
V tomto tutoriálu vám ukážeme, jak nainstalovat Apache Spark na Debian 10. Pro ty z vás, kteří nevěděli, Apache Spark je rychlý a univerzální clusterový výpočetní systém. Poskytuje rozhraní API na vysoké úrovni v jazycích Java, Scala a Python a také optimalizovaný engine, který podporuje celkové grafy provádění. Podporuje také bohatou sadu nástrojů vyšší úrovně včetně Spark SQL pro SQL a zpracování strukturovaných informací, MLlib pro strojové učení , GraphX pro zpracování grafů a Spark Streaming.
Tento článek předpokládá, že máte alespoň základní znalosti Linuxu, víte, jak používat shell, a co je nejdůležitější, hostujete svůj web na vlastním VPS. Instalace je poměrně jednoduchá a předpokládá, že běží v účtu root, pokud ne, možná budete muset přidat 'sudo ‘ k příkazům pro získání oprávnění root. Ukážu vám krok za krokem instalaci Apache Spark na Debian 10 (Buster).
Předpoklady
- Server s jedním z následujících operačních systémů:Debian 10 (Buster).
- Abyste předešli případným problémům, doporučujeme použít novou instalaci operačního systému.
non-root sudo usernebo přístup kroot user. Doporučujeme jednat jakonon-root sudo user, protože však můžete poškodit svůj systém, pokud nebudete při jednání jako root opatrní.
Nainstalujte Apache Spark na Debian 10 Buster
Krok 1. Než spustíte výukový program níže, je důležité se ujistit, že váš systém je aktuální, a to spuštěním následujícího apt příkazy v terminálu:
sudo apt update
Krok 2. Instalace Java.
Apache Spark vyžaduje ke svému běhu Javu, ujistěte se, že máme Javu nainstalovanou v našem systému Debian:
sudo apt install default-jdk
Ověřte verzi Java pomocí příkazu:
java -version
Krok 3. Instalace Scala.
Nyní nainstalujeme balíček Scala na systémy Debian:
sudo apt install scala
Zkontrolujte verzi Scala:
scala -version
Krok 4. Instalace Apache Spark na Debian.
Nyní si můžeme stáhnout binární soubor Apache Spark:
wget https://www.apache.org/dyn/closer.lua/spark/spark-3.1.1/spark-3.1.1-bin-hadoop2.7.tgz
Dále extrahujte tarball Spark:
tar xvf spark-3.1.1-bin-hadoop2.7.tgz sudo mv spark-3.1.1-bin-hadoop2.7/ /opt/spark
Po dokončení nastavte prostředí Spark:
nano ~/.bashrc
Na konec souboru přidejte následující řádky:
export SPARK_HOME=/opt/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
Uložte změny a zavřete editor. Chcete-li změny použít, spusťte:
source ~/.bashrc
Nyní spusťte Apache Spark pomocí těchto příkazů, z nichž jeden je hlavním nástrojem clusteru:
start-master.sh
Chcete-li zobrazit uživatelské rozhraní Spark Web, jak vypadá níže, otevřete webový prohlížeč a zadejte IP adresu localhost na portu 8080:
http://127.0.0.1:8080/
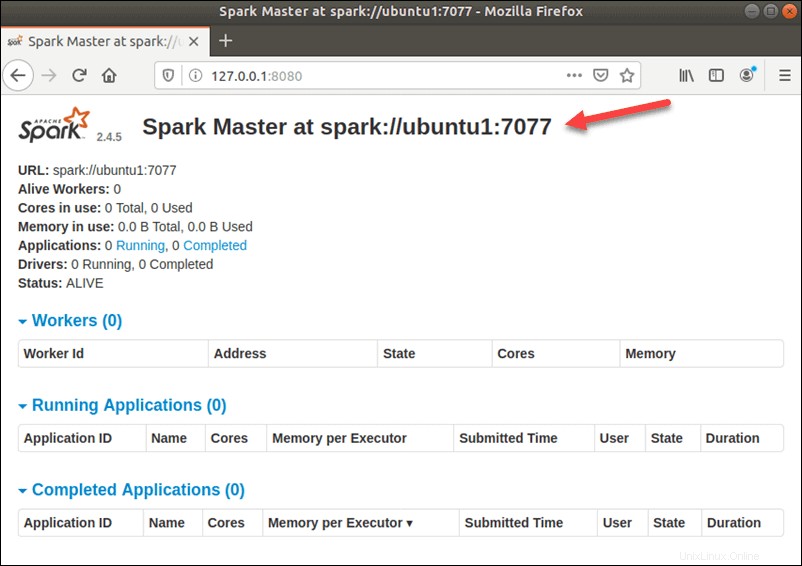
V tomto samostatném nastavení s jedním serverem spustíme jeden podřízený server spolu s hlavním serverem. start-slave.sh příkaz se používá ke spuštění procesu Spark Worker:
start-slave.sh spark://ubuntu1:7077
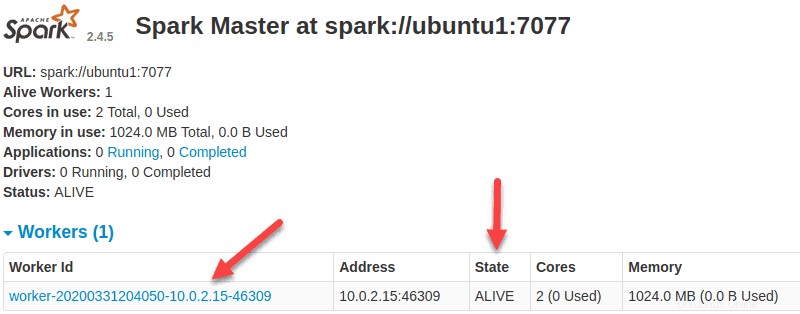
Nyní, když je pracovník spuštěn, a pokud znovu načtete webové uživatelské rozhraní Spark Master, měli byste jej vidět v seznamu:
Po dokončení konfigurace spusťte hlavní a podřízený server a otestujte, zda funguje shell Spark:
spark-shell
Blahopřejeme! Úspěšně jste nainstalovali Spark. Děkujeme, že jste použili tento návod k instalaci nejnovější verze Apache Spark na systém Debian. Pro další nápovědu nebo užitečné informace doporučujeme navštívit oficiální Apache Web Spark.