Zde uvidíme, jak nainstalovat Apache Spark na Ubuntu 20.04 nebo 18.04, příkazy budou použitelné pro Linux Mint, Debian a další podobné systémy Linux.
Apache Spark je univerzální nástroj pro zpracování dat nazývaný engine pro zpracování dat. Používají ji datoví inženýři a datoví vědci k provádění extrémně rychlých datových dotazů na velká množství dat v rozsahu terabajtů. Je to rámec pro výpočty založené na clusteru, který soutěží s klasickou mapou Hadoop / Reduce pomocí paměti RAM dostupné v clusteru pro rychlejší provádění úloh.
Kromě toho Spark také nabízí možnost ovládat data pomocí SQL, zpracovávat je streamováním v (téměř) reálném čase a poskytuje vlastní grafovou databázi a knihovnu strojového učení. Framework pro tento účel nabízí technologie in-memory, tj. může ukládat dotazy a data přímo do hlavní paměti uzlů clusteru.
Apache Spark je ideální pro rychlé zpracování velkého množství dat. Programovací model Sparku je založen na Resilient Distributed Datasets (RDD), třídě kolekce, která funguje distribuovaně v clusteru. Tato platforma s otevřeným zdrojovým kódem podporuje řadu programovacích jazyků, jako je Java, Scala, Python a R.
Kroky pro instalaci Apache Spark na Ubuntu 20.04
Zde uvedené kroky lze použít pro další verze Ubuntu, jako je 21.04/18.04, včetně Linux Mint, Debian a podobných Linuxů.
1. Nainstalujte Javu s dalšími závislostmi
Zde instalujeme nejnovější dostupnou verzi Jave, což je požadavek Apache Spark spolu s některými dalšími věcmi – Git a Scala pro rozšíření jeho schopností.
sudo apt install default-jdk scala git
2. Stáhněte si Apache Spark na Ubuntu 20.04
Nyní navštivte oficiální web Spark a stáhněte si jeho nejnovější dostupnou verzi. Při psaní tohoto návodu však byla nejnovější verze 3.1.2. Zde tedy stahujeme totéž, v případě, že se to liší, když provádíte instalaci Spark na vašem systému Ubuntu, jděte do toho. Jednoduše zkopírujte odkaz ke stažení tohoto nástroje a použijte jej s wget nebo přímo stáhnout do vašeho systému.
wget https://downloads.apache.org/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
3. Extrahujte Spark do /opt
Abychom se ujistili, že extrahovanou složku omylem nesmažeme, umístěte ji na bezpečné místo, tj. /opt adresář.
sudo mkdir /opt/spark
sudo tar -xf spark*.tgz -C /opt/spark --strip-component 1
Změňte také oprávnění složky, aby do ní mohl Spark zapisovat.
sudo chmod -R 777 /opt/spark
4. Přidejte složku Spark do systémové cesty
Nyní, když jsme soubor přesunuli do /opt adresář, pro spuštění příkazu Spark v terminálu musíme pokaždé zmínit celou jeho cestu, což je nepříjemné. Abychom to vyřešili, nakonfigurujeme proměnné prostředí pro Spark přidáním jeho domovských cest do systémového souboru profilu/bashrc. To nám umožňuje spouštět jeho příkazy odkudkoli v terminálu bez ohledu na to, ve kterém adresáři se nacházíme.
echo "export SPARK_HOME=/opt/spark" >> ~/.bashrc echo "export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin" >> ~/.bashrc echo "export PYSPARK_PYTHON=/usr/bin/python3" >> ~/.bashrc
Znovu načíst shell:
source ~/.bashrc
5. Spusťte hlavní server Apache Spark na Ubuntu
Protože jsme již nakonfigurovali proměnné prostředí pro Spark, nyní spustíme jeho samostatný hlavní server spuštěním jeho skriptu:
start-master.sh
Změňte Spark Master Web UI a Listen Port (volitelné, použijte pouze v případě potřeby)
Pokud chcete použít vlastní port, pak to je možné použít, možnosti nebo argumenty uvedené níže.
–port – Port pro službu k naslouchání (výchozí:7077 pro hlavní, náhodný pro pracovníka)
–webui-port – Port pro webové uživatelské rozhraní (výchozí:8080 pro hlavní, 8081 pro pracovníka)
Příklad – Chci spustit Spark webové uživatelské rozhraní na 8082 a nechat jej naslouchat portu 7072, pak příkaz ke spuštění bude vypadat takto:
start-master.sh --port 7072 --webui-port 8082
6. Access Spark Master (spark://Ubuntu:7077) – webové rozhraní
Nyní přistoupíme k webovému rozhraní hlavního serveru Spark, který běží na portu číslo 8080 . Takže ve svém prohlížeči otevřete http://127.0.0.1:8080 .
Náš mistr běží na spark://Ubuntu :7077, kde je Ubuntu je systémový název hostitele a ve vašem případě to může být jiné.
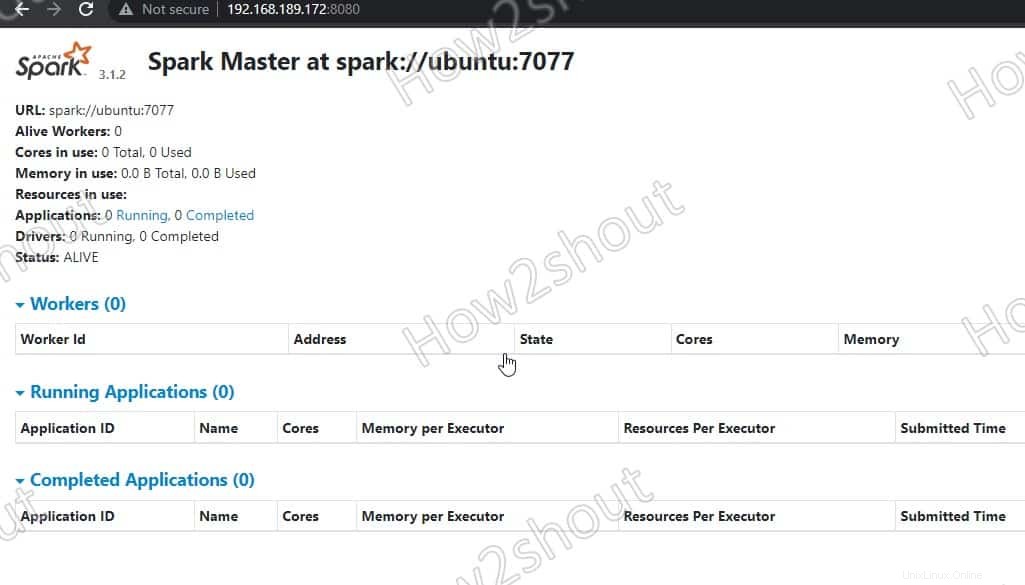
Pokud používáte server CLI a chcete použít prohlížeč jiného systému, který má přístup k IP adrese serveru, otevřete nejprve 8080 ve firewallu. To vám umožní vzdálený přístup k webovému rozhraní Spark na adrese – http://your-server-ip-addres:8080
sudo ufw allow 8080
7. Spusťte Slave Worker Script
Abychom mohli spustit Spark slave worker, musíme spustit jeho skript dostupný v adresáři, který jsme zkopírovali do /opt . Syntaxe příkazu bude:
Syntaxe příkazu:
start-worker.sh spark://hostname:port
Ve výše uvedeném příkazu změňte hostname a port . Pokud neznáte svůj název hostitele, jednoduše zadejte - hostname v terminálu. Kde je výchozí port master běží na 7077, můžete vidět na snímku obrazovky výše .
Protože naše jméno hostitele je ubuntu, příkaz bude vypadat takto:
start-worker.sh spark://ubuntu:7077
Obnovte webové rozhraní a uvidíte ID pracovníka a množství paměti přiděleno:
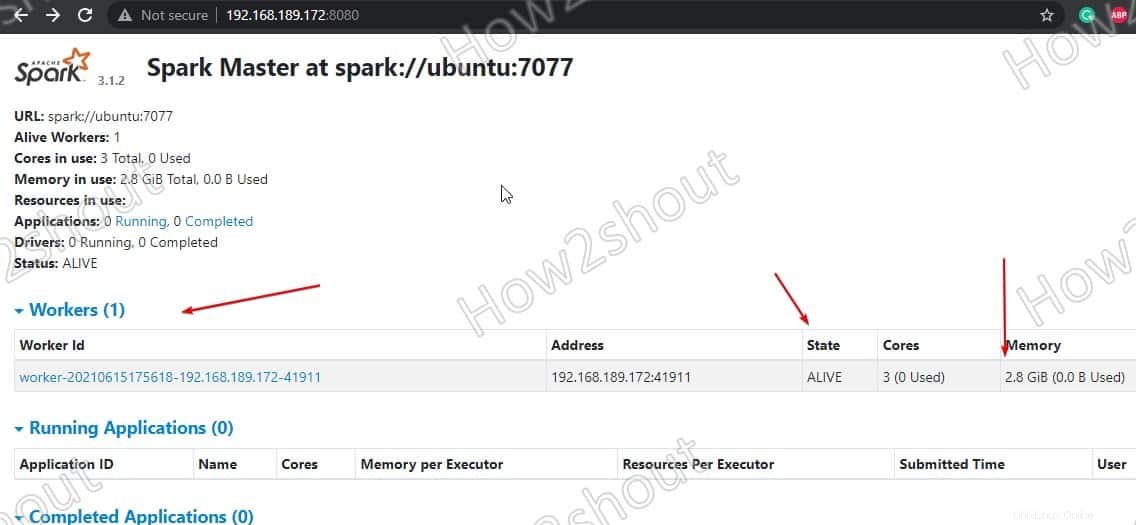
Pokud chcete, můžete změnit paměť/ram přidělenou pracovníkovi. K tomu musíte restartovat pracovníka s množstvím paměti RAM, kterou mu chcete poskytnout.
stop-worker.sh start-worker.sh -m 212M spark://ubuntu:7077
Použijte Spark Shell
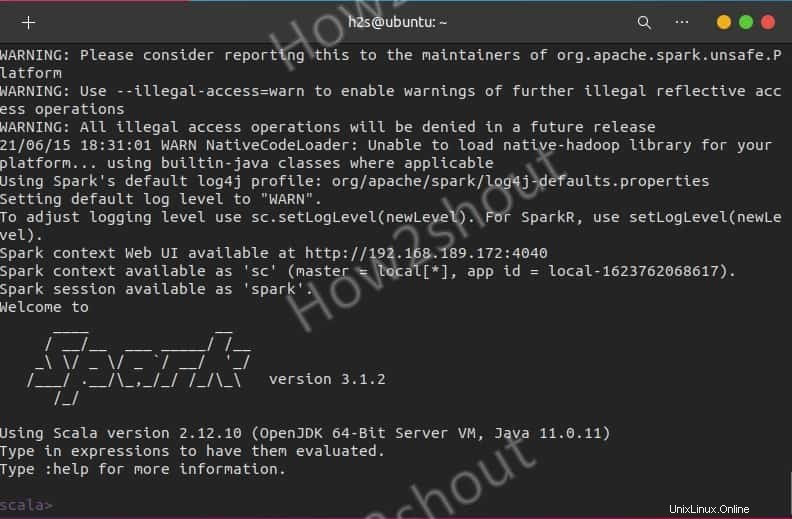
Ti, kteří chtějí použít Spark shell k zahájení programování, k němu mohou přistupovat přímým zadáním:
spark-shell
Chcete-li zobrazit podporované možnosti, zadejte - :help a pro ukončení shellu použijte – :quite
Chcete-li začít s prostředím Python namísto Scala, použijte:
pyspark
Příkazy pro spuštění a zastavení serveru
Pokud chcete spustit nebo zastavit velitele/pracovníky instance, pak použijte odpovídající skripty:
stop-master.sh stop-worker.sh
Chcete-li zastavit všechny najednou
stop-all.sh
Nebo začněte vše najednou:
start-all.sh
Konec myšlenek:
Tímto způsobem můžeme nainstalovat a začít používat Apache Spark na Ubuntu Linux. Další informace o vás naleznete v oficiální dokumentaci . Ve srovnání s Hadoopem je však Spark stále relativně mladý, takže musíte počítat s nějakými drsnými hranami. V praxi se však již mnohokrát osvědčil a umožňuje nové případy použití v oblasti velkých nebo rychlých dat prostřednictvím rychlého provádění úloh a cachování dat. A konečně nabízí jednotné API pro nástroje, které by jinak musely být v prostředí Hadoop provozovány a provozovány samostatně.