pro konkrétní vzor nebo slovo, použijte:
$ grep -R <word> <path>
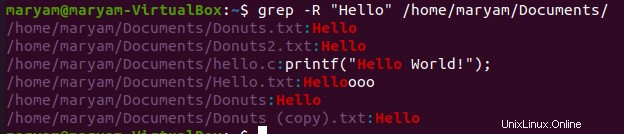
Například následující příkaz zobrazí seznam všech souborů, které obsahují slovo „Ahoj“ v adresáři Dokumenty. V níže uvedeném výstupu můžete vidět cesty k souboru spolu s odpovídajícími slovy.
$ grep -R “Hello” /home/maryam/Documents
Tisk konkrétních řádků před/za odpovídajícími slovy
Ve výchozím nastavení Grep tiskne pouze čáru, která odpovídá konkrétnímu vzoru. S -A možnost v Grep, můžete také vložit několik řádků před nebo za odpovídající slova.
Tisk linek po zápase
Chcete-li vytisknout řádky, které obsahují shodná slova včetně N počet řádků po zápasech:
$ grep -A <N> <word> <filename>
Například následující příkaz vytiskne řádek obsahující slovo „peklo“ spolu s jedním řádkem za ním.
$ grep -A 1 hell Donuts.txt

Tisk linek před zápasem
Chcete-li vytisknout řádky, které obsahují shodná slova včetně N počet řádků před zápasy:
$ grep -B <N> <word> <filename>
Například následující příkaz vytiskne řádek obsahující slovo „peklo“ spolu s 1 řádkem před ním.
$ grep -B 1 hell Donuts.txt

Tisk linek před a po zápase
Chcete-li vytisknout řádky, které obsahují shodná slova včetně N počet řádků před a po zápasech:
$ grep -C <N> <word> <filename>
Například následující příkaz vytiskne řádek obsahující slovo „peklo“ spolu s 1 řádkem před a za ním.
$ grep -C 1 hell Donuts.txt

Počítání počtu shod
Pomocí -c možnost s grep, můžete spočítat řádky, které odpovídají konkrétnímu vzoru. Pamatujte, že bude odpovídat pouze počtu řádků, nikoli počtu odpovídajících slov.
$ grep -c <word> <filename>
Například následující příkaz vytiskne počet řádků, které obsahují slovo „Donuts“.
$ grep -c Donuts Donuts.txt
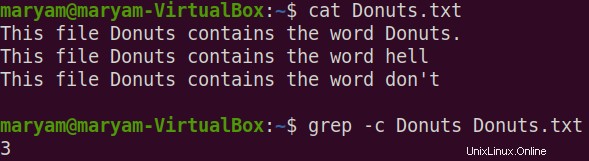
Všimněte si, že náš soubor „Donuts.txt“ obsahuje 4 „Donuts“, ale -c vypsal počet pouze jako 3. Stává se to proto, že místo počtu shod počítá počet řádků.
Pro více informací o grep použijte níže uvedený příkaz:
$ grep --help
nebo navštivte manuálovou stránku pomocí níže uvedeného příkazu:
$ man grep

Tím přejdete na manuálovou stránku Grep.
To je vše, co k tomu patří! V tomto příspěvku jsme vysvětlili základní syntaxi a použití příkazu grep v Linuxu. Také jsme prošli některými možnostmi příkazového řádku, abychom rozšířili jeho užitečnost. Pokud znáte některá další použití příkazu Grep v Linuxu, která nám unikla, rádi bychom se o nich dozvěděli v komentářích níže.
Prozkoumejte tento související článek a zjistěte, jak můžete najít soubory a adresáře v Linuxu.