Apache Spark je bezplatný, open source, univerzální a distribuovaný výpočetní rámec, který je vytvořen za účelem poskytování rychlejších výpočetních výsledků. Podporuje několik API pro streamování, zpracování grafů včetně Java, Python, Scala a R. Apache Spark lze obecně použít v clusterech Hadoop, ale můžete jej nainstalovat také v samostatném režimu.
V tomto tutoriálu vám ukážeme, jak nainstalovat framework Apache Spark na Debian 11.
Předpoklady
- Server se systémem Debian 11.
- Na serveru je nakonfigurováno heslo uživatele root.
Instalovat Javu
Apache Spark je napsán v Javě. Ve vašem systému tedy musí být nainstalována Java. Pokud není nainstalován, můžete jej nainstalovat pomocí následujícího příkazu:
apt-get install default-jdk curl -y
Jakmile je Java nainstalována, ověřte verzi Java pomocí následujícího příkazu:
java --version
Měli byste získat následující výstup:
openjdk 11.0.12 2021-07-20 OpenJDK Runtime Environment (build 11.0.12+7-post-Debian-2) OpenJDK 64-Bit Server VM (build 11.0.12+7-post-Debian-2, mixed mode, sharing)
Nainstalujte Apache Spark
V době psaní tohoto návodu je nejnovější verze Apache Spark 3.1.2. Můžete si jej stáhnout pomocí následujícího příkazu:
wget https://dlcdn.apache.org/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
Po dokončení stahování rozbalte stažený soubor pomocí následujícího příkazu:
tar -xvzf spark-3.1.2-bin-hadoop3.2.tgz
Dále přesuňte extrahovaný adresář do /opt pomocí následujícího příkazu:
mv spark-3.1.2-bin-hadoop3.2/ /opt/spark
Dále upravte soubor ~/.bashrc a přidejte proměnnou Spark path:
nano ~/.bashrc
Přidejte následující řádky:
export SPARK_HOME=/opt/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
Uložte a zavřete soubor a poté aktivujte proměnnou prostředí Spark pomocí následujícího příkazu:
source ~/.bashrc
Spustit Apache Spark
Nyní můžete spustit následující příkaz ke spuštění služby Spark master:
start-master.sh
Měli byste získat následující výstup:
starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-debian11.out
Ve výchozím nastavení Apache Spark naslouchá na portu 8080. Můžete to ověřit pomocí následujícího příkazu:
ss -tunelp | grep 8080
Získáte následující výstup:
tcp LISTEN 0 1 *:8080 *:* users:(("java",pid=24356,fd=296)) ino:47523 sk:b cgroup:/user.slice/user-0.slice/session-1.scope v6only:0 <->
Dále spusťte pracovní proces Apache Spark pomocí následujícího příkazu:
start-slave.sh spark://your-server-ip:7077
Přístup k webovému uživatelskému rozhraní Apache Spark
Nyní máte přístup k webovému rozhraní Apache Spark pomocí adresy URL http://ip-ip-vašeho-serveru:8080 . Na následující obrazovce byste měli vidět hlavní a podřízenou službu Apache Spark:
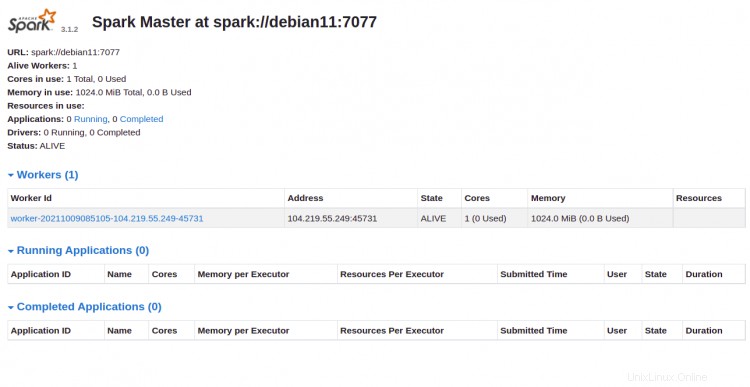
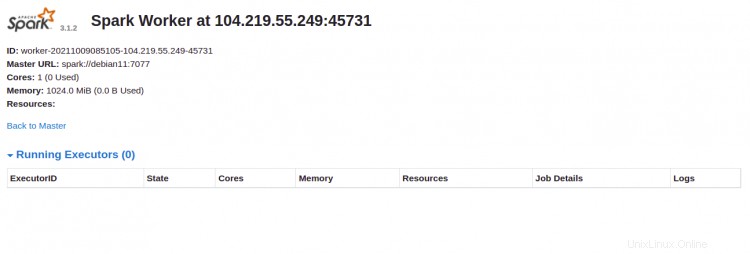
Klikněte na Pracovník id. Na následující obrazovce byste měli vidět podrobné informace o vašem pracovníkovi:
Připojit Apache Spark pomocí příkazového řádku
Pokud se chcete ke Sparku připojit přes jeho příkazový shell, spusťte níže uvedené příkazy:
spark-shell
Jakmile se připojíte, získáte následující rozhraní:
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Scala version 2.12.10 (OpenJDK 64-Bit Server VM, Java 11.0.12)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
Pokud chcete používat Python ve Sparku. Můžete použít nástroj příkazového řádku pyspark.
Nejprve nainstalujte Python verze 2 pomocí následujícího příkazu:
apt-get install python -y
Po instalaci můžete Spark připojit pomocí následujícího příkazu:
pyspark
Po připojení byste měli získat následující výstup:
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Python version 3.9.2 (default, Feb 28 2021 17:03:44)
Spark context Web UI available at http://debian11:4040
Spark context available as 'sc' (master = local[*], app id = local-1633769632964).
SparkSession available as 'spark'.
>>>
Zastavit Master a Slave
Nejprve zastavte podřízený proces pomocí následujícího příkazu:
stop-slave.sh
Získáte následující výstup:
stopping org.apache.spark.deploy.worker.Worker
Dále zastavte hlavní proces pomocí následujícího příkazu:
stop-master.sh
Získáte následující výstup:
stopping org.apache.spark.deploy.master.Master
Závěr
Gratulujeme! úspěšně jste nainstalovali Apache Spark na Debian 11. Nyní můžete Apache Spark ve své organizaci používat ke zpracování velkých datových sad