
V tomto tutoriálu vám ukážeme, jak nainstalovat Apache Spark na Debian 11. Pro ty z vás, kteří nevěděli, Apache Spark je bezplatný, open source, univerzální framework pro clustered computing. Je speciálně navržen pro rychlost a používá se ve strojovém učení ke streamování zpracování složitých SQL dotazů. Podporuje několik rozhraní API pro streamování, zpracování grafů včetně Java, Python, Scala a R. Spark je většinou nainstalován v Hadoop clustery, ale můžete také nainstalovat a nakonfigurovat spark v samostatném režimu.
Tento článek předpokládá, že máte alespoň základní znalosti Linuxu, víte, jak používat shell, a co je nejdůležitější, hostujete svůj web na vlastním VPS. Instalace je poměrně jednoduchá a předpokládá, že běží v účtu root, pokud ne, možná budete muset přidat 'sudo ‘ k příkazům pro získání oprávnění root. Ukážu vám krok za krokem instalaci Apache Spark na Debian 11 (Bullseye).
Předpoklady
- Server s jedním z následujících operačních systémů:Debian 11 (Bullseye).
- Abyste předešli případným problémům, doporučujeme použít novou instalaci operačního systému.
non-root sudo usernebo přístup kroot user. Doporučujeme jednat jakonon-root sudo user, protože však můžete poškodit svůj systém, pokud nebudete při jednání jako root opatrní.
Nainstalujte Apache Spark na Debian 11 Bullseye
Krok 1. Než nainstalujeme jakýkoli software, je důležité se ujistit, že váš systém je aktuální spuštěním následujícího apt příkazy v terminálu:
sudo apt update sudo apt upgrade
Krok 2. Instalace Java.
Spuštěním následujícího příkazu nainstalujte Javu a další závislosti:
sudo apt install default-jdk scala git
Ověřte instalaci Java pomocí příkazu:
java --version
Krok 3. Instalace Apache Spark na Debian 11.
Nyní stahujeme nejnovější verzi Apache Spark z oficiální stránky pomocí wget příkaz:
wget https://dlcdn.apache.org/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
Dále rozbalte stažený soubor:
tar -xvzf spark-3.1.2-bin-hadoop3.2.tgz mv spark-3.1.2-bin-hadoop3.2/ /opt/spark
Poté upravte ~/.bashrc a přidejte proměnnou Spark path:
nano ~/.bashrc
Přidejte následující řádek:
export SPARK_HOME=/opt/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
Uložte a zavřete soubor a poté aktivujte proměnnou prostředí Spark pomocí následujícího příkazu:
source ~/.bashrc
Krok 3. Spusťte Apache Spark Master Server.
V tuto chvíli je nainstalován Apache spark. Nyní spustíme jeho samostatný hlavní server spuštěním jeho skriptu:
start-master.sh
Ve výchozím nastavení Apache Spark naslouchá na portu 8080. Můžete to zkontrolovat pomocí následujícího příkazu:
ss -tunelp | grep 8080
Krok 4. Přístup k webovému rozhraní Apache Spark.
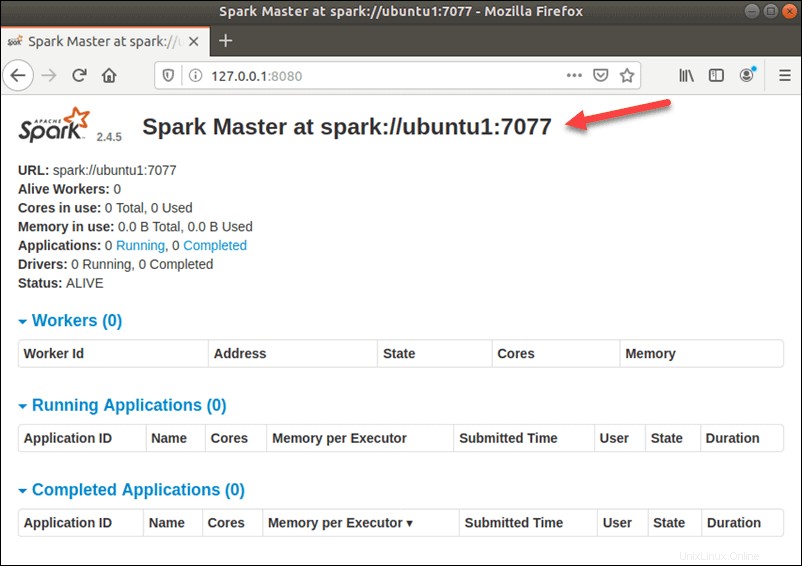
Po úspěšné konfiguraci nyní přejděte k webovému rozhraní Apache Spark pomocí adresy URL http://your-server-ip-address:8080 . Na následující obrazovce byste měli vidět hlavní a podřízenou službu Apache Spark:
V tomto samostatném nastavení s jedním serverem spustíme jeden podřízený server spolu s hlavním serverem. start-slave.sh příkaz se používá ke spuštění procesu Spark Worker:
start-slave.sh spark://ubuntu1:7077
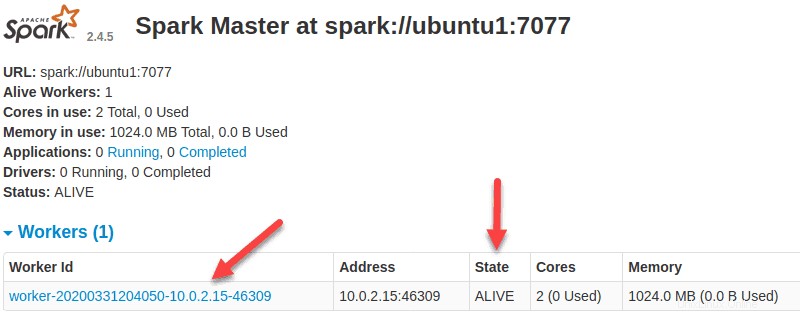
Nyní, když je pracovník spuštěn, a pokud znovu načtete webové uživatelské rozhraní Spark Master, měli byste jej vidět v seznamu:
Po dokončení konfigurace spusťte hlavní a podřízený server a otestujte, zda funguje shell Spark:
spark-shell
Získáte následující rozhraní:
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Scala version 2.12.10 (OpenJDK 64-Bit Server VM, Java 11.0.12)
Type in expressions to have them evaluated.
Type :help for more information.
scala> Blahopřejeme! Úspěšně jste nainstalovali Apache Spark. Děkujeme, že jste použili tento návod k instalaci nejnovější verze Apache Spark na Debian 11 Bullseye. Pro další pomoc nebo užitečné informace vám doporučujeme navštívit oficiální Web Apache Spark.