Apache Spark je open-source framework a univerzální clusterový výpočetní systém. Spark poskytuje API na vysoké úrovni v Javě, Scale, Pythonu a R, které podporuje obecné grafy provádění. Dodává se s vestavěnými moduly používanými pro streamování, SQL, strojové učení a zpracování grafů. Je schopen analyzovat velké množství dat a distribuovat je napříč clusterem a zpracovávat data paralelně.
V tomto tutoriálu vysvětlíme, jak nainstalovat clusterový výpočetní zásobník Apache Spark na Ubuntu 20.04.
Předpoklady
- Server se serverem Ubuntu 20.04.
- Na serveru je nakonfigurováno heslo uživatele root.
Začínáme
Nejprve budete muset aktualizovat své systémové balíčky na nejnovější verzi. Všechny je můžete aktualizovat pomocí následujícího příkazu:
apt-get update -y
Jakmile jsou všechny balíčky aktualizovány, můžete přejít k dalšímu kroku.
Instalovat Javu
Apache Spark je aplikace založená na Javě. Ve vašem systému tedy musí být nainstalována Java. Můžete jej nainstalovat pomocí následujícího příkazu:
apt-get install default-jdk -y
Jakmile je Java nainstalována, ověřte nainstalovanou verzi Java pomocí následujícího příkazu:
java --version
Měli byste vidět následující výstup:
openjdk 11.0.8 2020-07-14 OpenJDK Runtime Environment (build 11.0.8+10-post-Ubuntu-0ubuntu120.04) OpenJDK 64-Bit Server VM (build 11.0.8+10-post-Ubuntu-0ubuntu120.04, mixed mode, sharing)
Instalovat Scala
Apache Spark je vyvinut pomocí Scala. Takže budete muset nainstalovat Scala do vašeho systému. Můžete jej nainstalovat pomocí následujícího příkazu:
apt-get install scala -y
Po instalaci Scala. Verzi Scala můžete ověřit pomocí následujícího příkazu:
scala -version
Měli byste vidět následující výstup:
Scala code runner version 2.11.12 -- Copyright 2002-2017, LAMP/EPFL
Nyní se připojte k rozhraní Scala pomocí následujícího příkazu:
scala
Měli byste získat následující výstup:
Welcome to Scala 2.11.12 (OpenJDK 64-Bit Server VM, Java 11.0.8). Type in expressions for evaluation. Or try :help.
Nyní otestujte Scala pomocí následujícího příkazu:
scala> println("Hitesh Jethva") Měli byste získat následující výstup:
Hitesh Jethva
Nainstalujte Apache Spark
Nejprve si budete muset stáhnout nejnovější verzi Apache Spark z jeho oficiálních stránek. V době psaní tohoto návodu je nejnovější verze Apache Spark 2.4.6. Můžete si jej stáhnout do adresáře /opt pomocí následujícího příkazu:
cd /opt
wget https://archive.apache.org/dist/spark/spark-2.4.6/spark-2.4.6-bin-hadoop2.7.tgz
Po stažení rozbalte stažený soubor pomocí následujícího příkazu:
tar -xvzf spark-2.4.6-bin-hadoop2.7.tgz
Dále přejmenujte extrahovaný adresář na jiskru, jak je znázorněno níže:
mv spark-2.4.6-bin-hadoop2.7 spark
Dále budete muset nakonfigurovat prostředí Spark, abyste mohli snadno spouštět příkazy Spark. Můžete jej nakonfigurovat úpravou souboru .bashrc:
nano ~/.bashrc
Na konec souboru přidejte následující řádky:
export SPARK_HOME=/opt/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
Uložte a zavřete soubor a poté aktivujte prostředí pomocí následujícího příkazu:
source ~/.bashrc
Spustit Spark Master Server
V tomto okamžiku je Apache Spark nainstalován a nakonfigurován. Nyní spusťte hlavní server Spark pomocí následujícího příkazu:
start-master.sh
Měli byste vidět následující výstup:
starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-ubuntu2004.out
Ve výchozím nastavení Spark naslouchá na portu 8080. Můžete to zkontrolovat pomocí následujícího příkazu:
ss -tpln | grep 8080
Měli byste vidět následující výstup:
LISTEN 0 1 *:8080 *:* users:(("java",pid=4930,fd=249))
Nyní otevřete webový prohlížeč a přejděte do webového rozhraní Spark pomocí adresy URL http://your-server-ip:8080. Měli byste vidět následující obrazovku:
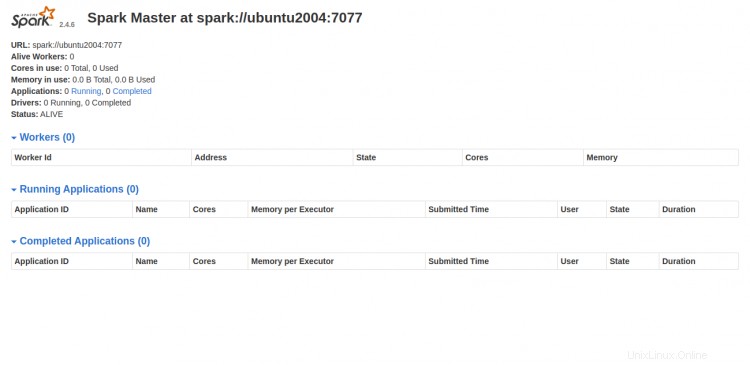
Spustit proces Spark Worker
Jak můžete vidět, služba Spark master běží na spark://your-server-ip:7077. Tuto adresu tedy můžete použít ke spuštění pracovního procesu Spark pomocí následujícího příkazu:
start-slave.sh spark://your-server-ip:7077
Měli byste vidět následující výstup:
starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-ubuntu2004.out
Nyní přejděte na řídicí panel Spark a obnovte obrazovku. Pracovní proces Spark byste měli vidět na následující obrazovce:
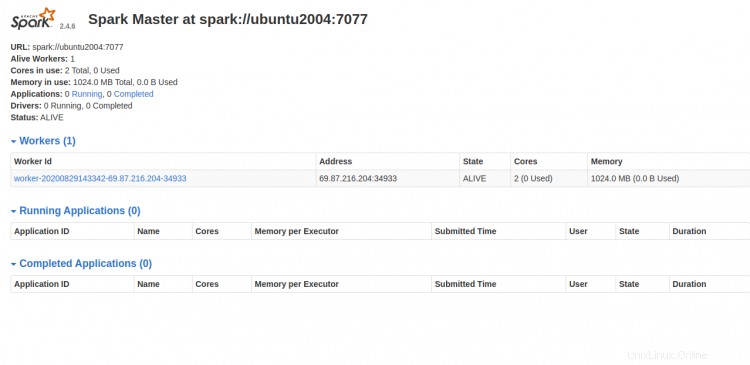
Práce se Spark Shell
Server Spark můžete také připojit pomocí příkazového řádku. Můžete jej připojit pomocí příkazu spark-shell, jak je znázorněno níže:
spark-shell
Po připojení byste měli vidět následující výstup:
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform (file:/opt/spark/jars/spark-unsafe_2.11-2.4.6.jar) to method java.nio.Bits.unaligned()
WARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
20/08/29 14:35:07 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://ubuntu2004:4040
Spark context available as 'sc' (master = local[*], app id = local-1598711719335).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.6
/_/
Using Scala version 2.11.12 (OpenJDK 64-Bit Server VM, Java 11.0.8)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
Pokud chcete používat Python ve Sparku. Můžete použít nástroj příkazového řádku pyspark.
Nejprve nainstalujte Python verze 2 pomocí následujícího příkazu:
apt-get install python -y
Po instalaci můžete Spark připojit pomocí následujícího příkazu:
pyspark
Po připojení byste měli získat následující výstup:
Python 2.7.18rc1 (default, Apr 7 2020, 12:05:55)
[GCC 9.3.0] on linux2
Type "help", "copyright", "credits" or "license" for more information.
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform (file:/opt/spark/jars/spark-unsafe_2.11-2.4.6.jar) to method java.nio.Bits.unaligned()
WARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
20/08/29 14:36:40 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.4.6
/_/
Using Python version 2.7.18rc1 (default, Apr 7 2020 12:05:55)
SparkSession available as 'spark'.
>>>
Pokud chcete zastavit Master a Slave server. Můžete to udělat pomocí následujícího příkazu:
stop-slave.sh
stop-master.sh
Závěr
Gratulujeme! úspěšně jste nainstalovali Apache Spark na server Ubuntu 20.04. Nyní byste měli být schopni provést základní testy, než začnete konfigurovat cluster Spark. Neváhejte se mě zeptat, pokud máte nějaké otázky.